Transformer入门-轨迹预测实例解析_transformer轨迹预测-程序员宅基地
技术标签: 深度学习 transformer 人工智能
最近动手玩了一下Transformer,找到了一个很适合练手的小例子,基于https://github.com/cxl-ustb/AISTransforemr的代码做了一些修改(感谢原作者),改进后的代码地址:GitHub - BITcsy/AISTransformer: 利用transformer进行船舶轨迹预测。
1. 任务简介:
该代码功能是处理船只的轨迹、状态预测(经度,维度,速度,朝向)。每条数据涵盖11个点,输入是完整的11个点(Encoder输入前10个点,Decoder输入后10个点,模型整体输出后10个点),如下图,训练数据140条,测试数据160条。整个任务本身并没有什么意义(已知轨迹再输出部分轨迹),并没有做什么预测任务。不过整体例子简单明了,调试难度小,比较适合做入门练手的例子。

2. 模型结构:
原作者实现了比较完整的Transformer结构,当然对于轨迹预测类任务很多结构是冗余的,因为Decoder那部分输入在语音识别上可能有用,但是在轨迹预测上应该没有必要,不过可以学习一下。
(1)Transformer参考资料
这网上很多,这里引用几个个人觉得比较好的:
Transformer: NLP里的变形金刚 --- 详述 - 知乎
多图详解attention和mask。从循环神经网络、transformer到GPT2,我悟了 - 知乎
(2)本文模型结构及主要变量的对应图
费劲把这个代码里的整体数据流和主要的模型结构整理了下,可以看出来和最典型的Transformer的结构是一样的。其中标颜色的几个模块单独再打开来看吧,左下角的几个变量和word embedding及positional encoding相关,也单独来看。
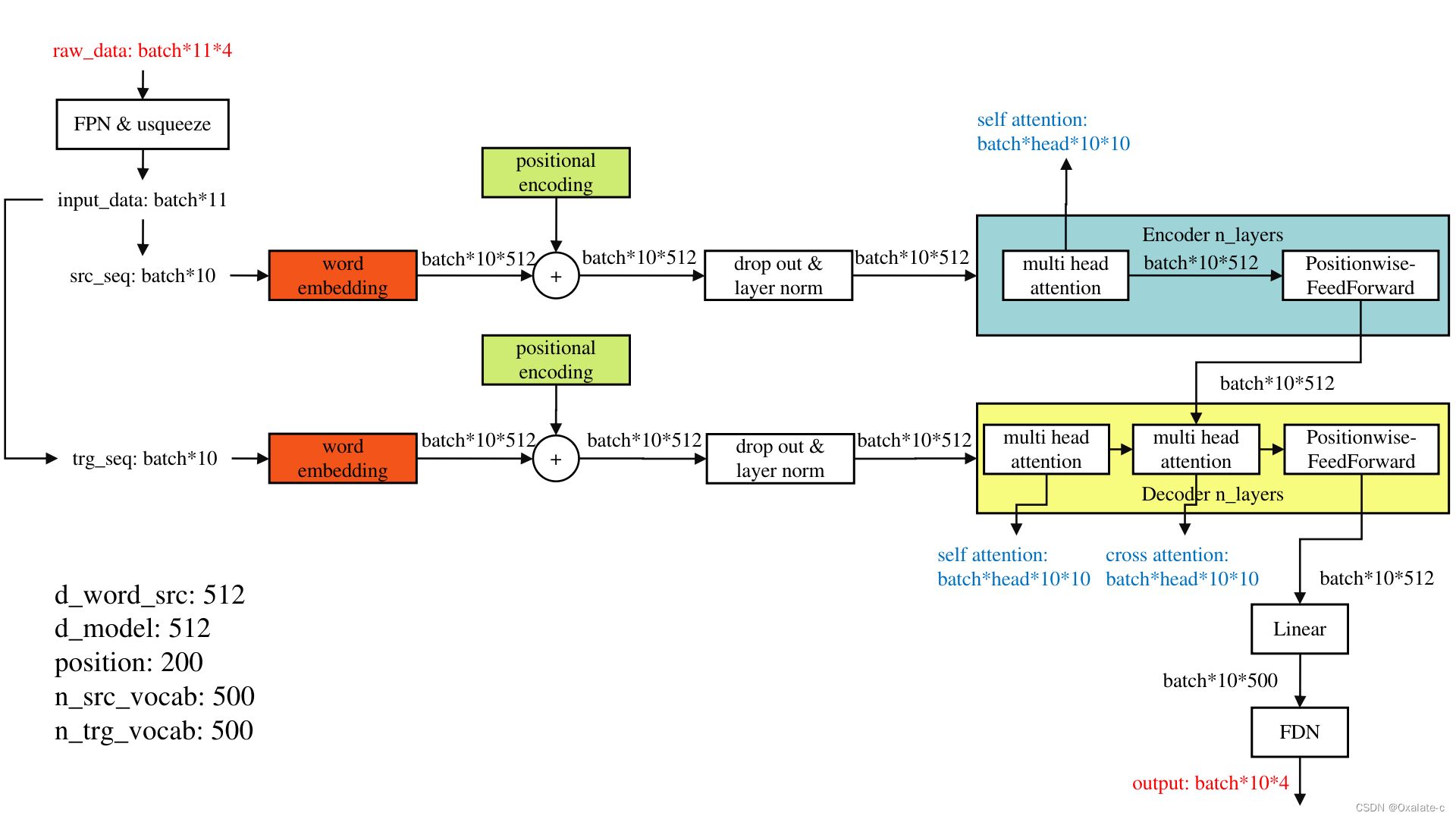
(3)word embedding & positional encoding
word embedding参考资料:词嵌入向量(Word Embedding)的原理和生成方法 - 程序员大本营
nn.embedding: PyTorch中的nn.Embedding - 知乎
positional encoding: positional encoding位置编码详解:绝对位置与相对位置编码对比_夕小瑶的博客-程序员宅基地
Positional Encoding的原理和计算 - 知乎 有比较形象的图形解释。
总之,word embedding想要对序列化的输入(比如一句话,或者这里的一条轨迹)进行降维表达,把input映射成embedding。疑点1:nn.embedding这个模块貌似比较适合NLP任务这种比较稀疏的embedding表达,做轨迹类任务不一定合适。那代码中的n_src_vocab, n_trg_vocab应该就是对应于字典的长度,d_word_src, d_model应该就是隐层要用多少维去表达这些词。疑点2:按道理d_word_src应该小于n_src_vocab才对,但是代码里分别设置了512和500。
positional encoding的作用是为了解决attention这种并行计算的结构丢失了RNN、LSTM这种具有先后顺序的网络特性,因为NLP或者轨迹预测类任务还是需要看特征的时序上的改变的,因此用positional encoding来区分不同的位置,结合其公式应该比较容易理解。代码中position设置为200,按道理这个数设置为大于最大序列长度的数就可以了(本代码最大序列长度就是10)。

word embedding和positional encoding这块的整体计算原理大概如下图,在这个代码里,d_word和d_model其实是一个意思,但是如果是其他场景,d_model的含义应该更广,毕竟是dimension of the model。

(4)注意力部分代码详解
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q
# Pass through the pre-attention projection: b x lq x (n*dv)
# Separate different heads: b x lq x n x dv
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
q += residual
q = self.layer_norm(q)
return q, attn根据上面的代码,画了一下attention详细的计算过程,如下图:
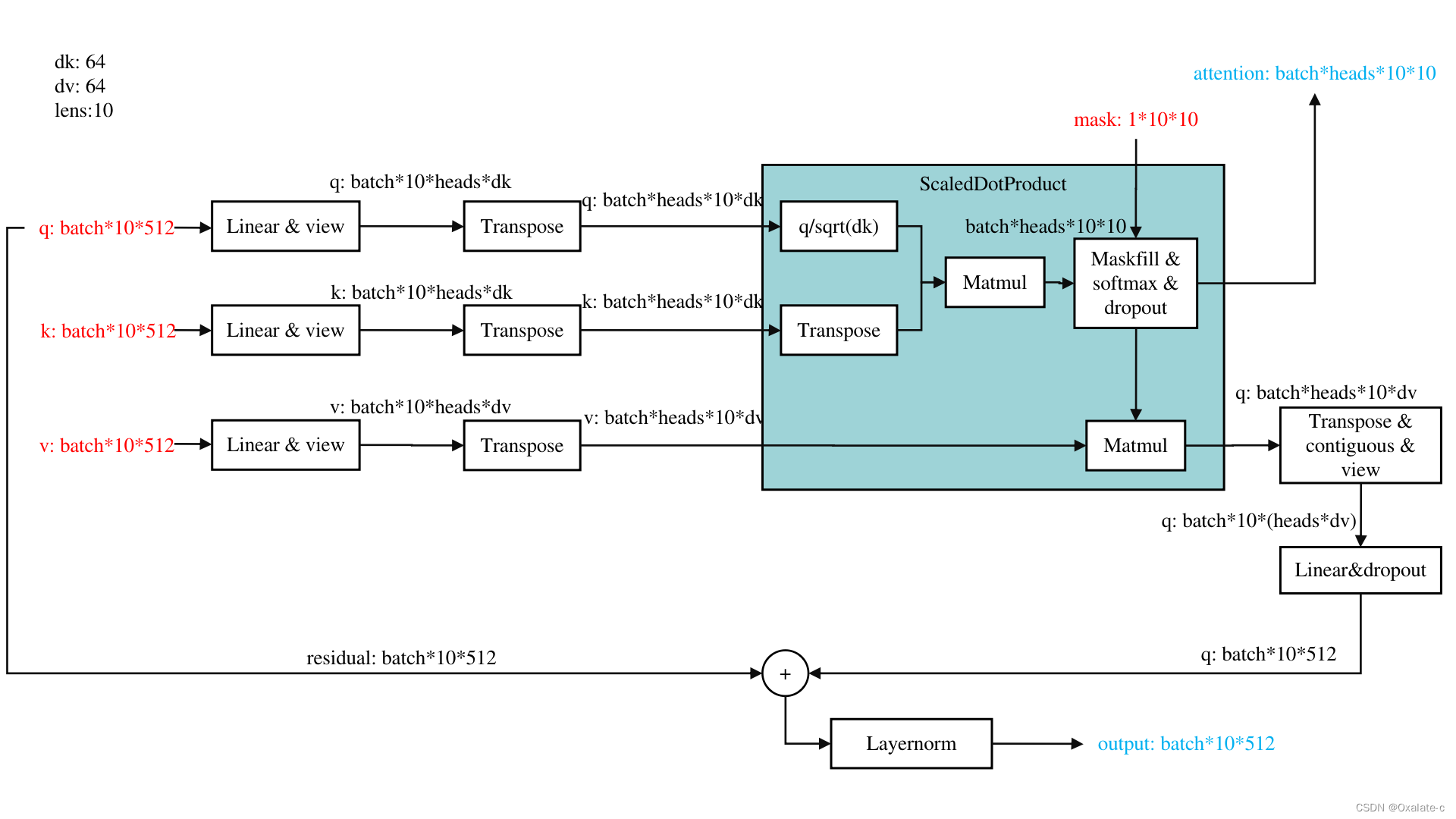
几个需要注意的地方
(1)attention的mask是可选的,在时序任务里是需要的,因为时序是有因果性的。
(2)Q*K才是attention,它的维度是Batch*heads*lens*lens,也就意味着是有明确物理意义的,只和最初的序列长度有关系,可以可视化出来做分析用。
(3)ScaledDotProduct算完后,最后一维是由dv决定的,想回到q的维度,还需要做linear的操作。
(4)contiguous & view:代码里的操作实际就是把dv数据按照heads concate到了一起,具体为何需要使用contiguous的原因PyTorch中的contiguous - 知乎,其实可以用reshape来代替 PyTorch:view() 与 reshape() 区别详解_reshape和view_地球被支点撬走啦的博客-程序员宅基地。
(5)residual:类似于Resnet的设计。
3. 增加的功能:
(1)DataLoader:原代码直接用的pickle来的raw data,为了更好的进行训练控制,我改写成了Dataloader的形式,实测同参数训练要比原来慢1/10到1/5左右。
(2)tqdm:给训练加了个进度条,方便监测比较细节的训练进度。
(3)tensorboard:方便调试(tensorboardX和tensorboard都要安装,tensorboard --logdir XXX)。
(4)模型断点训练:因为自己电脑是10年前的机器,性能很差,所以增加了一个断点续训的功能,避免每次都要从头训练。这里是用checkpoint形式写的保存细节信息。
(5)pt2onxx.py里面用netron可以查看网络结构,略改了一下,可以实现,不过感觉netron显示的太细节,比较难看出最主要的网络设计。
4. 调试笔记
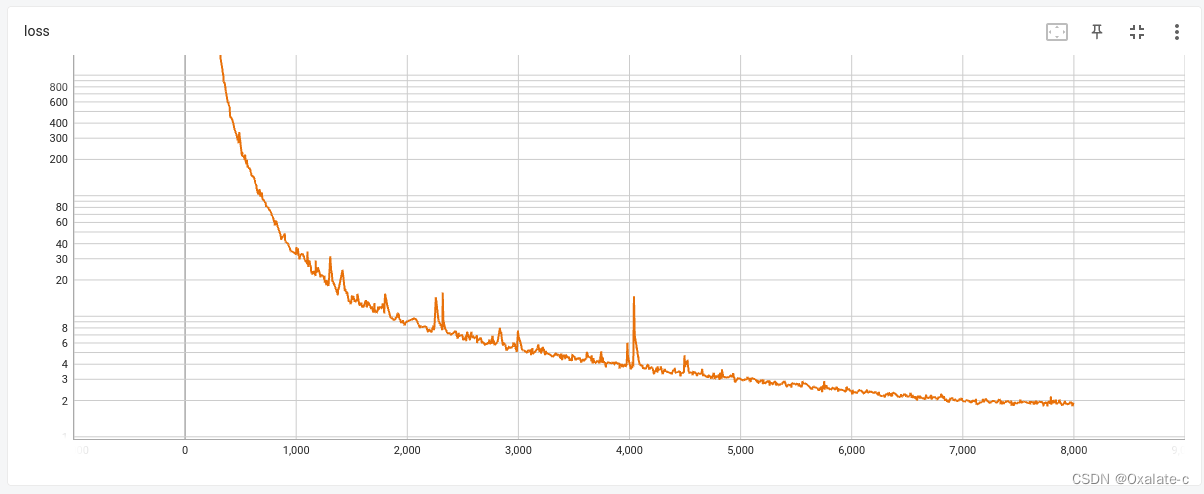
(1)learning rate & 模型大小:原代码直接拿过来可以训,但是收敛不了,loss一直是好几千。分析出来2个主要问题:
i. 原learning rate做了特殊设计,但是用tessorboard看,原learning rate是随训练次数上升的,很令人困惑,所以改写逐步下降的形式。
ii. 改了learning rate还是收敛不了的,分析到训练数据只有140条,但是又搞了个这么大的模型,可能根本喂不饱网络,所以直接把attention部分的大小改小了,multiheadattention的head数8->2,attention layer数6->1,这样改完网络收敛了,至少在训练集上可以过拟合,loss到1左右。
(2)模型保存
关于模型保存,有一类需求,就是本地需要load一个已有的模型pth文件,然后接着训练调试。有一个很奇怪的地方,当我load一个已存的pth文件后,模型做forward的时候,凭什么知道找我源码里同名model的forward函数?我尝试改了一下模型的类名(把Transformer改成了Transformers),果然test的时候就报错了,所以在load模型后,会自动找同名模型的实现:
return super().find_class(mod_name, name)
AttributeError: Can't get attribute 'Transformer' on <module 'transformer.Models' from '/home/XXX/AISTransformer/AISTransformer/transformer/Models.py'>(3)训练集表现 & 关于model.eval的问题
在测试的过程中发现了一个很奇怪的现象,就是如果我把训好的模型save后,再重新load上来,用训练集做测试,loss差距很大(训练的loss是1.x,但是重新load的模型在同数据集下loss是1000+),做了几个尝试
- droptout & 随机种子:有些资料显示,因为用了dropout,但是如果随机种子没有指定的话,训练和测试阶段如果随机数不同,可能会导致差距。https://blog.csdn.net/weixin_38314865/article/details/103019097 手动指定随机种子后,问题未解决,同数据集test和train还是差距很大。
- model.eval():还有些资料说是model.eval()位置不对,感觉应该不是,直接去掉model.eval()的代码后,这个问题就没有了(原代码中也没有model.eval()函数,但是为什么?目前解释不了,todo。是不是和数据归一化有关?把数据里的归一化干掉了,会有很不好的影响吗?)pytorch模型加载跑测试集和训练过程中跑测试集结果不一致的问题?_pytorch加载模型结果不对_心之所向521的博客-程序员宅基地为什么使用model.eval后的模型在训练集上的效果也很差? - 知乎 探究pytorch model.eval()测试效果远差于model.train()_pytorch model.val()和model.train()结果差距太大_Coding-Prince的博客-程序员宅基地
(4)attention & 测试集表现
在训练集上loss约为1,在测试集上测试loss是2k-3k,泛化能力很差,当然数据太少是一个比较显著的问题。为了在小数据集上提升模型泛化能力,可以通过attention来加入一些先验信息引导模型训练。可能的尝试:
- 分析attention:这个轨迹预测的任务,因为直接拷贝trg_seq就可以了,所以对于decoder部分的self attention应该有非常明显的对应位的attention的结果,(encoder的self att和deocder的cross att不一定有这种结果,因为可能的关系已经比较间接了)
- attention mask:用mask的方式约束训练
- attention loss(guide attention):用loss的方式引导训练
(5)Shuffle的问题:因为发现测试集上表现不好,考虑到原代码训练时并没有shuffle,可能会让网络学到一些关于顺序的东西(https://zhuanlan.zhihu.com/p/57108650),所以在引入Dataloader,加了下shuffle,但是训出来感觉测试集上差别不大。
(6)结构对比:做这个简单的任务用这么复杂的模型可能往往是难以达到较好的效果的,还有用了例如word embedding这样的结构,看上去比较奇怪。用MLP简单实现了下这个网络。
- 直接实现了一个4层的MLP:各层维度4,25,50,25,4,输入只用transformer的encoder部分的10*4的输入,因为网络比较小,训练速度会提高很多,30000epochs 2min训练完,但是训练是比较难收敛的,30000epochs的train loss仍然在550+,但是test的error也是550左右。在此感谢@追梦5号的建议,预测轨迹的时序信息才是核心信息,所以各层维度调整为10,25,50,25,10,效果要比之前好。
- 如果和transformer一样,把11个坐标点分成两段输入,那train loss直接0.01(当然这个任务也没什么意义),test error 0.03。
- 所以几个个模型结构对比下,在本例子给的任务下,如果MLP模型和transformer同样的输入,小MLP网络的收敛性和泛化性要比transformer好很多,合理。
-
输入 epochs 训练时长 train loss test loss transformer 1. traj[:,:-1,:]
2. traj[:,1:,:]
8000 >1h@cpu(11min@GTX1080) 1.0+ 2k+ MLP traj[:,-1:,:] 30000 2min 550+ 550+ MLP traj[:,:,-1:] 30000 2min 20+ 20+ MLP 1. traj[:,:-1,:]
2. traj[:,1:,:]
30000 2min 0.01 0.03
智能推荐
QT设置QLabel中字体的颜色_qolable 字体颜色-程序员宅基地
文章浏览阅读8k次,点赞2次,收藏6次。QT设置QLabel中字体的颜色其实,这是一个比较常见的问题。大致有几种做法:一是使用setPalette()方法;二是使用样式表;三是可以使用QStyle;四是可以在其中使用一些简单的HTML样式。下面就具体说一下,也算是个总结吧。第一种,使用setPalette()方法如下:QLabel *label = new QLabel(tr("Hello Qt!"));QP_qolable 字体颜色
【C#】: Import “google/protobuf/timestamp.proto“ was not found or had errors.问题彻底被解决!_import "google/protobuf/timestamp.proto" was not f-程序员宅基地
文章浏览阅读3.7k次。使用C# 作为开发语言,将pb文件转换为cs文件的时候相信很多人都会遇到一个很棘手的问题,那就是protoc3环境下,import Timestamp的问题,在头部 import “google/protobuf/timestamp.proto”;的时候会抛异常:google/protobuf/timestamp.proto" was not found or had errors;解决办法【博主「pamxy」的原创文章的分享】:(注:之后才发现,不需要添加这个目录也可以,因为timestamp.p_import "google/protobuf/timestamp.proto" was not found or had errors.
安卓抓取JD wskey + 添加脚本自动转换JD cookie_jd_wsck-程序员宅基地
文章浏览阅读4.1w次,点赞9次,收藏98次。一、准备工具: 1. app:VNET(抓包用)、京东; 安卓手机需要下载VNET软件。下载官网:https://www.vnet-tech.com/zh/ 2. 已安装部署好的青龙面板;二、抓包wskey: 1. 打开已下载的VNET软件,第一步先安装CA证书; 点击右下角三角形按钮(开始抓包按钮),会提示安装证书,点击确定即可,app就会将CA证书下载至手机里,随后在手机设置里进行安装,这里不同手机可能安装位置不同,具体..._jd_wsck
Mybatis-Plus自动填充失效问题:当字段不为空时无法插入_mybatisplus插入不放为空的字段-程序员宅基地
文章浏览阅读2.9k次,点赞7次,收藏3次。本文针对mybatis-plus自动填充第一次更新能正常填充,第二次更新无法自动填充问题。????mybatis-plus自动填充:当要填充的字段不为空时,填充无效问题的解决????先上一副官方的图:取自官方:https://mp.baomidou.com/guide/auto-fill-metainfo.html第三条注意事项为自动填充失效原因:MetaObjectHandler提供的默认方法的策略均为:如果属性有值则不覆盖,如果填充值为null则不填充以官方案例为例:```java_mybatisplus插入不放为空的字段
Matlab 生成exe执行文件_matlab exe-程序员宅基地
文章浏览阅读1w次,点赞25次,收藏94次。利用 Application Complier 完成MATLAB转exe文件_matlab exe
Android下集成Paypal支付-程序员宅基地
文章浏览阅读137次。近期项目需要研究paypal支付,官网上的指导写的过于复杂,可能是老外的思维和中国人不一样吧。难得是发现下面这篇文章:http://www.androidhive.info/2015/02/Android-integrating-paypal-using-PHP-MySQL-part-1/在这篇文章的基础上,查看SDK简化了代码,给出下面这个例子,..._paypal支付集成到anroid应用中
随便推点
MIT-BEVFusion系列五--Nuscenes数据集详细介绍,有下载好的图片_nuscense数据集-程序员宅基地
文章浏览阅读2.3k次,点赞29次,收藏52次。nuScenes 数据集 (pronounced /nu:ːsiː:nz/) 是由 Motional (以前称为 nuTonomy) 团队开发的自动驾驶公共大型数据集。nuScenes 数据集的灵感来自于开创性的 KITTI 数据集。nuScenes 是第一个提供自动驾驶车辆整个传感器套件 (6 个摄像头、1 个 LIDAR、5 个 RADAR、GPS、IMU) 数据的大型数据集。与 KITTI 相比,nuScenes 包含的对象注释多了 7 倍。_nuscense数据集
python mqtt publish_Python Paho MQTT:无法立即在函数中发布-程序员宅基地
文章浏览阅读535次。我正在实现一个程序,该程序可以侦听特定主题,并在ESP8266发布新消息时对此做出反应.从ESP8266收到新消息时,我的程序将触发回调并执行一系列任务.我在回调函数中发布了两条消息,回到了Arduino正在侦听的主题.但是,仅在函数退出后才发布消息.谢谢您的所有宝贵时间.我试图在回调函数中使用loop(1),超时为1秒.该程序将立即发布该消息,但似乎陷入了循环.有人可以给我一些指针如何在我的回调..._python 函数里面 mqtt调用publish方法 没有效果
win11怎么装回win10系统_安装win10后卸载win11-程序员宅基地
文章浏览阅读3.4w次,点赞16次,收藏81次。微软出来了win11预览版系统,很多网友给自己的电脑下载安装尝鲜,不过因为是测试版可能会有比较多bug,又只有英文,有些网友使用起来并不顺畅,因此想要将win11退回win10系统。那么win11怎么装回win10系统呢?今天小编就教下大家win11退回win10系统的方法。方法一:1、首先点击开始菜单,在其中找到“设置”2、在设置面板中,我们可以找到“更新和安全”3、在更新和安全中,找到点击左边栏的“恢复”4、恢复的右侧我们就可以看到“回退到上版本的win10”了。方法二:_安装win10后卸载win11
SQL Server菜鸟入门_sql server菜鸟教程-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏3次。数据定义_sql server菜鸟教程
Leetcode 数组(简单题)[1-1000题]_给定一个浮点数数组nums(逗号分隔)和一个浮点数目标值target(与数组空格分隔),请-程序员宅基地
文章浏览阅读1.9k次。1. 两数之和给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。示例:给定 nums = [2, 7, 11, 15], target = 9因为 nums[0] + nums[1] = 2 + 7 = 9所以返回 [0, 1]方法一..._给定一个浮点数数组nums(逗号分隔)和一个浮点数目标值target(与数组空格分隔),请
python性能优化方案_python 性能优化方法小结-程序员宅基地
文章浏览阅读152次。提高性能有如下方法1、Cython,用于合并python和c语言静态编译泛型2、IPython.parallel,用于在本地或者集群上并行执行代码3、numexpr,用于快速数值运算4、multiprocessing,python内建的并行处理模块5、Numba,用于为cpu动态编译python代码6、NumbaPro,用于为多核cpu和gpu动态编译python代码为了验证相同算法在上面不同实现..._np.array 测试gpu性能