孪生神经网络(Siamese neural network)-程序员宅基地
一. 基础概念
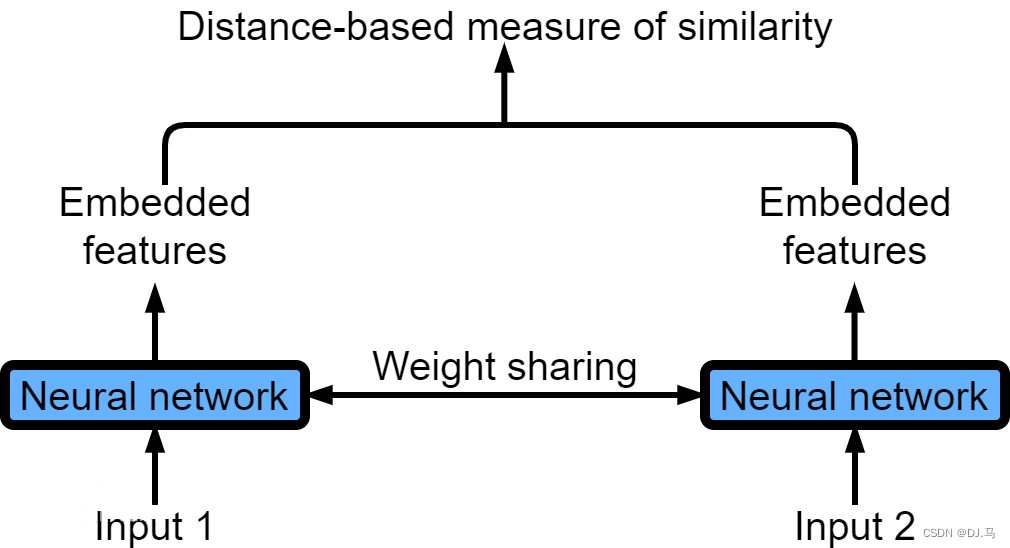
简单来说,Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,如下图所示。
孪生神经网络(Siamese neural network),又名双生神经网络,是基于两个人工神经网络建立的耦合构架。孪生神经网络以两个样本为输入,输出其嵌入高维度空间的表征,以比较两个样本的相似程度。狭义的孪生神经网络由两个结构相同,且权重共享的神经网络拼接而成。广义的孪生神经网络,或“伪孪生神经网络(pseudo-siamese network)”,可由任意两个神经网拼接而成。孪生神经网络通常具有深度结构,可由卷积神经网络、循环神经网络等组成。

其中,network1 和network2 是两个共享权值的网络,实际上就是两个完全相同的网络。孪生神经网络有两个输入(Input1 and Input2),将两个输入feed进入两个神经网络(Network1 and Network2),这两个神经网络分别将输入映射到新的空间,形成输入在新的空间中的表示。通过Loss的计算,评价两个输入的相似度。
如果左右两边不共享权值,而是两个不同的神经网络,叫做pseudo-siamese network,伪孪生神经网络。对于pseudo-siamese network,两边可以是不同的神经网络(如一个是lstm,一个是cnn),也可以是相同类型的神经网络。
孪生神经网络用于处理两个输入"比较类似"的情况。伪孪生神经网络适用于处理两个输入"有一定差别"的情况。比如,我们要计算两个句子或者词汇的语义相似度,使用siamese network比较适合;如果验证标题与正文的描述是否一致(标题和正文长度差别很大),或者文字是否描述了一幅图片(一个是图片,一个是文字),就应该使用pseudo-siamese network。也就是说,要根据具体的应用,判断应该使用哪一种结构,哪一种Loss。
其中,loss function 的选择很重要。Softmax当然是一种好的选择,但不一定是最优选择,即使是在分类问题中。传统的siamese network使用Contrastive Loss。损失函数还有更多的选择,siamese network的初衷是计算两个输入的相似度,。左右两个神经网络分别将输入转换成一个"向量",在新的空间中,通过判断cosine距离就能得到相似度了。Cosine是一个选择,exp function也是一种选择,欧式距离什么的都可以,训练的目标是让两个相似的输入距离尽可能的小,两个不同类别的输入距离尽可能的大
二. tensorflow实现孪生神经网络
参考论文:Learning a Similarity Metric Discriminatively, with Application to Face Verification
siamese网络和其他网络的不同之处在于,首先他是两个输入,它输入的不是标签,而是是否是同一类别,如果是同一类别就是0,否则就是1,文章中是用这个网络来做人脸识别,网络结构图如下:
从图中可以看到,他又两个输入,分别是x1和x2,左右两个的网络结构是一样的,并且他们共享权重,最后得到两个输出,分别是Gw(x1)和Gw(x2),这个网络的很好理解,当输入是同一张图片的时候,我们希望他们之间的欧式距离很小,当不是一张图片时,我们的欧式距离很大。有了网络结构,接下来就是定义损失函数,这个很重要,而经过我们的分析,我们可以知道,损失函数的特点应该是这样的:
(1) 当我们输入同一张图片时,他们之间的欧式距离越小,损失是越小的,距离越大,损失越大
(2) 当我们的输入是不同的图片的时候,他们之间的距离越大,损失越小
怎么理解呢,很简单,我们就是最小化把相同类的数据之间距离,最大化不同类之间的距离
文章中定义的损失函数如下:
首先是定义距离,使用l2范数,公式如下:
距离其实就是欧式距离,有了距离,我们的损失函数和距离的关系我上面说了,如何保证满足上面的要求呢,文章提出这样的损失函数:
其中我们的Ew就是距离,Lg和L1相当于是一个系数,这个损失函数和交叉熵其实挺像,为了让损失函数满足上面的关系(注意,同类Y取0,不同类Y取1),让Lg满足单调递增,Li满足单调递减就可以。另外一个条件是:同类图片之间的距离必须比不同类之间的距离小。
文章经过一系列推导,给出损失函数为:
其中,Ew为距离,Q为大于0的常数。
在tensorflow中实现loss为:
def siamese_loss(out1,out2,y,Q=5):
Q = tf.constant(Q, name="Q",dtype=tf.float32)
E_w = tf.sqrt(tf.reduce_sum(tf.square(out1-out2),1))
pos = tf.multiply(tf.multiply(1-y,2/Q),tf.square(E_w))
neg = tf.multiply(tf.multiply(y,2*Q),tf.exp(-2.77/Q*E_w))
loss = pos + neg
loss = tf.reduce_mean(loss)
return loss
```y
文章二:
参考:人工智能学习笔记五——孪生神经网络_孪生卷积网络_457591978的博客-程序员宅基地
所谓权值共享就是当神经网络有两个输入的时候,这两个输入使用的神经网络的权值是共享的(可以理解为使用了同一个神经网络)。很多时候,我们需要去评判两张图片的相似性,比如比较两张人脸的相似性,我们可以很自然的想到去提取这个图片的特征再进行比较,自然而然的,我们又可以想到利用神经网络进行特征提取。如果使用两个神经网络分别对图片进行特征提取,提取到的特征很有可能不在一个域中,此时我们可以考虑使用一个神经网络进行特征提取再进行比较。这个时候我们就可以理解孪生神经网络为什么要进行权值共享了。
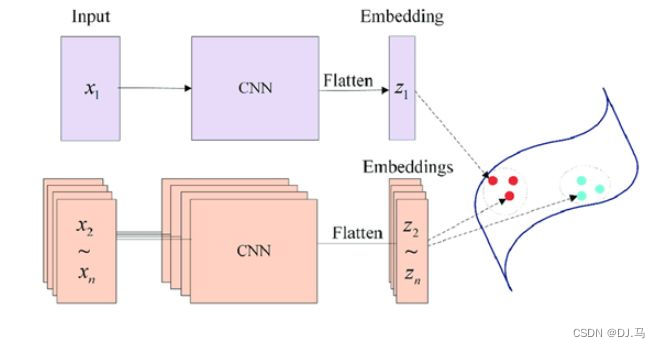
映射的方法有多种,常见的映射方法为平方差映射和绝对值映射。对于输入的两张图片,在通过共享权重的神经网络的特征提取后,会得到两组一维,大小为N的特征向量W1,W2。设通过映射后得到的一维向量为W3,那么平方差映射的公式为:
绝对值映射的公式为:
至此,孪生神经网络共享权重的部分就结束了,对于新的向量W3,既可以继续进行神经网络操作,也可以将向量的每个值加起来后开平方或者取平均值做为损失函数,视具体情况而定。在本例中,我们采取后者方法,我们规定这个损失函数叫做对比损失函数(contrasive loss)。公式为:
其中y表示样本标签,也就是1或者0,表示输入的两张图片是否为同一种类型的图片,如果是就为1,否则为0。margin表示阈值,因为当输入图片为不同类型时,d的值会非常大,为了防止d过大导致损失函数变化不均匀,所以设置阈值,一般margin的值取1。
观察这个式子可以发现,当输入图片为相同类型时,损失函数就是MSE损失函数开平方,神经网络会把W1,W2的值调整得尽量相等,从而d的值越小,损失函数的值越小。当输入图片为不同类型时,神经网络会把W1,W2的值调整得尽量不相等,从而d的值越大,如果d的值超过了阈值margin,那么损失函数的值就为0。
为了衡量模型在训练集上的准确度,对于Accuracy的计算也需要设计一个函数,在本例中,我们规定,当d>0.5时,神经网络将认定两张图片为不同图片,d<0.5时,神经网络将认定两张图片为同一图片。可视具体情况调整划分的值。
准确度的代码如下:
import keras.backend as K
def accuracy(y_true, y_pred): # Tensor上的操作
return K.mean(K.equal(y_true, K.cast(y_pred < 0.5, y_true.dtype))) 损失函数的代码如下:
import keras.backend as K
def contrastive_loss(y_true, y_pred):
margin = 1
sqaure_pred = K.square(y_pred)
margin_square = K.square(K.maximum(margin - y_pred, 0))
return K.mean(y_true * sqaure_pred + (1 - y_true) * margin_square)神经网络的结构构造如下:

图4孪生神经网络构造图
完整的代码如下:
#coding:gbk
from keras.layers import Input,Dense
from keras.layers import Flatten,Lambda,Dropout
from keras.models import Model
import keras.backend as K
from keras.models import load_model
import numpy as np
from PIL import Image
import glob
import matplotlib.pyplot as plt
from PIL import Image
import random
from keras.optimizers import Adam,RMSprop
import tensorflow as tf
def create_base_network(input_shape):
image_input = Input(shape=input_shape)
x = Flatten()(image_input)
x = Dense(128, activation='relu')(x)
x = Dropout(0.1)(x)
x = Dense(128, activation='relu')(x)
x = Dropout(0.1)(x)
x = Dense(128, activation='relu')(x)
model = Model(image_input,x,name = 'base_network')
return model
def contrastive_loss(y_true, y_pred):
margin = 1
sqaure_pred = K.square(y_pred)
margin_square = K.square(K.maximum(margin - y_pred, 0))
return K.mean(y_true * sqaure_pred + (1 - y_true) * margin_square)
def accuracy(y_true, y_pred): # Tensor上的操作
return K.mean(K.equal(y_true, K.cast(y_pred < 0.5, y_true.dtype)))
def siamese(input_shape):
base_network = create_base_network(input_shape)
input_image_1 = Input(shape=input_shape)
input_image_2 = Input(shape=input_shape)
encoded_image_1 = base_network(input_image_1)
encoded_image_2 = base_network(input_image_2)
l2_distance_layer = Lambda(
lambda tensors: K.sqrt(K.sum(K.square(tensors[0] - tensors[1]), axis=1, keepdims=True))
,output_shape=lambda shapes:(shapes[0][0],1))
l2_distance = l2_distance_layer([encoded_image_1, encoded_image_2])
model = Model([input_image_1,input_image_2],l2_distance)
return model
def process(i):
img = Image.open(i,"r")
img = img.convert("L")
img = img.resize((wid,hei))
img = np.array(img).reshape((wid,hei,1))/255
return img
#model = load_model("testnumber.h5",custom_objects={'contrastive_loss':contrastive_loss,'accuracy':accuracy})
wid=28
hei=28
model = siamese((wid,hei,1))
imgset=[[],[],[],[],[],[],[],[],[],[]]
for i in glob.glob(r"train_images\*.jpg"):
imgset[int(i[-5])].append(process(i))
size = 60000
r1set = []
r2set = []
flag = []
for j in range(size):
if j%2==0:
index = random.randint(0,9)
r1 = imgset[index][random.randint(0,len(imgset[index])-1)]
r2 = imgset[index][random.randint(0,len(imgset[index])-1)]
r1set.append(r1)
r2set.append(r2)
flag.append(1.0)
else:
index1 = random.randint(0,9)
index2 = random.randint(0,9)
while index1==index2:
index1 = random.randint(0,9)
index2 = random.randint(0,9)
r1 = imgset[index1][random.randint(0,len(imgset[index1])-1)]
r2 = imgset[index2][random.randint(0,len(imgset[index2])-1)]
r1set.append(r1)
r2set.append(r2)
flag.append(0.0)
r1set = np.array(r1set)
r2set = np.array(r2set)
flag = np.array(flag)
model.compile(loss = contrastive_loss,
optimizer = RMSprop(),
metrics = [accuracy])
history = model.fit([r1set,r2set],flag,batch_size=128,epochs=20,verbose=2)
# 绘制训练 & 验证的损失值
plt.figure()
plt.subplot(2,2,1)
plt.plot(history.history['accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train'], loc='upper left')
plt.subplot(2,2,2)
plt.plot(history.history['loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train'], loc='upper left')
plt.show()
model.save("testnumber.h5")训练过程图如下:

图5训练过程图

图6训练过程图
评估的展示代码如下:
import glob
from PIL import Image
import random
def process(i):
img = Image.open(i,"r")
img = img.convert("L")
img = img.resize((wid,hei))
img = np.array(img).reshape((wid,hei,1))/255
return img
def contrastive_loss(y_true, y_pred):
margin = 1
sqaure_pred = K.square(y_pred)
margin_square = K.square(K.maximum(margin - y_pred, 0))
return K.mean(y_true * sqaure_pred + (1 - y_true) * margin_square)
def accuracy(y_true, y_pred): # Tensor上的操作
return K.mean(K.equal(y_true, K.cast(y_pred < 0.5, y_true.dtype)))
def compute_accuracy(y_true, y_pred):
pred = y_pred.ravel() < 0.5
return np.mean(pred == y_true)
imgset=[]
wid = 28
hei = 28
imgset=[[],[],[],[],[],[],[],[],[],[]]
for i in glob.glob(r"test_images\*.jpg"):
imgset[int(i[-5])].append(process(i))
model = load_model("testnumber.h5",custom_objects={'contrastive_loss':contrastive_loss,'accuracy':accuracy})
for i in range(50):
if random.randint(0,1)==0:
index=random.randint(0,9)
r1 = random.randint(0,len(imgset[index])-1)
r2 = random.randint(0,len(imgset[index])-1)
plt.figure()
plt.subplot(2,2,1)
plt.imshow((255*imgset[index][r1]).astype('uint8'))
plt.subplot(2,2,2)
plt.imshow((255*imgset[index][r2]).astype('uint8'))
y_pred = model.predict([np.array([imgset[index][r1]]),np.array([imgset[index][r2]])])
print(y_pred)
plt.show()
else:
index1 = random.randint(0,9)
index2 = random.randint(0,9)
while index1==index2:
index1 = random.randint(0,9)
index2 = random.randint(0,9)
r1 = random.randint(0,len(imgset[index1])-1)
r2 = random.randint(0,len(imgset[index2])-1)
plt.figure()
plt.subplot(2,2,1)
plt.imshow((255*imgset[index1][r1]).astype('uint8'))
plt.subplot(2,2,2)
plt.imshow((255*imgset[index2][r2]).astype('uint8'))
y_pred = model.predict([np.array([imgset[index1][r1]]),np.array([imgset[index2][r2]])])
print(y_pred)
plt.show()
图7 图片相似度比较

图8 图片相似度比较
智能推荐
使用iOS上的Google Chrome浏览器在ASP.NET网站上进行FormsAuthentication-程序员宅基地
文章浏览阅读214次。A few people have said that they have noticed problems the new iPhone/iPad Google Chrome apps as well as trouble with applications that use hosted Safari inside of UIWebView (which is what Chrome is) ..._ios
Linux基本命令及操作总结_linux基本命令实验总结-程序员宅基地
文章浏览阅读2.6k次,点赞3次,收藏29次。一、基本命令1、开机和关机 sync #将数据由内存同步到硬盘中 shutdown #关机指令, shutdown -h 10 # 10分钟后关机 shutdown -h 20:25 #在当天20:25关机 shutdown -h now #立马关机 shutdown -r now #系统立马重启 reboot #重启 halt #关闭系统2、系统目录结构1、一切皆文件2、根目录 //bin : bi_linux基本命令实验总结
【VS Code插件开发】Webview面板(三)_createwebviewpanel-程序员宅基地
文章浏览阅读1.5w次,点赞64次,收藏56次。Webview API 允许扩展在 VS Code 中创建完全可自定义的视图。例如,内置的 Markdown 扩展使用 webview 来渲染 Markdown 预览。Webview 还可以用于构建超出 VS Code 原生 API 支持范围的复杂用户界面。_createwebviewpanel
用c语言实现一个通讯录-程序员宅基地
文章浏览阅读490次,点赞13次,收藏7次。【代码】用c语言实现一个通讯录。
Java安装搭建部署CRMEB 外贸版多商户教程文档_java api部署-程序员宅基地
文章浏览阅读157次。4、上传两个可运行jar到 api.frontxxx.com 和 api.adminxxx.com 对应的域名下 从域名上应该能看出对应的两个jar包上传的目录位置。SSL 证书有收费的也有免费的,真是的生产环境建议购买收费的ssl证书,以免影响浏览器识别安全策略。启动两个api 可以SSH链接自己的命令行工具,也可以直接在宝塔的终端上执行,结果都是一样的。打包后的 Crmeb-admin.jar和Front-admin.jar文件 如下图。11、商户端和管理端部署方式一样,这里仅以商户为示例。_java api部署
log4cplus 使用方法 配置_log4cplus::helpers::properties::setproperty设置行号-程序员宅基地
文章浏览阅读2.5k次。转自https://my.oschina.net/lovecxx/blog/185951Log4cplus使用指南1. Log4cplus简介log4cplus是C++编写的开源的日志系统,前身是java编写的log4j系统,受Apache Software License保护,作者是Tad E. Smith。log4cplus具有线程安全、灵活、以及多粒度控制的特点,通过将日志..._log4cplus::helpers::properties::setproperty设置行号
随便推点
一种可调速的液体采样泵-程序员宅基地
文章浏览阅读323次。流量和压力较小的抽水管路一般使用微型水泵。在选择液体采样泵时,真空度、流量是最主要的选型参数。真空度直接决定吸水的高度差。要注意的是排水流量、高度不仅和泵自身结构有关,还受下游管路高度差、口径、流体阻力等影响。液体采样泵厂家说明书中的性能都是在标准的实验条件下测得,与实际的使用条件多有差异,这给用户选用带来一些麻烦。有时用户不得不把管路寄到厂家,由厂家通过实验来选型或定制,费时费力,也增加了成本。
(2011.08.02)自学《C++ 程序设计》(谭浩强 编著)时做过的习题汇总。_((2n-1)脳x-p_n-1(x)-(n-1)脳p_n-2(x))/n-程序员宅基地
文章浏览阅读7.4k次。在学习这本书的时候,开始的时候是老师教的,但是自从第二章以后,全是自学的了,一年结束了,这本书也自学完了,下面是自学了两个学期我所做过的习题,温故而知新!//第三章,第3题,输入一个华氏温度,要求输出摄氏温度。公式为C=(5/9)*(F-32),输出要有文字说明,取两位小数。#include #include using namespace std;int main()_((2n-1)脳x-p_n-1(x)-(n-1)脳p_n-2(x))/n
android手机获取cpu信息_shell读取手机处理器型号-程序员宅基地
文章浏览阅读9.9k次,点赞2次,收藏4次。前言获取android手机的设备信息,首先要从android手机系统的所基于的linux的入手。_shell读取手机处理器型号
linux系统中解压缩zip文件_linux能解压zip文件吗-程序员宅基地
文章浏览阅读1.8w次,点赞21次,收藏88次。其中,file.zip是需要解压的zip文件的文件名,-d选项用于指定解压文件的目标路径,target_dir是目标路径的名称。回车后,将开始解压文件。解压完成后,你将在target_dir中找到解压后的文件。_linux能解压zip文件吗
lstm多输入时间序列预测_梯度阈值等于1说明什么-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏45次。lstm 多输入时间序列预测clcclose allclear all%加载数据,重构为行向量load data.matIN_train = data((1:4197),2:9)';OUT_train = data((1:4197),10)';% 测试集――10个样本IN_test = data((4198:end),2:9)';OUT_test = data((4198:end),10)';N = size(IN_test,2);[in_train, ps_input] = ma_梯度阈值等于1说明什么
嵌入式 CC2543 RF中断详解_网程里254c3f-程序员宅基地
文章浏览阅读1.3k次。芯片是TI CC2543 因为公司要求,选定的芯片是TI 的CC2543,这款芯片很少人用,资料也就是官方的资料和例程,下面是我自己根据这几天看的例程,总结一下,如果哪里不对,欢迎大家斧正。下面用的是TI给的例程,GenericBroadcast 程序。_网程里254c3f