常考排序算法总结(插入排序,希尔排序,快速排序,归并排序,计数排序)_快速、希儿、归并、插入四种排序的时间复杂度-程序员宅基地
一.插入排序
当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移
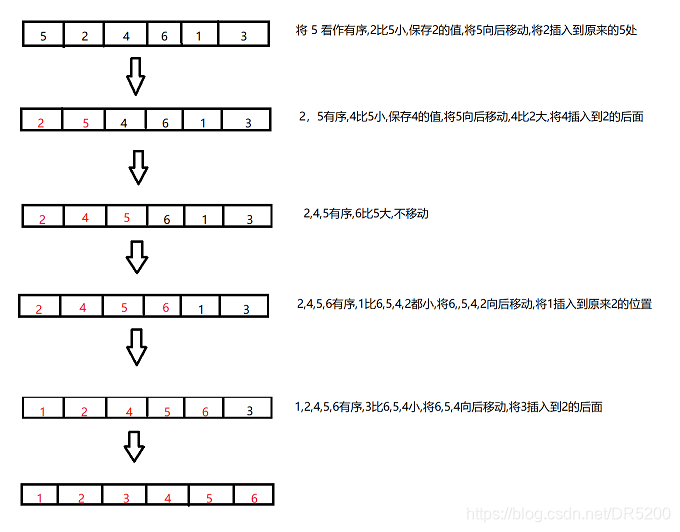
具体流程在图中已经画出
插入排序在最坏的情况的时间复杂度是多少呢?
最坏的情况很显然是逆序的情况,要想有序,第二个数需要移动1次,第三个数需要移动2次…,第n个数需要移动(n - 1)次,则由等差数列公式可得 1 + 2 + 3 + …+ (n - 1) = (n - 1)n / 2,因此最坏情况下的时间复杂度为O(N^2)
插入排序在最好的情况下时间复杂度是多少呢?
最好的情况很显然是有序的情况,只需要遍历一次原数组即可,不需要进行移动操作,因此最好的情况时间复杂度为O(N)
插入排序的空间复杂度 : O(1) , 插入排序不需要额外的空间,可在原数组上直接进行修改
插入排序的稳定性 : 稳定,插入排序是可以做到排序之后不改变相同元素的相对顺序的
插入排序的实现过程如下
void InsertSort(int* a,int n)
{
int i = 0;
for(i = 0;i < n - 1;i++)
{
int end = i,tmp = a[end + 1];
while(end >= 0)
{
if(tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
我们也可以由此看出插入排序是一个比较宽容的排序,即一组数据不一定要有序时间复杂度才能是O(N),当数据接近有序的时候,时间复杂度也可以近似的认为是O(N),同理,当数据接近逆序的时候,时间复杂度也可以近似的认为是O(N^2)
基于这个原因,希尔对插入排序进行了优化,毕竟插入排序在逆序的情况下时间复杂度为O(N^2) , 这显然不是我们所想要看到的,于是希尔就想到了对数据进行预排序的操作,经过预排序后的数据接近有序,再对其进行插入排序,这时插入排序的时间复杂度为O(N),那么预排序的时间复杂度如果小于O(N*N),就可以对插入排序达到一定的优化效果
二.希尔排序
希尔排序的思想为 : 对数据先进行预排序,使数据接近有序后,再进行插入排序
预排序是对数据进行分组插入排序,图示如下
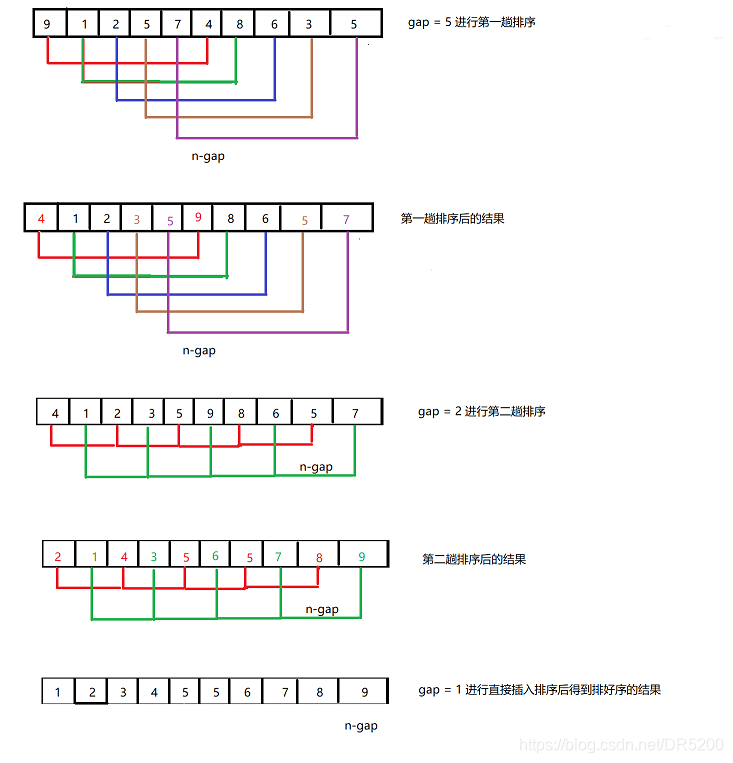 希尔排序的实现过程如下 :
希尔排序的实现过程如下 :
void ShellSort(int* a,int n)
{
int gap = n;
while(gap > 1)
{
// + 1 是为了最后让 gap 能取到 1,进行直接插入排序
gap = (gap / 3) + 1;
int i = 0;
for(i = 0;i < n - gap;i++)
{
int end = i,tmp = a[end + gap];
while(end >= 0)
{
if(tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
可以看到刚开始gap较大时,数据较无序,数据之间的移动较快,大的数被较快的向右边移动,小的数被较快的向左边移动,经过这样移动过后,数据逐渐趋近于有序
随着gap的减小,数据越来越有序,数据间的移动较慢,大的数被较慢的向右边移动,小的数被较慢的向左边移动
最后我们对接近有序的数据进行一次直接插入排序,达到有序的目的
希尔排序的时间复杂度 : 由于希尔排序的时间复杂度取决于gap的取值,所以我们在这里以gap = (gap / 3) + 1 为例分析,刚开始 gap 较大时,数据移动的较快,可以认为单次插入排序为O(1),一共进行(n - n / 3) = 2 / 3 * n 次,即O(N),到最后 gap = 1 进行直接插入排序为O(N)
gap 由 n/3 到 1 共循环 log3(N),故总时间复杂度为 O(N * log3(N))
希尔排序的空间复杂度 : O(1),希尔排序不需要额外的空间,可在原数组上直接进行修改
希尔排序的稳定性 : 不稳定,由图示可以看到,在进行第一趟排序时,两个5被分到了不同的组,第一趟排完之后两个5的相对位置已经改变了
三.快速排序
快速排序的思想 : 选中一个数为基准数(一般为最左边或最右边的数),通过一系列的操作使得基准数到达它最终的位置,即基准数左边的数比它小,右边的数比它大
将区间按照基准值划分为左右两半部分的常见方式有:
(1). hoare版本
(2). 挖坑法
(3). 前后指针版本
(1).hoare版本
思想 : 假设选中最左边的数为基准数,left 指针指向最左边,right指针指向最右边,right指针先出发去寻找比基准数小的值(在移动的过程中,left < right) ,然后left指针出发去找比基准数大的值(在移动的过程中,left < right),交换left指针和right指针所指向的值,直到left == right,最后交换left指针所指向的值和基准数
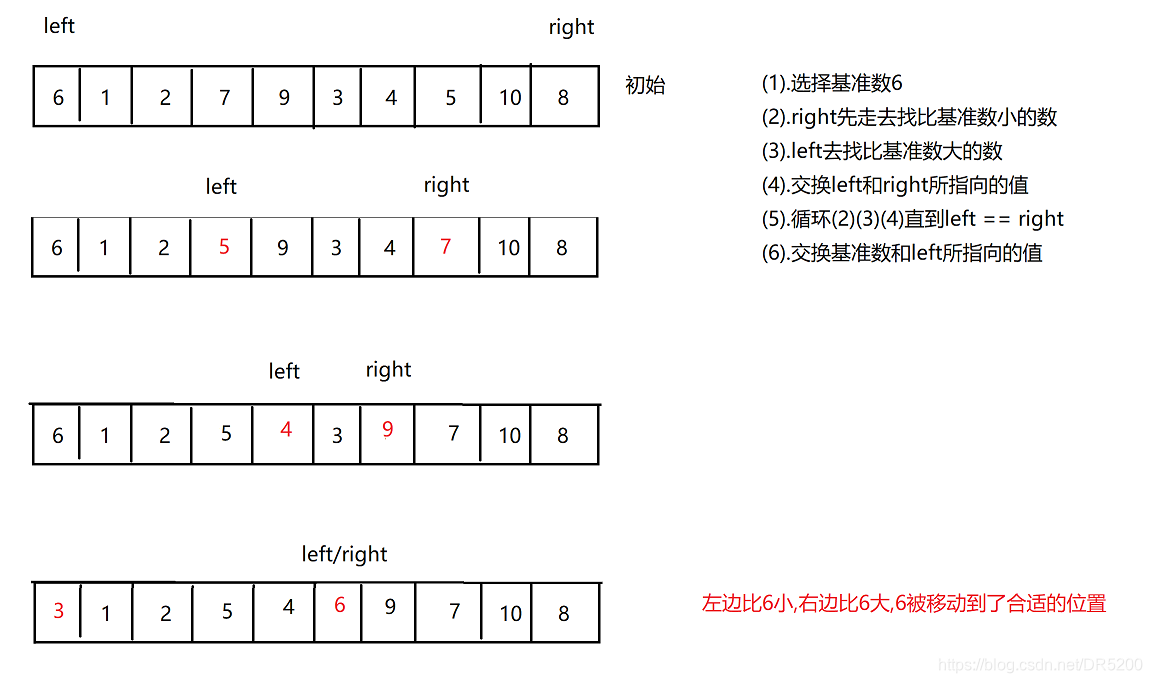 hoare版本实现
hoare版本实现
void Swap(int* e1,int* e2)
{
int tmp = *e1;
*e1 = *e2;
*e2 = tmp;
}
int hoare(int* a,int left,int right)
{
int keyi = left;
while(left < right)
{
while(left < right && a[right] >= a[keyi])
right--;
while(left < right && a[left] <= a[keyi])
left++;
Swap(&a[left],&a[right]);
}
Swap(&a[left],&a[keyi]);
return left;
}
(2).挖坑法
思想 : 假设选中最左边的数为基准数,left 指针指向最左边,right指针指向最右边,用临时变量tmp保存基准数,right出发去找比基准数小的数,将right所指向的值赋值给left所指向的值,然后left出发去找比基准数大的数,将left所指向的值赋给right所指向的值

挖坑法实现
int hole(int* a,int left,int right)
{
int tmp = a[left];
while(left < right)
{
while(left < right && a[right] >= tmp)
right--;
a[left] = a[right];
while(left < right && a[left] <= tmp)
left++;
a[right] = a[left];
}
a[left] = tmp;
return left;
}
(3).前后指针法
思路 : 假设选中最左边的数为基准数,prev = left, cur = left + 1,cur去找比基准数小的数,和a[++prev]交换,直到cur走到末尾,最后交换a[prev]和a[left]
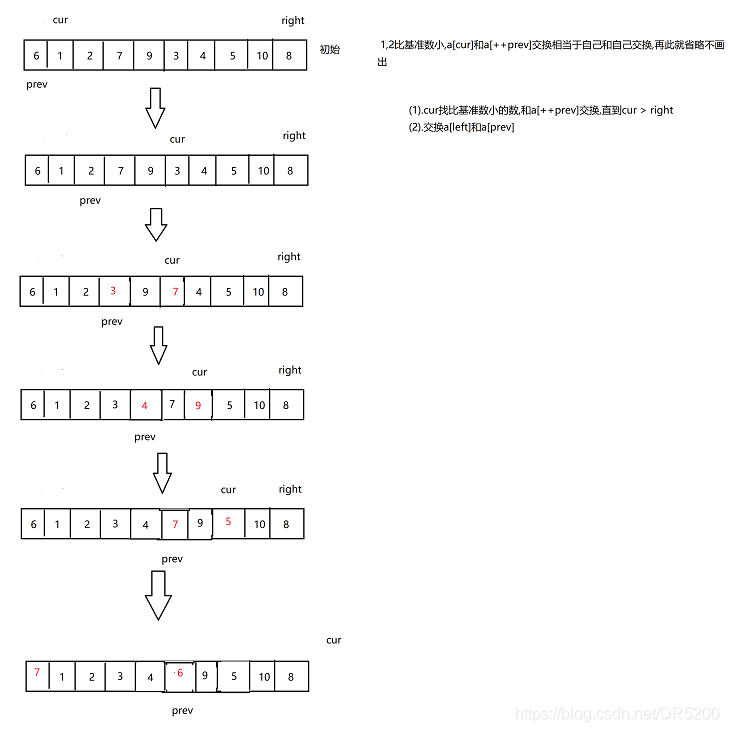
前后指针实现
int FBP(int* a,int left,int right)
{
int keyi = left,prev = left,cur = left + 1;
for(cur = left + 1;cur <= right;cur++)
{
if(a[cur] < a[keyi])
{
++prev;
Swap(&a[cur],&a[prev]);
}
}
Swap(&a[prev],&a[keyi]);
return prev;
}
经过上面单趟快速排序过后,将我们选中的基准数移动到了正确的位置,然后在基准数的左右区间采取同样的方法进行快速排序
快速排序递归实现
void QuickSort(int* a,int left,int right)
{
// 区间只有一个值或区间不存在
if(left >= right)
return;
int keyi = FBP(a,left,right);
// 递归左区间
QuickSort(a,left,keyi - 1);
// 递归右区间
QuickSort(a,keyi + 1,right);
}
快速排序非递归实现
void QuickNonR(int* a,int begin,int end)
{
Stack st;
StackInit(&st);
// 将初始的begin和end入栈
StackPush(&st, begin);
StackPush(&st, end);
while (!StackEmpty(&st))
{
// 得到区间的右端点
int right = StackTop(&st);
StackPop(&st);
// 得到区间的左端点
int left = StackTop(&st);
StackPop(&st);
// 对该段区间进行单趟快排
int keyi = FBP(a, left, right);
// 将左区间的左右端点入栈
if (left < keyi - 1)
{
StackPush(&st, left);
StackPush(&st,keyi - 1);
}
// 将右区间的左右端点入栈
if (right > keyi + 1)
{
StackPush(&st, keyi + 1);
StackPush(&st, right);
}
}
// 销毁栈
StackDestroy(&st);
}
接下来我们来分析快速排序的时间复杂度
在最好的情况下,我们所选中的基准数都被移动到区间中间的位置,即O(N*logN)
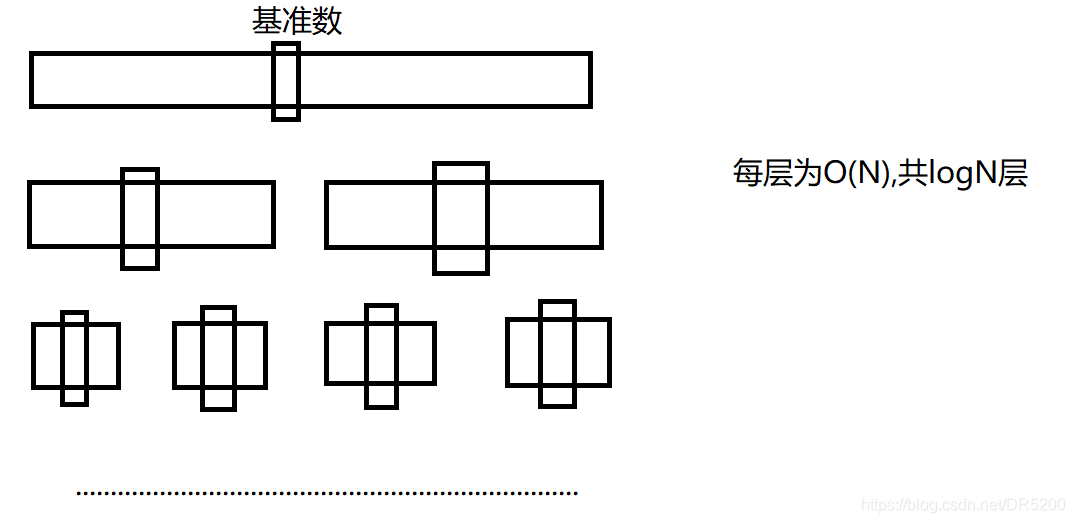
在最坏的情况下,若我们想要排升序,原数据正好为升序,此时时间复杂度为O(N^2)
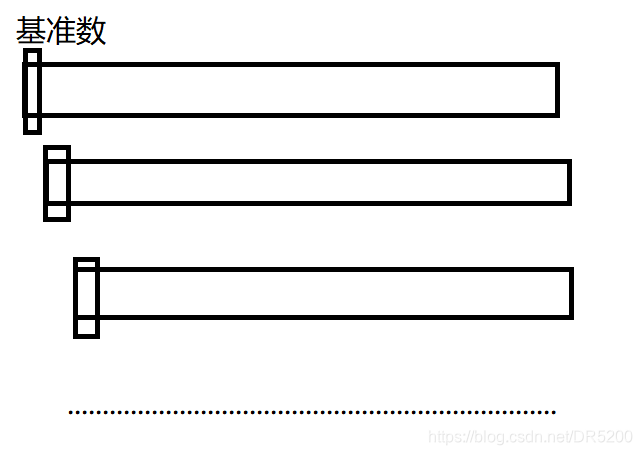
在最坏的情况下,时间复杂度为O(N^2),这不是我们所想要看到的,我们可以对其进行一些优化,最坏的情况发生的原因是因为我们选择的基准数是最大的或者是最小的,基于这个原因,我们可以在a[left],a[mid],a[right]三数之中选择一个并不是最大的也不是最小的作为我们的基准数,做完优化后,我们可以发现原本最坏的情况在优化过后变为了最好的情况
我们可以将上面讲的三种单趟排序的方法都加上三数取中法来进行优化
三数取中的实现
// 三数取中,选择a[left],a[right],a[mid]中既不是最大的,也不是最小的数
int MiddleIndex(int* a, int left, int right)
{
int mid = left + (right - left) / 2;
if (a[left] < a[mid])
{
// a[left] < a[mid] < a[right]
if (a[mid] < a[right])
return mid;
// a[mid] > a[left] && a[mid] > a[right]
else if (a[left] < a[right])
return right;
else
return left;
}
else
{
// a[mid] > a[left] > a[right]
if (a[mid] > a[right])
return mid;
// a[mid] > a[left] && a[right] > a[left]
else if (a[left] < a[right])
return left;
else
return right;
}
}
快速排序的空间复杂度 : O(logn) ~ O(n),在递归的过程中会消耗栈空间
快速排序的稳定性 : 不稳定,在排序的过程中可能会使相同元素的相对顺序发生改变
四.归并排序
思路 : 将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再将有序的子序列进行合并
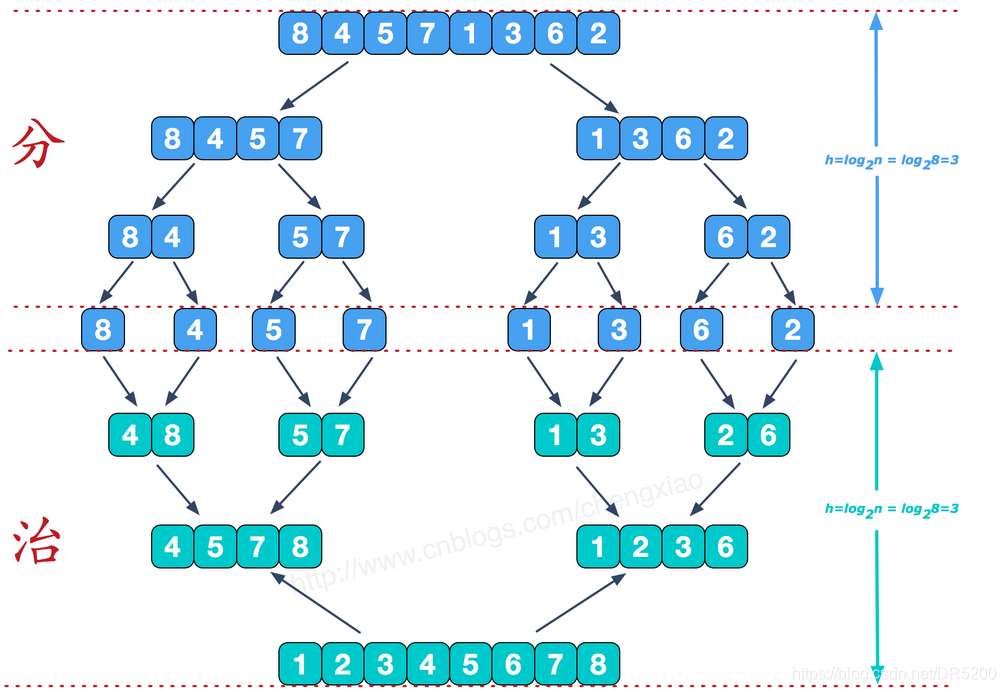
我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤。
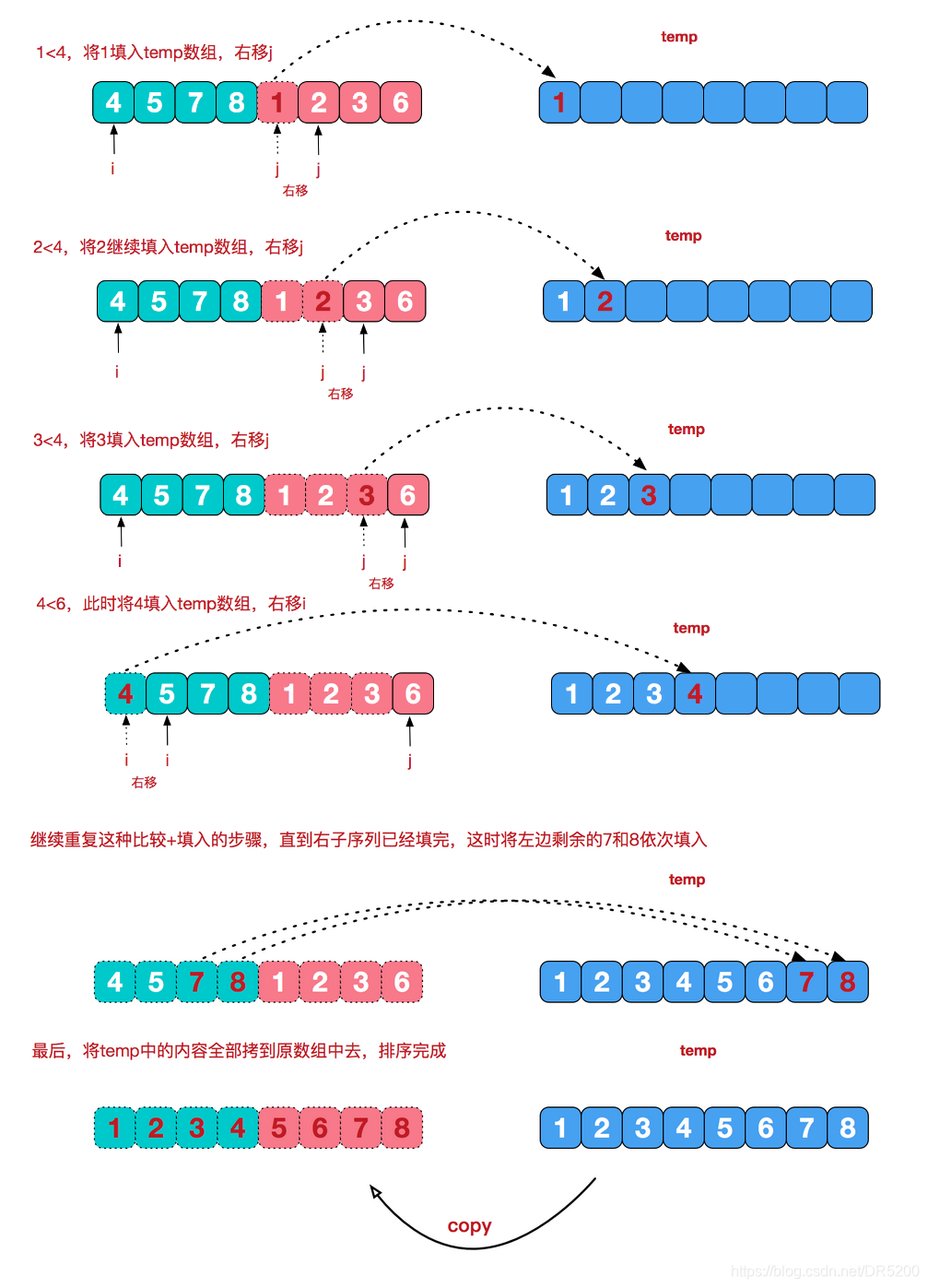
归并排序递归实现
void MergeSort(int* a,int* tmp,int left,int right)
{
if(left >= right)
return;
int mid = left + (right - left) / 2;
// 分解
MergeSort(a,tmp,left,mid);
MergeSort(a,tmp,mid + 1,right);
int i = left;
// 归并
int begin1 = left,end1 = mid,begin2 = mid + 1,end2 = right;
while(begin1 <= end1 && begin2 <= end2)
{
// 得到a[begin1]和a[begin2]中较小的数,再移动较小的值
if (a[begin1] < a[begin2])
tmp[i++] = a[begin1++];
else
tmp[i++] = a[begin2++];
}
// 将[begin1,end1]剩余的数放到tmp数组中
while (begin1 <= end1)
tmp[i++] = a[begin1++];
// 将[begin1,end1]剩余的数放到tmp数组中
while (begin2 <= end2)
tmp[i++] = a[begin2++];
// 将tmp数组的值拷贝到a数组中
memcpy(a, tmp, sizeof(int) * i);
}
归并排序非递归实现
思路 : 先将数据一个一个(gap)进行合并, 再两个两个(gap)进行合并,直到 gap < n 为止
其中在合并过程中最后有三种情况需要注意一下 :
(1). 第一组的数据不够gap个,不用再合并了
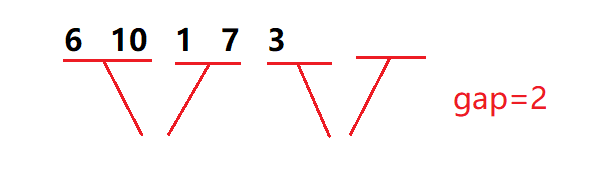
(2). 第一组的数据够 gap 个,但第二个区间不存在,不用再合并了
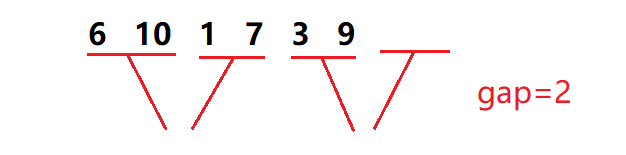
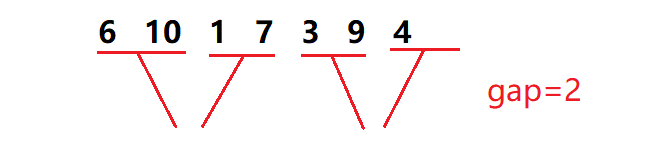
(3). 第一组和第二组区间都存在,但第二组区间数据不够 gap 个.
void _MergeSort(int* a,int* tmp,int begin1,int end1,int begin2,int end2)
{
int i = begin1;
while(begin1 <= end1 && begin2 <= end2)
{
// 得到a[begin1]和a[begin2]中较小的数,再移动较小的值
if (a[begin1] < a[begin2])
tmp[i++] = a[begin1++];
else
tmp[i++] = a[begin2++];
}
// 将[begin1,end1]剩余的数放到tmp数组中
while (begin1 <= end1)
tmp[i++] = a[begin1++];
// 将[begin1,end1]剩余的数放到tmp数组中
while (begin2 <= end2)
tmp[i++] = a[begin2++];
// 将tmp数组的值拷贝到a数组中
memcpy(a, tmp, sizeof(int) * i);
}
void MergeSortNonR(int* a,int* tmp,int n)
{
int gap = 1;
while(gap < n)
{
int i = 0;
for(i = 0;i < n;i += 2 * gap)
{
int begin1 = i,end1 = i + gap - 1,begin2 = i + gap,end2 = i + 2 * gap - 1;
// 第二个区间不存在
if(begin2 >= n)
break;
// 第二个区间数据不够gap个,修正区间范围
if(end2 >= n)
end2 = n - 1;
_MergeSort(a,tmp,begin1,end1,begin2,end2);
}
gap *= 2;
}
}
归并排序的时间复杂度 : O(NlogN),归并排序每层复杂度为O(N),一共递归 logN 层,故时间复杂度为O(NlogN)
归并排序空间复杂度 : O(N),归并排序需要使用额外的一个数组
归并排序的稳定性 : 稳定
由归并排序也引出了常见的内排序和外排序问题
内排序:数据量少,可以放到内存中进行排序。
外排序:数据量大,内存中放不下,数据只能放到磁盘文件中,需要排序
假设现在有10亿个整数存放在文件A中,我们可以使用的内存为 512M,怎样对这10亿个整数进行排序呢?
(1). 10亿个整数大约占4GB的内存,而我们可使用的内存只有512M,因此我们每次从文件A中读取 1/8 到内存中,在内存中对这1/8 的数据进行内排序(这里的排序不能选用归并排序,因为归并排序的空间复杂度为O(N)),将排好序的数据写入到一个新的文件中,最终我们就可以得到8个分别有序的小文件,每个文件的大小为512M
(2).对这8个小文件进行归并排序,归并成4个文件(每个文件大小为1GB),归并成2个文件(每个文件为2GB),归并成1个文件(文件大小为4GB)
五.计数排序
原理 :
(1). 统计相同元素出现次数
(2). 根据统计的结果将序列回收到原来的序列中
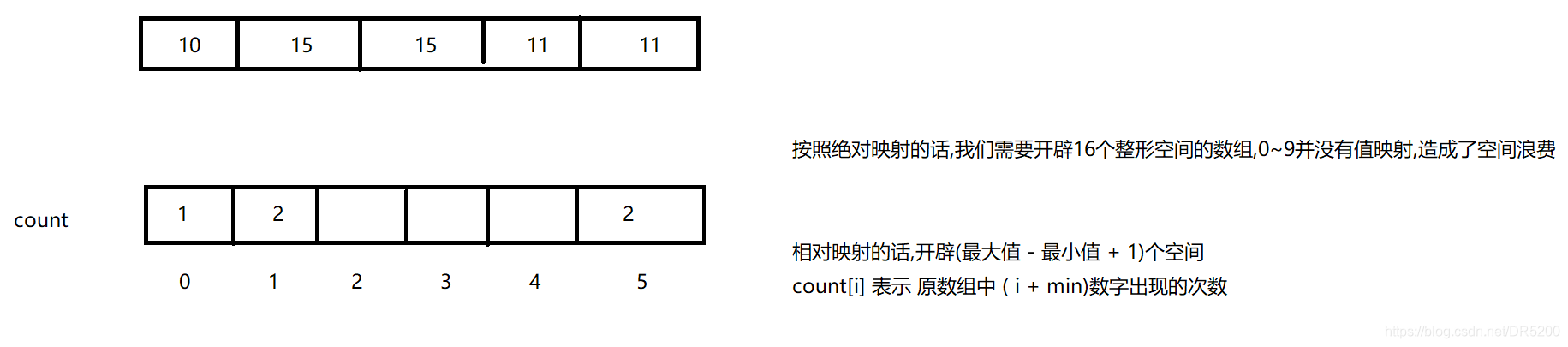
第一种实现 : 绝对映射
 绝对映射的缺点也非常明显 :
绝对映射的缺点也非常明显 :
(1).当数组的最大值很大时,我们所开辟的数组大小也会非常的大
(2).计数排序只能用来排序整数
优化 : 相对映射
void CountSort(int* a,int n)
{
// 选择出最大值,最小值
int i = 0,min = a[0],max = a[0];
for(i = 0;i < n;i++)
{
if(a[i] > max)
max = a[i];
if(a[i] < min)
min = a[i];
}
int range = max - min + 1;
int* count = (int*)malloc(sizeof(int) * range);
memset(count,0,sizeof(int) * range);
for(i = 0;i < n;i++)
{
count[a[i] -min]++;
}
int j = 0;
for(i = 0;i < range;i++)
{
while(count[i]--)
{
a[j++] = i + min;
}
}
}
计数排序的时间复杂度 : O(MAX(N,range))
计数排序的空间复杂度 : O(range)
计数排序稳定性 : 稳定
综上所述 : 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限
智能推荐
同样接口同样请求参数用postman请求后端返回数据和前端请求返回数据不同_使用postman查出的是新数据,从前端调用是老数据-程序员宅基地
文章浏览阅读5.6k次。postman请求结果:前端请求结果:分析:莫得理由的,所以很大可能是前端数值问题,然后通过测试一下,如下:结论:数字前端溢出,解决方案,将后端返回字段改为string,就ok了。_使用postman查出的是新数据,从前端调用是老数据
Windows安装openssh失败——解决思路_openssh服务器安装失败-程序员宅基地
文章浏览阅读2.4k次,点赞16次,收藏26次。Linux服务器通过ssh连接windows服务器失败。Windows安装openssh遇到的问题及一些解决思路_openssh服务器安装失败
python能用来开发游戏吗,python可以开发什么游戏-程序员宅基地
文章浏览阅读735次,点赞12次,收藏27次。大家好,小编为大家解答python编程可以用来做游戏开发的问题。很多人还不知道python能用来开发游戏吗,现在让我们一起来看看吧!当然可以啦!现在日常能够用到和想到的场景,绝大多数都可以用Python实现。效果怎么样暂且不提,但是得益于丰富的第三方工具包,的确让Python能够很容易处理各种各样的场景。对于游戏开发也是这样,如果真的要想商业化,Python在游戏开发方面肯定没办法和C++相提并论,但是如果用于日常学习和自己玩一玩,Python绝对是够的。
PHP设计模式 - 门面模式(Facade)通俗易懂 / 友好示例代码_php facade-程序员宅基地
文章浏览阅读3k次,点赞2次,收藏7次。前言门面模式(Facade)又称外观模式,用于为子系统中的一组接口提供一个一致的界面。门面模式定义了一个高层接口,这个接口使得子系统更加容易使用:引入门面角色之后,用户只需要直接与门面角色交互,用户与子系统之间的复杂关系由门面角色来实现,从而降低了系统的耦合度。打个比方,比如我们要在淘宝买东西,我基本上只需要鼠标点一些按钮就完成了。但是实际上网站的后台是 很多个子系统一起去完成 你购买商品的任务的,比如网站系统,购物车系统,订单系统,用户中心系统,支付系统。这些系统 对外通过了统一的接口,让你在_php facade
SAS函数——字符函数-程序员宅基地
文章浏览阅读1w次,点赞5次,收藏58次。一、计算变量的长度基本格式:length(变量):对缺失值返回1。 lengthn(变量):对缺失值返回0。注意:长度不包括尾部空。 数值型长度默认为12。data iden; input iden $; length_1=length(iden); length_2=lengthn(iden);cards;abcdabcd123abcd_123.;proc print;run;二、提取变量中的字符指定一个变量,对该变量从起始位置.
华大MCU_HC32F460串口TX发送使用DMA传输遇到的坑_hc32l136 串口dma-程序员宅基地
文章浏览阅读3.2k次,点赞4次,收藏25次。DAM初始化结构体DMA: 1 次请求传输 1 个数据块,支持连锁传输功能,可实现 1 次请求传输多个数据块。数据块最小为 1 个数据,最多可以是 1024 个数据,每个数据的宽度可配置为 8bit,16bit 或 32bit。/* DMA 初始化结构体: */ typedef struct stc_dma_config { uint16_t u16BlockSize; ///< 设置数据块的大小, 0~1023 (0表_hc32l136 串口dma
随便推点
聚类算法K-Means, K-Medoids, GMM, Spectral clustering,Ncut_partitioning methods: k-means and k-medoids algori-程序员宅基地
文章浏览阅读335次。聚类算法是ML中一个重要分支,一般采用unsupervised learning进行学习,本文根据常见聚类算法分类讲解K-Means, K-Medoids, GMM, Spectral clustering,Ncut五个算法在聚类中的应用。Clustering Algorithms分类1. Partitioning approach: 建立数据的不同分割,然后用相同标准评价聚类结果。(比如最小化平方误差和) 典型算法:K-Means, K-Med..._partitioning methods: k-means and k-medoids algorithms
【转帖】Ulteredit正则表达式 通配符_ultra edit寻找匹配的-程序员宅基地
文章浏览阅读398次。原文地址:http://blog.sina.com.cn/s/blog_64bb25ef0100gprl.html删除空行:替换%[^t]++^p为空串删除行尾空格:替换[^t]+$为空串删除行首空格:替换%[^t]+为空串每行设置为固定的4个空格开头:替换%[^t]++^([~^t^p]^)为"^1"每段设置为固定的4个空格开头:替换%[^t]+为""(如果一行是以空格开_ultra edit寻找匹配的
基于Metronic的Bootstrap开发框架总览 -- 他人的博客收集素材_bootstrap主页布局素材-程序员宅基地
文章浏览阅读318次。感谢wuhuacong(伍华聪)的专栏!!!系列:(1)基于Metronic的Bootstrap开发框架经验总结(1)-框架总览及菜单模块的处理http://www.cnblogs.com/wuhuacong/p/4757984.html(2)基于Metronic的Bootstrap开发框架经验总结(2)--列表分页处理和插件JSTree的使用http://www.cnblog..._bootstrap主页布局素材
第四章:对象_foostr=‘abcde’-程序员宅基地
文章浏览阅读246次。4.1 对象三个特性:身份、类型、值身份:每个对象都有唯一的身份来标识自己,使用内建函数id()得到。 例子#!/usr/bin/env python#coding:utf-8a=32;print ab = a ;print id(a),id(b)结果:D:\python27\python.exe E:/workp/python/ex4.py3236402460 36402460_foostr=‘abcde’
小红书笔记详情数据python_获取笔记详情代码-程序员宅基地
文章浏览阅读535次,点赞10次,收藏8次。为你想要获取的具体笔记的ID。在运行代码之前,请确保已安装必要的Python库:requests 和 BeautifulSoup。要获取小红书笔记的详情数据,你可以使用Python来进行网页爬虫。以下是一个基本的示例代码,你可以根据需要对其进行修改和调整。请注意,小红书网站可能对爬虫进行限制,因此建议遵守相关网站的使用规定并尊重他人的隐私和版权。请求参数:num_iid=5eb1097ba091410953951d17。请求URL:c0b.cc/R4rbK2。参数说明:num_iid:小红书商品ID。_获取笔记详情代码
大模型在智慧城市设计与运转中的核心作用-程序员宅基地
文章浏览阅读293次。作者:张成文数字化、智能化产品、应用与创新,很大程度上受限于工具、模型、平台等软硬件基础设施的能力。智慧城市建设的顺利化程度、它最终表现出来的智慧化程度也是这样。直到ChatGPT为代表的新的智能化生产力这样的基础设施的出现,我们的智慧城市建设就进入发展的拐点。下面我就从大模型的多轮交互能力与通用能力这两个技术角度阐述一下生成式大模型在智慧城市设计与运转中的核心作用。一、大模型的多轮交互能力首先我..._大模型辅助城市规划设计