python基础:序列(列表、元组、字符串)、函数、字典、集合_列表、元组、字典、集合都是序列吗-程序员宅基地
技术标签: python python学习笔记 list
Python语言运行环境:
- windows
- linux
- unix
- Macos等等
博客记录内容:
Python3的所有语法、面向对象思维、运用模块进行编程、游戏编程、计算机仿真。
Python是什么类型的语言:
Python是脚本语言,脚本语言(Scripting language)是电脑编程语言,因此也能让开发者藉以编写出让电脑听命行事的程序。以简单的方式快速完成某些复杂的事情通常是创造脚本语言的重要原则,基于这项原则,使得脚本语言通常比 C语言、C++语言 或 Java 之类的系统编程语言要简单容易。一个脚本可以使得本来要用键盘进行的相互式操作自动化。一个Shell脚本主要由原本需要在命令行输入的命令组成,或在一个文本编辑器中,用户可以使用脚本来把一些常用的操作组合成一组串行。主要用来书写这种脚本的语言叫做脚本语言。很多脚本语言实际上已经超过简单的用户命令串行的指令,还可以编写更复杂的程序。
脚本语言另有一些属于脚本语言的特性:
- 语法和结构通常比较简单
- 学习和使用通常比较简单
- 通常以容易修改程序的“解释”作为运行方式,而不需要“编译”
- 程序的开发产能优于运行性能
Python基本内容:
-
Python2使用的输出语句是printf
“hello!”,而Python使用的是print(“hello!”),python3对Python不兼容,在Python下使用printf
"hello!"会报错,不仅如此Python写完每一条语句不用像C语言一样加分号 -
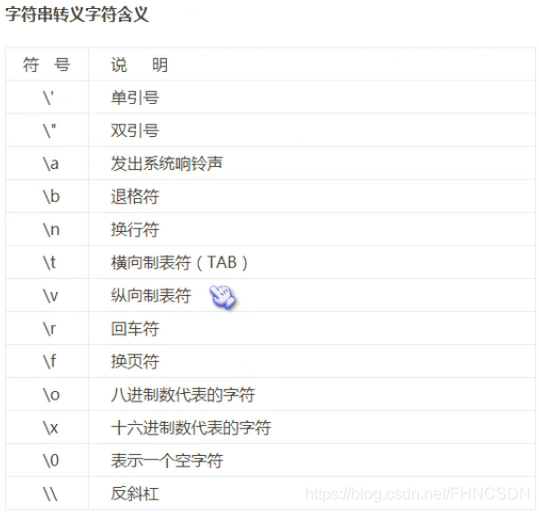
print(“hello”+“user”),这里的加号表示字符串的拼接,print(“hello\n”*8)这条语句是输出8次hello,但是如果把乘号换做加号就会报错,因为在 Python 中不能把两个完全不同的东西加在一起,比如说数字和文本。 如果我需要在一个字符串中嵌入一个双引号,正确的做法是:可以利用反斜杠(\)对双引号转义:",或者用单引号引起这个字符串。print(“hel"l"o”)或者print(‘hel"l"o’)
-
Python的缩进格式可以理解为C语言的花括号,写程序时要注意代码的缩进。input()函数是Python的内置函数(BIF)可以获取用户的输入,返回的是字符串类型,可以使用int()这个内置函数,int(input的返回值)将字符串转化为整型。可以使用 \ \来对\进行转义,当输入路径的时候可以用的到,除此之外还可以使用原始字符串,就是在变量赋值的时候前面加一个r,例如:str=r ’ C : \ file ‘然后打印str就会看到想要输出的结果:C:\file。因为此时的str就会变成:‘C:\ \now’,他会自动的将 \ 转义。非要在原始字符串结尾输入反斜杠,可以如何灵活处理?str = r’C:\Program Files\FishC\Good’ ’ \ \ ’
-
长字符串:当我们需要输出一个跨越多行的字符串时就用到了这种写法,使用三重引号字符串。如:str=" " " 要输出的跨越多行的内容" " ",也可以用三对单引号,必须成对编写。
-
python里面变量的命名规则和C语言命名规则一样,变量名可以包括字母、下划线、数字,但是变量名不能以数开头。变量使用之前要赋值,还有就是字符串必须使用单引号或者双引号括起来必须成对出现。
-
and操作符作用是当and(相当于C语言中的&&)左边和右边都是true时才会返回布尔类型的True,与之对应的是or(||),当有一边为真时就返回True。not是将当前的布尔类型数取相反的值,not True=False。除此之外,在python中3<4<5是合法的相当于3<4 and 4<5。 -
random模块,random模块里面有一个函数randint(),即随即返回一个整数。使用之前要将模块导入import random,使用方法:
number=random.randomint(1,10)。即在1到10之间随机生成一个整数。 -
Python里面的if语句和while语句用法和C语言里面的用法基本一样就是将花括号去掉换成冒号并且用缩进表示代码执行书顺序。
-
可以通过
dir(_ _builtins_ _)这个指令查看Python的BIF,如下图,里面纯小写的是Python的BIF。

-
当我们想要知道这些BIF如何使用时可以,输入以下指令help(函数名),如下图所示:

-
内置类型转换函数,int()作用是将数字字符串或者浮点型(转化浮点型的时候不是四舍五入而是直接将小数部分去掉)转化为整型(我感觉就是C语言里面的强制转换);str()作用是:将数字或者其他类型转换为字符串;float()作用是:将字符串或者整形数转换为浮点数。type()这个函数会明确告诉我们括号内数据的数据类型,除此之外还有isinstance()函数来确定数据的数据类型。isinstance这个函数需要两个参数,第一个参数是待确定类型的数据,第二个参数是指定的类型,然后函数会返回一个bool类型的值,true表示参数类型一致,false表示参数类型不一样。
-
python里面的加减乘运算和其他语言没啥区别,就是除法运算 / 两个整形数相除会得到一个精确的数,而在C语言中只是得到一个整数,小数部分后面的忽略(不进行四舍五入)。python的 / / 这个叫“地板除”,这个运算符和C语言中的还不太一样,它不管除数和被除数是否是整型,最后得到的是都是整数,只是如果除数和被除数有浮点类型结果也是浮点类型,但是小数部分是0。还有一个运算符 **表示幂运算,例如:3 星星2=9。运算符优先级:先乘除后加减,但是幂运算的运算符顺序比左边的一元运算优先级高比右边的一元运算级低,例如:-3星星2=-9 而不是 9,3星星-2=0.111111。运算优先级如下图:
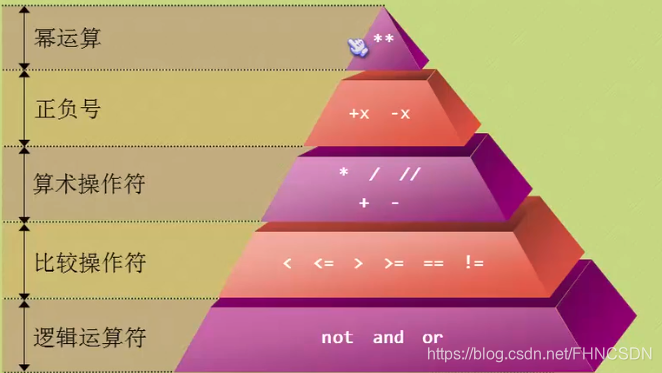
- 三元操作符:语法:x if 条件 else y。若满足条件返回x若不满足条件返回y。assert这个关键字我们称之为“断言”,当这个关键字后面的条件为假的时候,程序自动崩溃并抛出
AssertionError的异常。一般来说我们可以在程序中植入检查点,当需要确保程序中某一个条件为真才能让程序正常工作的话,assert关键字就非常有用了。 - for循环语法:for 目标 in 表达式:后面是循环体
favourite="hello"
for i in favourite:
print(i,end=" ")
输出结果:
h e l l o
这里end=" ",表示输出一个字符就在其后跟一个空格。
member=["早","你好","吃饭了吗"]
for each in member:
print(each,len(each))
运行结果:
早 1
你好 2
吃饭了吗 4
len()这个函数是计算字符串长度的
- range()函数for循环的小伙伴,语法:
range(start, stop[,step]),这个BIF有三个参数,其中中括号括起来的两个表示这两个参数是可选的,step=1表示第三个参数(步长)的值默认是1。range这个BIF的作用是生成一个从start参数(默认是0)的值开始到stop参数值(计数到stop结束,但是不包括stop)结束的数字序列。
range(10)
(0,1,2,3,4,5,6,7,8,9)
range(1,11)
(1,2,3,4,5,6,7,8,9,10)
range(0,30,5)
(0,5,10,15,20,25)
range(0,-10,-1)
(0,-1,-2,-3,-4,-5,-6,-7,-8,-9)
range(0)
()
range(1,0)
()
range(5)
list(range(5))
[0, 1, 2, 3, 4]
list()函数将range函数的输出结果转化为列表。
for循环和range配合使用:
for i in range(1,10,2):
print(i)
1
3
5
7
9
列表:
列表里面可以存放不同的数据类型。
-
创建一个普通列表:
numbe=[1,2,3,4,5] -
创建一个混合列表:
number=["你好",1,2,3.5,[4,5,6]] -
创建一个空列表:
empty=[] -
如何向列表里面添加元素
numbe.append("你好")这里使用函数:append(),里面的参数是向列表添加的内容,这里这个.表示是numbe这个列表对象里面的方法但是这个函数的参数只能是一个参数,也就是说一次只能添加一个元素到列表,如果想要添加多个参数到列表就要用到extend()函数这个函数用于列表的扩张,参数是一个列表。如:numbe.extend(['hahah','不好']) 得到:[1, 2, 3, 4, 5, '你好', 'hahah', '不好']append()和extend()这两个函数是添加到列表的尾部,如果想添加到列表的任意位置就要用到inster()函数,这个函数有两个参数,第一个参数是代表在列表中的位置,第二个参数表示在这个位置要插入的元素。numbe.insert(0,['好不好'])得到:[['好不好'], 1, 2, 3, 4, 5, '你好', 'hahah', '不好'] -
列表元素的交换可以利用中间变量,那么如何将元素从列表中删除呢?方法一:
remove()函数,参数是要删除的列表元素名称。numbe.remove(numbe[0])方法二:利用del方法del方法不是列表中的方法,所以不用.来使用它,直接del numbe[2]这是一条语句,也可以直接del numbe直接将列表删除。方法三:利用pop()函数,pop()函数其实是用于将列表中的元素取出来,也就是这个函数的返回值,若不给这个函数添加参数则默认取出最后一个元素,添加了参数之后可以取出固定的元素,元素取出后列表里面就没有了。如:numbe.pop()或者numbe.pop(要取出元素的名称(可以用下标)) -
列表切片:如果想要一次性获得多个元素,利用列表切片可以简单实现这个要求,如:
numbe是列表名称,那么numbe[1:3]就是将列表切片成从下标一到下标二的一个列表,原列表没有改变,numbe[:3]表示从列表头到下标为二处进行切片,numbe[1:]表示从列表下标第一个元素到列表尾部切片,numbe[:]表示将整个列表切片,就是对整个进行了拷贝。
列表的一些常用操作符:
- 比较操作符,就是大于小于符号,列表的比较和字符串的比较一样从列表中的第一个元素比较(字符串是比较ASIIC值),如果相等继续比较第二个元素,如果不相等则比较结束。
- 逻辑操作符
- 连接操作符,列表的连接可以用+进行连接得到一个新的列表,必须要保证+两边的数据类型相同
- 重复操作符,乘法可以让列表内容进行重复,如:
list4=[12] 。list*=3.得到:[12, 12, 12] - 成员关系操作符,这个可以用in,如:
list4=[12] , 12 inlist4返回True ,13 in list4返回False ,12 not in list4,返回False注意:in只能描述元素和列表关系,如果列表中还有列表那么,用 in 判断列表中的元素时子列表中的元素不算入。但是可以利用下标查找子列表中是否有某元素,如:list=[1,[2,3]],2 in list[1]返回Ture。访问列表中的列表的元素可以用二维数组的方式,list[1][2]第一个下标表示子列表在列表中的位置,第二个下标表示要访问的元素在子列表中的位置下标。 - dir(list)可以查看列表的内置方法,用的时候要加
.count()函数可用于计算列表某个元素在列表中出现的次数,函数参数为要找的那个元素,返回参数出现次数。如果想得到某个元素的下标还可以用index()函数,函数返回的是要查找元素在列表中第一次出现的元素下标,这个函数有三个参数,第一个是要查找下标的元素,第二个参数是查找的起始位置,第三个参数是要查找的结束位置(如果要查找的元素就在结束位置则不会找到,要将结束位置的值加一才可以找到)。 - reverse()函数,将整个列表结构顺序倒转,该函数没有参数。列表里面子列表里面的元素顺序不变。
- sort()函数:将列表元素进行排队,若没有参数则默认从小到大排列,若想得到从大到小在原地翻转(reverse)一下即可。这个函数有三个参数:sort(func,key,reverse),第一个参数func指定排序的算法,第二个参数key是和算法搭配的关键字,第三个参数是reverse默认是False,当把它置为True时则从大到小排列,如:sort(reverse=Ture)。
元组:
元组:带上枷锁的列表,元组和列表在实际使用上是非常相似的,元组是不可以随意删除和插入元素的元组是不可改变的,就像C语言里面定义的字符串常量一样不能被修改。定义元组的时候大多数情况下用(),比如:tuple1=(1,2,3),访问元组元素和访问列表元素是一样的都可以用下标访问。如:tuple1[1],可以使用:来获得元组的切片或者元组的拷贝,这一点和列表一样。列表的标志性符号是[ ],那么元组的标志性符号是什么呢?当创建的元组里面只有一个元素时要在这个元素后面加上逗号,为了说明这个变量是元组,如果想要创建一个空元组那么就直接写tuple1=()就行,总的来说,逗号貌似是元组的标志,就算写为这样tuple2=1,2,3那么他的类型也是元组类型。对于元组和列表来说,乘号是重复操作符,将元组里面的元素重复乘以的数值。同样加号可以用来元组的拼接。
- 那么元组如何来更新呢?可以使用切片加拼接来更新一个元组,
temp=tuple1[:3]+("你好",)+tuple2[:]将得到:(1, 2, 3, '你好', 1, 2, 3)注意你好后面的·逗号不能丢,这个是用来说明它是一个元组的。如果有两个元素就不用在末尾加逗号了。 - 元组的删除,可以使用del语句,删除某个元素可以使用切片和拼接来操作。同样关系运算符也可以在元组中使用。
字符串:
- python中没有字符这个类型,同样对字符串进行操作也可以使用切片进行操作进而得到一个新的字符串。同样也可以像索引列表、元组元素一样,用索引来访问字符串中的某个元素。得到的一个字符也是字符串类型。字符串和元组一样,一旦被定义就无法添加或者删除元素,想要添加或者更新字符串可以使用切片和拼接进行操作。同样关系运算符in也适用于字符串,总的来说:字符串、列表、元组都是属于序列类型的。
因为字符串在程序中使用是非常常见的,所以字符串有很多方法。
capitalize(),把字符串的第一个字符改为大写,str1.capitalize()casefold(),把整个字符串改为小写, str1.casefold()center()将字符串居中,并使用空格填充至长度width的新字符串。tr1.center(20)count(sub[,start[,end]])返回sub子字符串在字符串里面出现的次数,start和end表示范围,可选。str1.count("o",0,2)或者str1.count("o")encode(encoding='utf-8',errors='strict')以encoding指定的编码格式对字符串进行编码。endswith(sub[,start[,end]])检查字符串是否有以sub子字符串结束,如果是返回True否则返回False,start和end参数表示范围,可选。str1.endswith('l')hello是以llo结尾或者lo结尾但不是l结尾所以返回False。expandtabs([tabsize=8])把字符串中的tab符号(\t)转化为空格,默认空格参数是tabsize=8,一个tab范围是8个字符。find(sub[,start[,end]])检测sub是否在字符串中,如果有返回索引值否则返回-1,start和end参数标识范围,可选。index(sub,[start,[,end]])和find方法一样,不过如果sub不在string中会产生一个异常isalnum()如果字符串至少有一个字符并且所有字符都是字母或者数字返回True,否则返回Falseisalpha()如果字符串至少有一个字符并且所有的字符都是字母则返回True,否则返回Falseisdecimal()如果字符串只包含十进制数字则返回True,否则返回Falseisdigit()如果字符串只包含数字返回True否则返回Falseislower()如果字符串中至少包含一个区分大小写的字符,并且这些字符都是小写,则返回True否则返回Falseisnumeric()如果字符串只包含数字字符,则返回True否则返回Falseisspace()如果字符串中只包含空格,则返回True否则返回Falseistitle()如果字符串是标题化(所有单词都是以大写开始,其余字母均小写),则返回True否则返回False。isupper()如果字符串中至少包含一个区分大小写的字符,并且这些字符都是大写则返回True否则返回Falsejoin(sub)以字符串作为分隔符,将sub插入到中所有的字符之间str1.join("hh")ljust(width)返回一个左对齐的字符串,并使用空格填充至长度为width的新字符串lower()将字符串中所有大写字符转化为小写lstrip()去掉字符串左边的所有空格partition(sub)找到字符串sub,把字符串分成一个3元组(pre_sub,sub,fol_sub),如果字符串中不包含sub则返回(‘原字符串’,’ ‘,’ ')replace(old,new[,count])把字符串中的old子字符串换成new子字符串,如果count指定,则替换不超过count次。rfind(sub,[start[,end]])类似于find方法,不过是从右边开始查找。rindex(sub,[,start[,end]])类似于index方法不过是从右边开始rjust(width)发送一个右对齐的字符串,并使用空格填充至长度为width的新字符串rpartition(sub)类似于partition方法,不过是从右边开始查找。rstrip()删除字符串末尾的空格split(sep=None,maxsplit=-1)不带参数默认是以空格为分隔符切片的字符串,如果maxsplit有参数设置,则仅分割maxsplit个子字符串,返回切片后的子字符串拼接成的列表。splitlines(([keepends]))按照\n分割,返回一个包含各行作为元素的列表,如果keepends参数指定,则返回前keepsends行startswith(prefix,[,start[,end]])检查字符串是否有以prefix开头,是则返回True,否则返回False,start和end参数可以指定范围检查,可选。strip([chars])删除字符串前边和后边的所有空格,chars参数可以定制删除的字符,可选。swapcase()翻转字符串的大小写title()返回标题化(所有单词都是以大写开始,其余字母均小写)的字符串。translate(table)根据table的规则(可以由str.maketrans(‘a’,‘b’)定制)转换字符串中的字符。举个栗子:str1="aaabbbsss",str1.translate(str.maketrans('a','s'))可以得到sssbbbsss这样的字符串。upper()转换字符串中的所有小写字母为大写zfill(width)返回长度为width的字符串,原字符串右对齐,前面用0填充。
字符串格式相关方法:
-
format()函数,这个函数里面有未知参数和已知参数,举个栗子:"{0} don't {1} you!".format("I","like")这里花括号括起来的叫做未知参数,再来个栗子:"{aa} don't {bb} you!".format(aa="I",bb="like")这里花括号括起来的叫做关键字参数,其实我感觉这个和C语言里面的占位符很像,但是他只是用于字符串的输出。那么怎么输出花括号呢?用双重花括号就可以了。那么再来看一下这个:"{0:.1f}{1}".format(32.66,"MB")输出结果:'32.7MB'这里的冒号表示格式化符号的开始,.1f表示四舍五入保留一位小数,格式化操作符有很多,如下图:
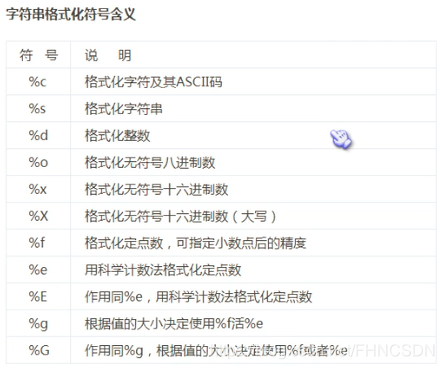
-
"%c %c %c"%(97,98,99)得到三个数字的ASCII值:'a b c' -
str2="hello" "%s" % str2得到:'hello' -
"%d + %d +%d=%d" % (1,2,3,1+2+3) 得到:'1 + 2 +3=6'
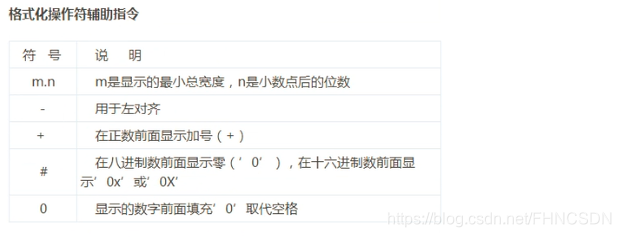
"%5.1f" % 3.14得到:' 3.1'这里的5表示这个字符串的最小有5个位置,小数点后面的1表示保留一位小数。如果有一个负号就不是这样了,例如:"%-5.1f" % 3.14得到:'3.1 '
序列:
列表、元组和字符串的共同点:
- 都是可以通过索引得到每一个元素
- 默认索引值总是从0开始
- 可以通过分片的方式得到一个范围内的元素集合
- 有很多共同的操作符(重复操作符、拼接操作符、成员关系操作符)
常见的序列BIF
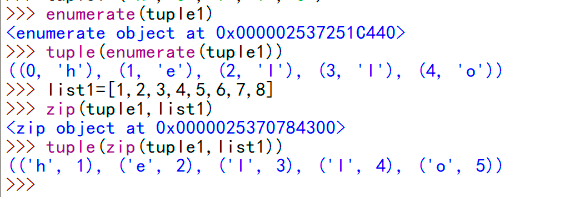
list()把一个可迭代(迭代: 重复反馈过程的活动,其目的通常是为了接近或者达到所需的目标或结果,每一次对过程重复称为一次迭代,每一次迭代的结果都会被用来下一次迭代的初始值)对象转换为列表,list()无参数是默认生成一个空的列表。tuple()把一个可迭代的对象转换为元组。无参数是默认生成一个空的元组。str()把它的参数转化为字符串len(sub),作用:返回序列的长度max(),作用:返回序列或者参数集合中的最大值,如果是字符的话就会比较其ASCII码,但是要注意使用max和min要保证所比较的数据类型都是一样的。min(),作用:返回序列或者参数集合中的最小值,如果是字符的话就会比较其ASCII码sum(iterable[,start=0])返回序列iterable和可选参数start的总和。同样保证所加的数据类型都是一样的,字符串不是数据类型,不能进行sum操作。sorted(),将序列默认从小到大排序reversed(),返回的是迭代器对象,可以通过list将序列逆转enumerate()这个函数作用是枚举,作用是生成由每元素的索引加元素本身组成的元组,例如:tuple(enumerate(tuple1))得到:((0, 'h'), (1, 'e'), (2, 'l'), (3, 'l'), (4, 'o'))zip(),返回由各个参数组成的元组,例如:下图
函数、对象、模块:
一:函数
- 定义一个函数使用def关键字,格式:
def MyFirstFunction():冒号后面根据函数的缩进可以得知函数的执行体。函数调用直接使用函数名加小括号进行调用例如:MyFirstFunction(),如果函数有参数,只需在括号内填写参数即可,调用时只需加上参数即可。还有就是函数的返回值:和C语言一样函数的返回使用关键字return,将所需要的数值返回。总的来说:python和C函数有点不同,python函数参数在定义时不用填写参数类型,定义时也不用填写返回值类型。 - 关键字参数就是你在定义函数时填写的形式参数名称,调用参数时可以通过关键字参数调用,这样函数就会按照关键字参数进行传参,而不是按照顺序。默认参数:是指在函数定义时给参数的默认值,如:
def MySecondFunction(a=3,b=5):这里的3和5就是默认参数在调用函数时如果有参数则使用给出的参数,没有参数则使用默认参数。搜集参数:就是可变参数定义方式:def MySecondFunction(*part):可以通过len(part)来计算参数的个数,并且可以通过part[元素下表]来访问参数。其实part就是一个元组作为函数的参数。
函数与过程:
- 严格来说,pyhton只有函数没有过程,python所有函数都会返回一个返回值,有返回值的返回返回值没有返回值的返回None。python可以返回多个数值通过列表或者元组。
- python参数的作用域问题,在函数里面定义的参数都称为局部变量,出了这个函数这些参数存储空间就会被释放。全局变量作用域是整个程序,在函数里面也可以访问全局变量,但是不要再函数内部试图去修改它,因为那样python会在函数内部新建一个和全局变量名字一样的局部变量代替。如果真的下想要在函数内部修改全局变量那么可以只用
global关键字先声明一下这个全局变量例如:global num 然后再修改num=...
内嵌函数和闭包:
内嵌函数: 允许在一个函数创建另一个函数,这种函数称为内嵌函数或内部函数。
栗子:
def func1():
print("这里是第一个函数:")
def func2():#定义第二个函数
print("这里是第二个函数:")
func2()#这里是在函数一内部调用函数二。
调用结果:
这里是第一个函数:
这里是第二个函数:
def func1():
print(1)
def func2():
print(2)
def func3():
print(3)
def func4():
print(4)
func4()
func3()
func2()
结果:
1
2
3
4
这里需要注意,在func1这个函数里面可以随意的调用func2但是出了这个func1函数,外边就不能调用func2。
闭包: 如果在一个内部函数对外部作用域(但不是在全局作用域的变量进行引用),那么内部函数就会被认为闭包。
栗子:
def Funx(x):
def Funy(y):
return x*y
return Funy
在这里说明一下:Funy相对于Funx来说是Funx的内部函数,funx就是funy的外部作用域
在Funy里面引用了Funx的变量x,所以Funy就是闭包
函数调用的时候:
如果 i=Funcx(5),那么此时i的类型就会变作function类型,然后可以i(2)再次调用计算得出10
除此之外还可以:Funcx(2)(3)这样调用
注意: 在外部的代码段仍然不能调用内部函数,在内部函数中只能对外部作用域的变量进行引用不能对其进行修改,就像全局变量和局部变量的关系,如下面的错误示例:
def Fun1():
x=5
def Fun2():
x*=5
return x
return Fun2()
此时对Func1调用会出现以下错误:
Traceback (most recent call last):
File "<pyshell#70>", line 1, in <module>
Fun1()
File "<pyshell#69>", line 6, in Fun1
Fun2()
File "<pyshell#69>", line 4, in Fun2
x*=5
UnboundLocalError: local variable 'x' referenced before assignment
那么有没有解决方案呢?
方案一:可以使用容器(列表,元组这些都是容器,他们不是存放在栈里面)
def Fun1():
x=[5]
def Fun2():
x[0]*=5
return x[0]
return Fun2()
方案二:使用关键字 nonlocal 就像之前用的global用法一样。nonlocal用来声明不是局部变量的
def Fun1():
x=5
def Fun2():
nonlocal x
x*=5
return x
return Fun2()
lambda表达式:
- python允许使用lambda关键字创建匿名函数,使用lambda关键字定义匿名函数:
lambda x: x**x冒号前面的是参数,冒号后面的是函数的返回值,当有多个参数时只需用逗号隔开。使用匿名函数只需要g=lambda x: x**x 将函数任意起一个名字然后调用: g(5) - 使用python写一些执行脚本的时候,使用lambda就可以省下定义函数的过程,比如说我们只需要写一个简单的脚本来管理服务器时间,我们就不需要专门定义一个函数然后再写调用,使用lambda就可以使得代码更加精简。
- 对于一些比较抽象的函数并且整个程序下来只需要调用一两次的函数,有时候给函数起个名字也是比较头疼的问题,使用lambda就不需要考虑命名问题了。
- 可以和lambda结合使用的两个BIF,第一个是:
filter()是过滤器(过滤掉False的内容)。filter有两个参数,第一个参数是一个函数或者None,第二个参数可迭代的数据。如果第一个参数是函数,则将第二个可迭代数据里的每一个元素作为元素的参数进行计算,把返回True的值筛选出来并成一个列表,如果第一个参数是None,则将第二个参数为True的数据筛选出来,变成一个列表。如下面栗子:
第一个参数为None的情况下:
filter(None,[1,2,0,False,True,"hello"])
<filter object at 0x00000253725D0BE0>返回的是一个对象
list(filter(None,[1,2,0,False,True,"hello"]))将返回的对象转换为列表
[1, 2, True, 'hello']
第一个参数是函数的情况下:
def odd(x):
return x%2
temp=range(10)
filter(odd,temp)
<filter object at 0x00000253725D0BE0>
list(filter(odd,temp))
[1, 3, 5, 7, 9]
lambda和filter()结合使用:
list(filter(lambda x:x%2,range(10)))
- 第二个常用的BIF:
map()map在编程中一般理解为映射的意思,map()这个函数也有两个参数,一个是函数和一个可迭代的序列,这个函数的功能是将序列的每一个元素作为函数的参数进行运算,直到序列元素全部加工完毕,返回一个加工后的新序列。举一个简单的例子:
list(map(lambda x:x**x,range(10)))
[1, 1, 4, 27, 256, 3125, 46656, 823543, 16777216, 387420489]
递归:
-
程序调用自身的编程技巧称为递归(
recursion)。递归作为一种算法在程序设计语言中广泛应用。一个方法或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。 -
python默认递归的深度是100层但是可以调用
sys.setrecursionlimit(参数自行设计)来得到自己想要的递归层数。下面举一个使用递归计算一个数的阶乘的例子:
def Func(x):
if x==1:
return 1
else:
return x*Func(x-1)
num=int(input("请输入要计算阶乘的数字:"))
print("得到结果:",Func(num))
如果输入数字5,则下面是递归过程:5层递归

递归举例:
利用迭代和递归计算菲波那切数列第20个数的值:
迭代方法:
def Func(n):
n1=1
n2=1
n3=1
if n<1:
print("输入有误!")
return -1
while(n-2)>0:
n3=n2+n1
n1=n2
n2=n3
n-=1
return n3
num=int(input("请输入要得到第几位数字:"))
ret=Func(num)
if ret!=-1:
print("数字是:",ret)
递归方法(递归方法效率比较低谨慎使用):
def Func(n):
if n<1:
print("输入有误!")
return -1
if n==1 or n==2:
return 1
else:
return Func(n-1)+Func(n-2)
num=int(input("请输入要得到第几位数字:"))
if Func(num)!=-1:
print(Func(num))
汉诺塔游戏:
def hanoi(n,x,y,z):
if n==1:
print(x,'--->',z)
else:
hanoi(n-1,x,z,y)#将前n减1个盘子从x移动到y上,中间的z参数就是起转换作用
print(x,'--->',z)#将第n个盘子从x移动到z上
hanoi(n-1,y,x,z)#将前n减1个盘子从y移动到z上,中间的x参数就是起转换作用
num=int(input("请输入汉诺塔的层数:"))
hanoi(num,'x','y','z')
这里:x,y,z表示三个柱子
如果输入参数3则会输出:
x ---> z
x ---> y
z ---> y
x ---> z
y ---> x
y ---> z
x ---> z
只要按照下面的方式进行移动就好。
字典:(当索引不好用时)
python的字典在很多地方也被称为哈希值。,字典是一种映射类型而不是序列类型。
- 创建和访问字典
dict1={
"李宁":"一切皆有可能","耐克":"Just do it"}
字典的创建用花括号,冒号之前的叫做键值(key)冒号之后的叫做对应的值(value)
print("李宁的口号是:",dict1["李宁"])------->李宁的口号是: 一切皆有可能
值可以通过键来访问
创建空字典:dict1{
}
dict()函数可以用来创建字典,这个函数只有一个参数
例子:
dict3=dict((("小明",100),("小王",90),("小张",100)))
这种方式是将元组当做dict函数的参数来创建字典,要求必须存在映射关系
dict4=dict(张三="80",李四="90")
这种方式是使用的关键字参数: =
如何给字典元素赋值或者改变键的值(当键不存在的时候,此时如果给键赋值那么将会创建一个新的键):
dict3['小明']=90 ----->{
'小明': 90, '小王': 90, '小张': 100}
若这个键没有:
dict3["小李"]=88 ------>{
'小明': 90, '小王': 90, '小张': 100, '小李': 88}
字典创建函数:
dict()函数:这个函数是一个工厂类型的函数。可以使用**fromkeys()**方法创建并返回一个新的字典,他有两个参数,第一个参数是字典的键,第二个参数是对应字典的值,如果第二个参数不提供的话,默认就是None。使用如下:
dict4={
}
dict4.fromkeys((1,2,3))#当第二个参数没有提供时
{
1: None, 2: None, 3: None}
dict4.fromkeys((1,2,3),'number')#当第二个参数有参数时,会将所有的键的值设为第二个参数的值
{
1: 'number', 2: 'number', 3: 'number'}
dict4.fromkeys((1,2,3),("one","two","three"))#当第二个参数有多个参数时,他并不会将键和值一一对应,而是将第二个参数看做一个整体,作为所有键的值。
{
1: ('one', 'two', 'three'), 2: ('one', 'two', 'three'), 3: ('one', 'two', 'three')}
当用fromkeys()试图修改一个字典的值时,他并不会将其值修改而是重新创建一个字典
字典的访问方法:
keys(),values(),items()
dic4={
"1":"one","2":"two","3":"three"}
dic4.keys()
dict_keys(['1', '2', '3'])
list(dic4.keys())
['1', '2', '3']
list(dic4.values())
['one', 'two', 'three']
list(dic4.items())
[('1', 'one'), ('2', 'two'), ('3', 'three')]
如果想要知道某个键是否在字典中,那么可以使用get()方法,如果不使用get()方法去访问字典中一个没有的键时,会报错,如下:
dic4={
"1":"one","2":"two","3":"three"}
dic4[4]
Traceback (most recent call last):
File "<pyshell#33>", line 1, in <module>
dic4[4]
KeyError: 4
如果使用get()方法:
dic4.get(4)他将不会报错只是返回一个None对象,如果想要他返回别的值同样
可以设置参数:dic4.get(4,"没有此键"),若找不到键时会返回"没有此键"
同样成员关系操作符也可以应用于字典当中,4 in dic4 则返回False
清空一个字典使用clear()方法:
dic4.clear()
setdefault()函数和get函数用法相似,只是他在字典中找不到时会新建键值对
b
{
'1': 'one', '3': 'three'}
b.setdefault("2")
b
{
'1': 'one', '3': 'three', '2': None}
同样可以给定键的值
b.setdefault("3","4")
'three'
b
{
'1': 'one', '3': 'three', '2': None}
update()方法:用一个字典去更新另一个字典
c={
"4":"four"}
b.update(c)
b
{
'1': 'one', '3': 'three', '2': None, '4': 'four'}
pop()(给定键弹出对应的值,那么键和值在字典里面就不见了)和popitem()(随机弹出一个键值对)区别:
a.popitem()
('3', 'three')
a
{
'1': 'one', '2': 'two'}
b
{
'1': 'one', '2': 'two', '3': 'three'}
b.pop('2')
'two'
b
{
'1': 'one', '3': 'three'}
浅拷贝和赋值:
浅拷贝得到的新的字典和原字典的地址不一样发生了改变,而赋值则和原来的地址是一样的,因为赋值就相当于有一个新的标签指向了字典,改变浅拷贝得到的字典不会影响到原字典而改变通过赋值得到的字典则会改变原字典。
dic4={
"1":"one","2":"two","3":"three"}
id(dic4)#查看id
2404516300160
a=dic4.copy()
b=dic4
id(a)
2404516299520
id(b)
2404516300160
集合:
用花括号括起来的一堆东西,但是花括号里面的东西没有映射关系,那么这个数据类型就是集合。集合有什么特点呢?在我的世界里你就是唯一。这和我们在数学中学到的集合也是一样的,集合里面没有重复的元素。集合不支持索引
如何创建一个集合?
- 一种是直接把一堆元素用花括号括起来,集合是无序的
- 一种是使用set()工厂函数,set的参数可以是一个列表,一个元组或者一个字符串。
set1={
1,2,3,4,5}
set1
{
1, 2, 3, 4, 5}
set2=set([1,2,3,4,5,5])
set2
{
1, 2, 3, 4, 5}
- 可以使用for把集合中的数据一个个读取出来
- 可以通过in和not in判断一个元素在集合中是否存在
- 可以使用add()方法为集合添加元素,
set2.add(6) - 同样可以使用remove()方法移除集合中的元素,
set2.remove(3) - 当我们希望集合中的元素不被改变时,可以使用
frozenset()方法定义集合
num=frozenset({
1,2,3,4,5}),得到:frozenset({
1, 2, 3, 4, 5}),此时集合是不可变的
智能推荐
874计算机科学基础综合,2018年四川大学874计算机科学专业基础综合之计算机操作系统考研仿真模拟五套题...-程序员宅基地
文章浏览阅读1.1k次。一、选择题1. 串行接口是指( )。A. 接口与系统总线之间串行传送,接口与I/0设备之间串行传送B. 接口与系统总线之间串行传送,接口与1/0设备之间并行传送C. 接口与系统总线之间并行传送,接口与I/0设备之间串行传送D. 接口与系统总线之间并行传送,接口与I/0设备之间并行传送【答案】C2. 最容易造成很多小碎片的可变分区分配算法是( )。A. 首次适应算法B. 最佳适应算法..._874 计算机科学专业基础综合题型
XShell连接失败:Could not connect to '192.168.191.128' (port 22): Connection failed._could not connect to '192.168.17.128' (port 22): c-程序员宅基地
文章浏览阅读9.7k次,点赞5次,收藏15次。连接xshell失败,报错如下图,怎么解决呢。1、通过ps -e|grep ssh命令判断是否安装ssh服务2、如果只有客户端安装了,服务器没有安装,则需要安装ssh服务器,命令:apt-get install openssh-server3、安装成功之后,启动ssh服务,命令:/etc/init.d/ssh start4、通过ps -e|grep ssh命令再次判断是否正确启动..._could not connect to '192.168.17.128' (port 22): connection failed.
杰理之KeyPage【篇】_杰理 空白芯片 烧入key文件-程序员宅基地
文章浏览阅读209次。00000000_杰理 空白芯片 烧入key文件
一文读懂ChatGPT,满足你对chatGPT的好奇心_引发对chatgpt兴趣的表述-程序员宅基地
文章浏览阅读475次。2023年初,“ChatGPT”一词在社交媒体上引起了热议,人们纷纷探讨它的本质和对社会的影响。就连央视新闻也对此进行了报道。作为新传专业的前沿人士,我们当然不能忽视这一热点。本文将全面解析ChatGPT,打开“技术黑箱”,探讨它对新闻与传播领域的影响。_引发对chatgpt兴趣的表述
中文字符频率统计python_用Python数据分析方法进行汉字声调频率统计分析-程序员宅基地
文章浏览阅读259次。用Python数据分析方法进行汉字声调频率统计分析木合塔尔·沙地克;布合力齐姑丽·瓦斯力【期刊名称】《电脑知识与技术》【年(卷),期】2017(013)035【摘要】该文首先用Python程序,自动获取基本汉字字符集中的所有汉字,然后用汉字拼音转换工具pypinyin把所有汉字转换成拼音,最后根据所有汉字的拼音声调,统计并可视化拼音声调的占比.【总页数】2页(13-14)【关键词】数据分析;数据可..._汉字声调频率统计
linux输出信息调试信息重定向-程序员宅基地
文章浏览阅读64次。最近在做一个android系统移植的项目,所使用的开发板com1是调试串口,就是说会有uboot和kernel的调试信息打印在com1上(ttySAC0)。因为后期要使用ttySAC0作为上层应用通信串口,所以要把所有的调试信息都给去掉。参考网上的几篇文章,自己做了如下修改,终于把调试信息重定向到ttySAC1上了,在这做下记录。参考文章有:http://blog.csdn.net/longt..._嵌入式rootfs 输出重定向到/dev/console
随便推点
uniapp 引入iconfont图标库彩色symbol教程_uniapp symbol图标-程序员宅基地
文章浏览阅读1.2k次,点赞4次,收藏12次。1,先去iconfont登录,然后选择图标加入购物车 2,点击又上角车车添加进入项目我的项目中就会出现选择的图标 3,点击下载至本地,然后解压文件夹,然后切换到uniapp打开终端运行注:要保证自己电脑有安装node(没有安装node可以去官网下载Node.js 中文网)npm i -g iconfont-tools(mac用户失败的话在前面加个sudo,password就是自己的开机密码吧)4,终端切换到上面解压的文件夹里面,运行iconfont-tools 这些可以默认也可以自己命名(我是自己命名的_uniapp symbol图标
C、C++ 对于char*和char[]的理解_c++ char*-程序员宅基地
文章浏览阅读1.2w次,点赞25次,收藏192次。char*和char[]都是指针,指向第一个字符所在的地址,但char*是常量的指针,char[]是指针的常量_c++ char*
Sublime Text2 使用教程-程序员宅基地
文章浏览阅读930次。代码编辑器或者文本编辑器,对于程序员来说,就像剑与战士一样,谁都想拥有一把可以随心驾驭且锋利无比的宝剑,而每一位程序员,同样会去追求最适合自己的强大、灵活的编辑器,相信你和我一样,都不会例外。我用过的编辑器不少,真不少~ 但却没有哪款让我特别心仪的,直到我遇到了 Sublime Text 2 !如果说“神器”是我能给予一款软件最高的评价,那么我很乐意为它封上这么一个称号。它小巧绿色且速度非
对10个整数进行按照从小到大的顺序排序用选择法和冒泡排序_对十个数进行大小排序java-程序员宅基地
文章浏览阅读4.1k次。一、选择法这是每一个数出来跟后面所有的进行比较。2.冒泡排序法,是两个相邻的进行对比。_对十个数进行大小排序java
物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)_网络调试助手连接阿里云连不上-程序员宅基地
文章浏览阅读2.9k次。物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)其实作者本意是使用4G模块来实现与阿里云物联网平台的连接过程,但是由于自己用的4G模块自身的限制,使得阿里云连接总是无法建立,已经联系客服返厂检修了,于是我在此使用网络调试助手来演示如何与阿里云物联网平台建立连接。一.准备工作1.MQTT协议说明文档(3.1.1版本)2.网络调试助手(可使用域名与服务器建立连接)PS:与阿里云建立连解释,最好使用域名来完成连接过程,而不是使用IP号。这里我跟阿里云的售后工程师咨询过,表示对应_网络调试助手连接阿里云连不上
<<<零基础C++速成>>>_无c语言基础c++期末速成-程序员宅基地
文章浏览阅读544次,点赞5次,收藏6次。运算符与表达式任何高级程序设计语言中,表达式都是最基本的组成部分,可以说C++中的大部分语句都是由表达式构成的。_无c语言基础c++期末速成