(超详细) Spark环境搭建(Local模式、 StandAlone模式、Spark On Yarn模式)-程序员宅基地
技术标签: 大数据学习之路 Spark学习之路 spark hadoop 大数据
Spark环境搭建
JunLeon——go big or go home

目录
目录
(4)配置log4j.properties 文件 [可选配置]
前言:
Spark部署模式主要有4种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、Spark On Yarn模式(使用YARN作为集群管理器)和Spark On Mesos模式(使用Mesos作为集群管理器)。
本教程做前三种环境搭建的详细讲解。
一、环境准备
1、软件准备
Linux:CentOS-7-x86_64-DVD-1708.iso
Hadoop:hadoop-2.7.3.tar.gz
Java:jdk-8u181-linux-x64.tar.gz
Anaconda:Anaconda3-2021.11-Linux-x86_64.sh
Spark:spark-2.4.0-bin-without-hadoop.tgz
2、Hadoop集群搭建
请查看 大数据学习——Hadoop集群完全分布式的搭建(超详细)_IT路上的军哥的博客-程序员宅基地_hadoop完全分布式搭建
注:本教程中使用Hadoop完全分布式集群,主机名分别为spark-master、spark-slave01、spark-slave02
3、Anaconda环境搭建
(1)下载Anaconda3
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
注:如果打不开网页,可以尝试换浏览器打开
(2)上传Anaconda的文件到Linux
上传到指定目录:/opt/software #没有的话就创建
(3)Anaconda On Linux 安装
在该目录下,执行Anaconda文件
cd /opt/software
sh ./Anaconda3-2021.11-Linux-x86_64.sh进入以下界面:直接回车即可
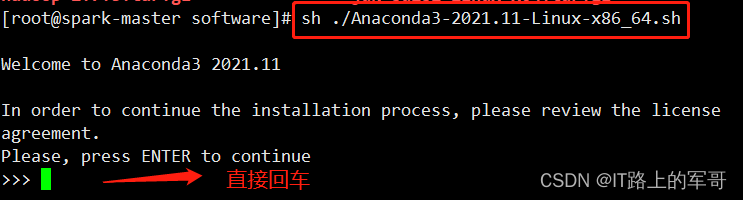
接下来 阅读许可条款 ,一直空格

在此处是询问是否同意许可条款,输入 yes

指定 anaconda3 安装路径:
将路径修改为
/opt/anaconda3目录下
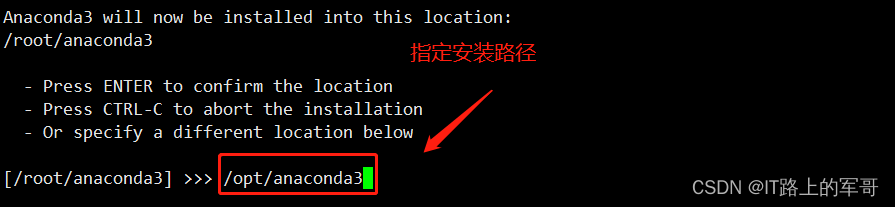
此处需要初始化,输入 yes

最后,使用exit退出远程连接工具,重新连接,如果出现以下base字样,说明安装成功!

注:base是默认的虚拟环境。
以上单台 Anaconda On Linux 环境搭建成功,即可开始安装spark。
(4)配置国内源:
vi ~/.condarc这个文件,追加以下内容:
注:该文件是一个空文件,直接添加即可
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud(5)创建pyspark环境
conda create -n pyspark python=3.6 # 基于python3.6创建pyspark虚拟环境
conda activate pyspark # 激活(切换)到pyspark虚拟环境注:如果执行 conda create -n pyspark python=3.6 命令下载失败,可能是你的虚拟机不能ping通网络,可以看看ping www.baidu.com是否能够ping通
(6)pip下载pyhive、pyspark、jieba包
在pyspark环境中使用pip下载pyhive、pyspark、jieba包
pip install pyspark==2.4.0 jieba pyhive -i https://pypi.tuna.tsinghua.edu.cn/simple二、Spark Local模式搭建
Spark Local模式也称单机或者本地模式,仅供测试用。并在spark-master主机进行操作。
1、Spark下载、上传和解压
(1)Spark版本下载
该环境搭建spark使用spark-2.4.0版本
(2)上传Spark压缩包
上传到指定目录:/opt/software
(3)解压上传好的压缩包
cd /opt/software
tar -zxvf spark-2.4.0-bin-without-hadoop.tgz -C /opt
mv spark-2.4.0-bin-without-hadoop/ spark-2.4.0解压之后进行重命名,重命名为
spark-2.4.0
2、配置环境变量
配置Spark由如下5个环境变量需要设置
-
SPARK_HOME: 表示Spark安装路径在哪里
-
PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
-
JAVA_HOME: 告知Spark Java在哪里
-
HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
-
HADOOP_HOME: 告知Spark Hadoop安装在哪里
这5个环境变量 都需要配置在: /etc/profile中
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_181
# HADOOP_HOME
export HADOOP_HOME=/opt/hadoop-2.7.3
# SPARK_HOME
export SPARK_HOME=/opt/spark-2.4.0
# HADOOP_CONF_DIR
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# PYSPARK_PYTHON
export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$PATHPYSPARK_PYTHON和JAVA_HOME 需要同样配置在: ~/.bashrc中
vi ~/.bashrc
# 默认启动pyspark虚拟环境
conda activate pyspark
# JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_181
# PYSPARK_PYTHON
export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python
export PATH=$JAVA_HOME/bin:$PATH配置好环境变量记得使文件生效:
source /etc/profile
source ~/.bashrc3、配置Spark配置文件
(1)spark-env.sh
cd /opt/spark-2.4.0/conf
cp spark-env.sh.template spark-env.sh在该文件最后追加以下内容:
export JAVA_HOME=/opt/jdk1.8.0_181
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.3/bin/hadoop classpath)4、测试
(1)验证Spark是否安装成功
pyspark进入pyspark虚拟环境后,输入pyspark后出现spark的logo则说明已成功:
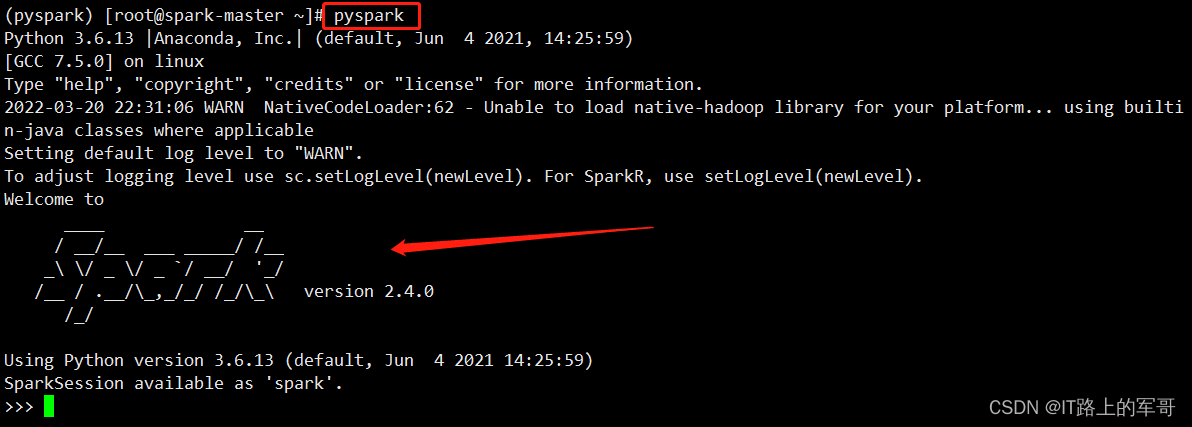
(2)运行Spark自带的Pi实例
run-example SparkPi
run-example SparkPi 2>&1 | grep "Pi is roughly" # 过滤日志信息(3)运行WordCount.py文件
在家目录下,创建一个.py文件,添加以下代码:
附:WordCount.py代码
# ~/WordCount.py
if __name__ == '__main__':
# 导入相关依赖包
from pyspark import SparkConf, SparkContext
# 创建SparkConf,创建一个SparkContext对象
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
# 设置文件路径
logFile = "file:///opt/spark-2.4.0/README.md"
# 负责读取README.md文件生成RDD
logData = sc.textFile(logFile, 2).cache()
# 统计RDD元素中包含字母a和字母b的行数
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
# 打印输出统计结果
print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))执行任务提交:
spark-submit ~/WordCount.py5、补充:spark-shell、spark-submit
(1)spark-shell
同样是一个解释器环境, 和pyspark不同的是, 这个解释器环境运行的不是python代码, 而是scala程序代码。
scala> sc.parallelize(Array(1,2,3,4,5)).map(x=> x + 1).collect()
res0: Array[Int] = Array(2, 3, 4, 5, 6)(2)spark-submit
作用: 提交指定的Spark代码到Spark环境中运行
使用方法:
# 语法
bin/spark-submit [可选的一些选项] jar包或者python代码的路径 [代码的参数]
# 示例
bin/spark-submit /opt/spark-2.4.0/examples/src/main/python/pi.py 10
# 此案例运行Spark官方所提供的示例代码,来计算圆周率值。后面的10是主函数接受的参数, 数字越高, 计算圆周率越准确。(3)pyspark、spark-shell、spark-submit对比
| 功能 | bin/spark-submit | bin/pyspark | bin/spark-shell |
|---|---|---|---|
| 功能 | 提交java\scala\python代码到spark中运行 | 提供一个python |
|
| 解释器环境用来以python代码执行spark程序 | 提供一个scala |
||
| 解释器环境用来以scala代码执行spark程序 | |||
| 特点 | 提交代码用 | 解释器环境 写一行执行一行 | 解释器环境 写一行执行一行 |
| 使用场景 | 正式场合, 正式提交spark程序运行 | 测试\学习\写一行执行一行\用来验证代码等 | 测试\学习\写一行执行一行\用来验证代码等 |
三、Spark StandAlone模式搭建
1、Hadoop集群与Spark集群节点规划
(1)集群主机名、IP规划
| 主机名 | IP地址 | 节点类型 |
|---|---|---|
| spark-master | 192.168.83.100 | Master |
| spark-slave01 | 192.168.83.101 | Slave |
| spark-slave02 | 192.168.83.102 | Slave |
(2)节点规划
| 节点进程 | spark-master | spark-slave01 | spark-slave02 |
|---|---|---|---|
| NameNode | |||
| Secondary NameNode | |||
| DataNode | |||
| ResourceManager | |||
| NodeManager | |||
| JobHistoryServer(YARN) | |||
| Master | |||
| Worker | |||
| HistoryServer(Spark) |
注:
JobHistoryServer:YARN资源管理器的历史服务器,将YARN运行的程序的历史日志记录下来,通过历史服务器方便用户查看程序运行的历史信息。
HistoryServer:Spark的历史服务器,将Spark运行的程序的历史日志记录下来, 通过历史服务器方便用户查看程序运行的历史信息。
2、三台虚拟机分别安装Anaconda3环境
此Anaconda环境搭建参考以上 环境准备中的第3点。也可以从第一台分发到另外两台:
scp -r /opt/anaconda3 root@spark-slava01:/opt
scp -r /opt/anaconda3 root@spark-slava02:/opt3、配置Spark配置文件
可以在spark-master主机操作,最后再进行分发。
注:Spark安装路径为:/opt/spark-2.4.0
spark配置文件路径为:/opt/spark-2.4.0/conf
cd /opt/spark-2.4.0/conf(1)配置spark-env.sh文件
# 1. 改名
mv spark-env.sh.template spark-env.sh
# 2. 编辑spark-env.sh, 在底部追加如下内容
vi spark-env.sh在spark-env.sh文件底部追加以下内容
## 设置JAVA安装目录
export JAVA_HOME=/opt/jdk1.8.0_181
## 设置hadoop命令路径
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.3/bin/hadoop classpath)
## 以上两行在local模式中已经添加,如果有请勿重复配置
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop
YARN_CONF_DIR=/opt/hadoop-2.7.3/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=spark-master
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://spark-master:9000/sparklog/ -Dspark.history.fs.cleaner.enabled=true"(2)配置spark-defaults.conf文件
# 1. 改名
mv spark-defaults.conf.template spark-defaults.confvi spark-defaults.conf # 2. 修改内容, 追加如下内容
# 开启spark的日期记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://spark-master:9000/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true(3)配置slaves文件(新版本为workers文件)
# 改名, 去掉后面的.template后缀
mv slaves.template slaves# 编辑worker文件 vi slaves # 将文件里面最后一行的localhost删除
追加从节点worker运行的服务器,配置三台主机名
spark-master
spark-slave01
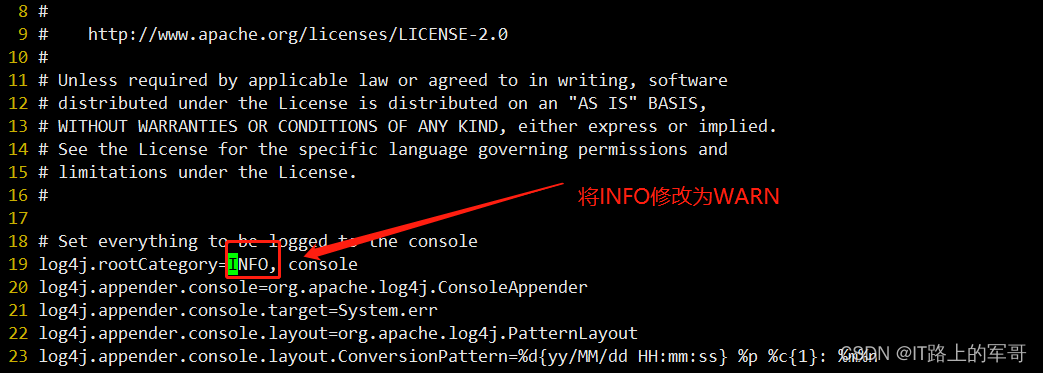
spark-slave02(4)配置log4j.properties 文件 [可选配置]
# 1. 改名
mv log4j.properties.template log4j.properties# 2. 修改内容 参考下图
vi log4j.properties定位到19行:将INFO修改为WARN
4、将配置好的spark分发到其他两台服务器上
将在spark-master主机上配置好的spark分发到另外两台服务器上:
scp -r /opt/spark-2.4.0/ root@spark-slave01:/opt/
scp -r /opt/spark-2.4.0/ root@spark-slave02:/opt/将主机的/etc/profile文件和~/.bashrc文件也同时分发到另外两台:
scp /etc/profile root@spark-slave01:/etc/
scp /etc/profile root@spark-slave02:/etc/
scp ~/.bashrc root@spark-slave01:~/
scp ~/.bashrc root@spark-slave02:~/分发过去之后需要分别在两台使配置文件生效:
source /etc/profile
source ~/.bashrc5、启动节点
1)启动Hadoop集群
start-all.sh # 只在spark-master主机上执行2)启动spark集群
cd /opt/spark-2.4.0/sbin
./start-all.sh开启全部节点后,如图所示:
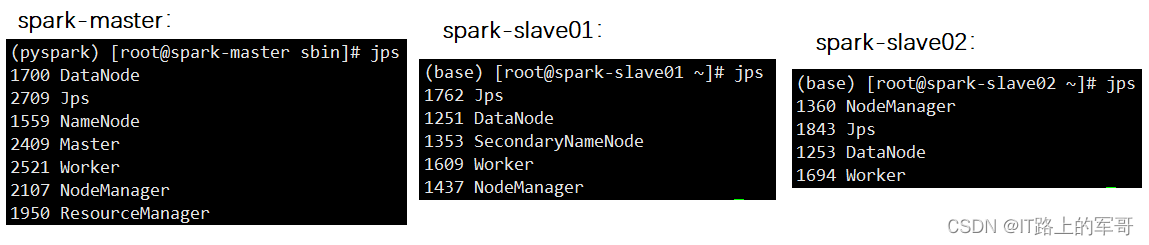
6、web端访问:
web端访问需要关闭防火墙:
systemctl stop firewalld1)访问HDFS
192.168.83.100:50070 # IP:端口号2)访问YARN
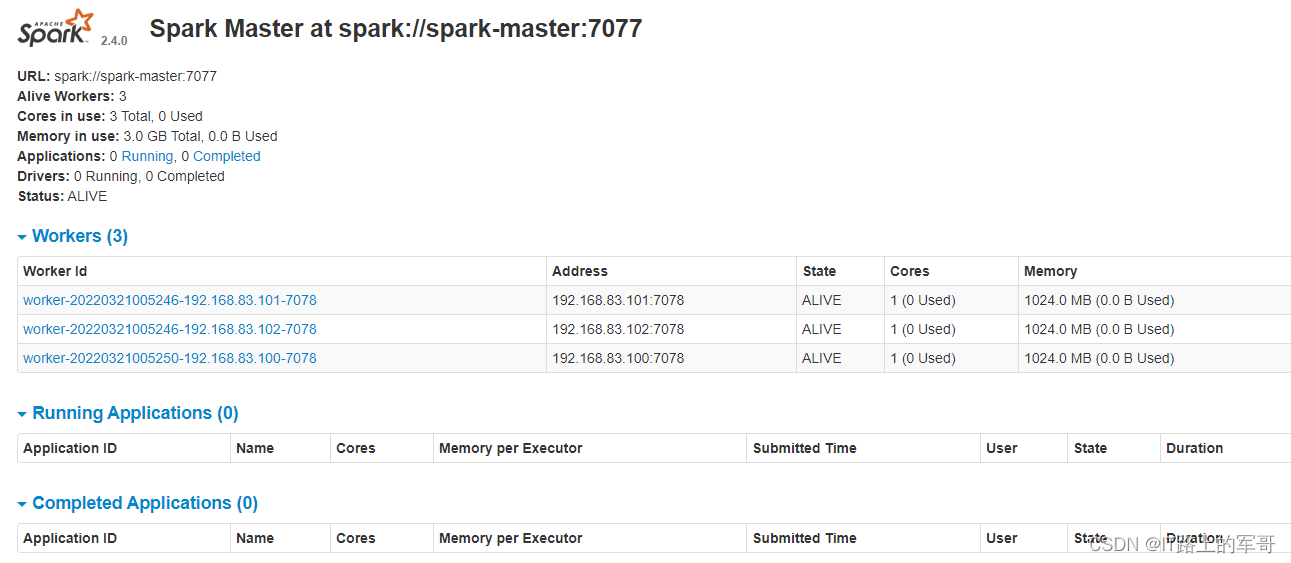
192.168.83.100:8088 # IP:端口号3)访问Spark
192.168.83.100:8080 # IP:端口号如图所示说明成功:
四、Spark On Yarn模式搭建
智能推荐
settext 下划线_Android TextView 添加下划线的几种方式-程序员宅基地
文章浏览阅读748次。总结起来大概有5种做法:将要处理的文字写到一个资源文件,如string.xml(使用html用法格式化)当文字中出现URL、E-mail、电话号码等的时候,可以将TextView的android:autoLink属性设置为相应的的值,如果是所有的类型都出来就是**android:autoLink="all",当然也可以在java代码里 做,textView01.setAutoLinkMask(Li..._qaction::settext 无法添加下划线
TableStore时序数据存储 - 架构篇_tablestore 时间类型处理-程序员宅基地
文章浏览阅读6.3k次,点赞2次,收藏10次。摘要: 背景 随着近几年物联网的发展,时序数据迎来了一个不小的爆发。从DB-Engines上近两年的数据库类型增长趋势来看,时序数据库的增长是非常迅猛的。在去年我花了比较长的时间去了解了一些开源时序数据库,写了一个系列的文章(综述、HBase系、Cassandra系、InfluxDB、Prometheus),感兴趣的可以浏览。背景随着近几年物联网的发展,时序数据迎来了一个不小的爆发。从DB..._tablestore 时间类型处理
Ubuntu20.04下成功运行VINS-mono_uabntu20.04安装vins-mono-程序员宅基地
文章浏览阅读5.7k次,点赞8次,收藏49次。可以编译成功但是运行时段错误查找原因应该是ROS noetic版本中自带的OpenCV4和VINS-mono中需要使用的OpenCV3冲突的问题。为了便于查找问题,我只先编译feature_tracker包。解决思路历程:o想着把OpenCV4相关的库移除掉,但是发现编译feature_tracker的时候仍然会关联到Opencv4的库,查找原因是因为cv_bridge是依赖opencv4的,这样导致同时使用了opencv3和opencv4,因此运行出现段错误。oo进一步想着(1)把vins-mon_uabntu20.04安装vins-mono
TMS320C6748_EMIF时钟配置_tms 6748-程序员宅基地
文章浏览阅读3.6k次,点赞3次,收藏12次。创龙TL6748开发板中,EMIFA模块使用默认的PLL0_SYSCLK3时钟,使用AISgen for D800K008工具加载C6748配置文件C6748AISgen_456M_config(Configuration files,在TL_TMS6748/images文件夹下),由图可以看到DIV3等于4,注意这里的DIV3就是实际的分频值(x),而不是写入相应PLL寄存器的值(x-1)。_tms 6748
eigen稀疏矩阵拼接(基于块操作的二维拼接)的思考-程序员宅基地
文章浏览阅读5.9k次,点赞4次,收藏13次。转载请说明出处:eigen稀疏矩阵拼接(块操作)eigen稀疏矩阵拼接(块操作)关于稀疏矩阵的块操作:参考官方链接 However, for performance reasons, writing to a sub-sparse-matrix is much more limited, and currently only contiguous sets of columns..._稀疏矩阵拼接
基于Capon和信号子空间的变形算法实现波束形成附matlab代码-程序员宅基地
文章浏览阅读946次,点赞19次,收藏19次。波束形成是天线阵列信号处理中的一项关键技术,它通过对来自不同方向的信号进行加权求和,来增强特定方向的信号并抑制其他方向的干扰。本文介绍了两种基于 Capon 和信号子空间的变形算法,即最小方差无失真响应 (MVDR) 算法和最小范数算法,用于实现波束形成。这些算法通过优化波束形成权重向量,来最小化波束形成输出的方差或范数,从而提高波束形成性能。引言波束形成在雷达、声纳、通信和医学成像等众多应用中至关重要。它可以增强目标信号,抑制干扰和噪声,提高系统性能。
随便推点
Ubuntu好用的软件推荐_ubuntu开发推荐软件-程序员宅基地
文章浏览阅读3.4w次。转自:http://www.linuxidc.com/Linux/2017-07/145335.htm使用Ubuntu开发已经有些时间了。写下这篇文章,希望记录下这一年的小小总结。使用Linux开发有很多坑,同时也有很多有趣的东西,可以编写一些自动化脚本,添加定时器,例如下班定时关机等自动化脚本,同时对于服务器不太了解的朋友,建议也可以拿台Linux来实践下,同时Ubuntu在Androi_ubuntu开发推荐软件
Nginx反向代理获取客户端真实IP_nginx获取到的是交换机的ip-程序员宅基地
文章浏览阅读2.2k次。一,问题 nginx反向代理后,在应用中取得的ip都是反向代理服务器的ip,取得的域名也是反向代理配置的url的域名,解决该问题,需要在nginx反向代理配置中添加一些配置信息,目的将客户端的真实ip和域名传递到应用程序中。二,解决 Nginx服务器增加转发配置 proxy_set_header Host $host;_nginx获取到的是交换机的ip
Wireshark TCP数据包跟踪 还原图片 WinHex应用_wireshark抓包还原图片-程序员宅基地
文章浏览阅读1.4k次。Wireshark TCP数据包跟踪 还原图片 WinHex简单应用 _wireshark抓包还原图片
Win8蓝屏(WHEA_UNCORRECTABLE_ERROR)-程序员宅基地
文章浏览阅读1.5k次。Win8下安装VS2012时,蓝屏,报错WHEA_UNCORRECTABLE_ERROR(P.S.新的BSOD挺有创意":("),Google之,发现[via]需要BIOS中禁用Intel C-State,有严重Bug的嫌疑哦原因有空再看看..._win8.1 whea_uncorrectable_error蓝屏代码
案例课1——科大讯飞_科大讯飞培训案例-程序员宅基地
文章浏览阅读919次,点赞21次,收藏22次。科大讯飞是一家专业从事智能语音及语音技术研究、软件及芯片产品开发、语音信息服务的软件企业,语音技术实现了人机语音交互,使人与机器之间沟通变得像人与人沟通一样简单。语音技术主要包括语音合成和语音识别两项关键技术。此外,语音技术还包括语音编码、音色转换、口语评测、语音消噪和增强等技术,有着广阔的应用。_科大讯飞培训案例
perl下载与安装教程【工具使用】-程序员宅基地
文章浏览阅读4.7k次。Perl是一个高阶程式语言,由 Larry Wall和其他许多人所写,融合了许多语言的特性。它主要是由无所不在的 C语言,其次由 sed、awk,UNIX shell 和至少十数种其他的工具和语言所演化而来。Perl对 process、档案,和文字有很强的处理、变换能力,ActivePerl是一个perl脚本解释器。其包含了包括有 Perl for Win32、Perl for ISAPI、PerlScript、Perl。_perl下载