BUAA_OO_2024 Unit-1总结-程序员宅基地
技术标签: java
1.0 前言
第一单元大致内容可以如下概括——
-
主要学习目标:初步掌握面向对象编程的思维方法,尤其是层次化设计的思想
-
核心任务:围绕表达式括号展开这一主题,完成三次迭代开发作业
在本人理解中,"层次化设计"的思想可谓本单元学习的重中之重:课程组缘何大费周章在练习题中、指导书中乃至实验中讲解递归下降文法分析的实现亦出于此。在本篇博客中,我会以"层次化设计"思想如何在我的代码架构下体现 为重点阐述自己在解决作业需求中的基本思路(1.1),基于idea插件MetricsReloaded的复杂度分析(1.2),debug与hack的经验(1.3)以及一点心得(1.4)。
注:代码分析部分(1.1)具有记录个人思考过程的色彩,为方便阅读建议酌情跳过(
2.0 UML类图+代码架构分析
2.1 第一次作业
需求分析:第一次作业主要任务是表达式括号展开,输入保证以常数因子(114514)、变量因子(x^8)、表达式因子为最小构成单元,且至多嵌套一层括号。
架构设计:一句话概括来说:预处理->表达式解析->表达式展开/计算->表达式输出四步走;其中解析在Expr, Term, Factor类这一"原始形态"进行,计算是将表达式统一转换到Polynomial类下进行
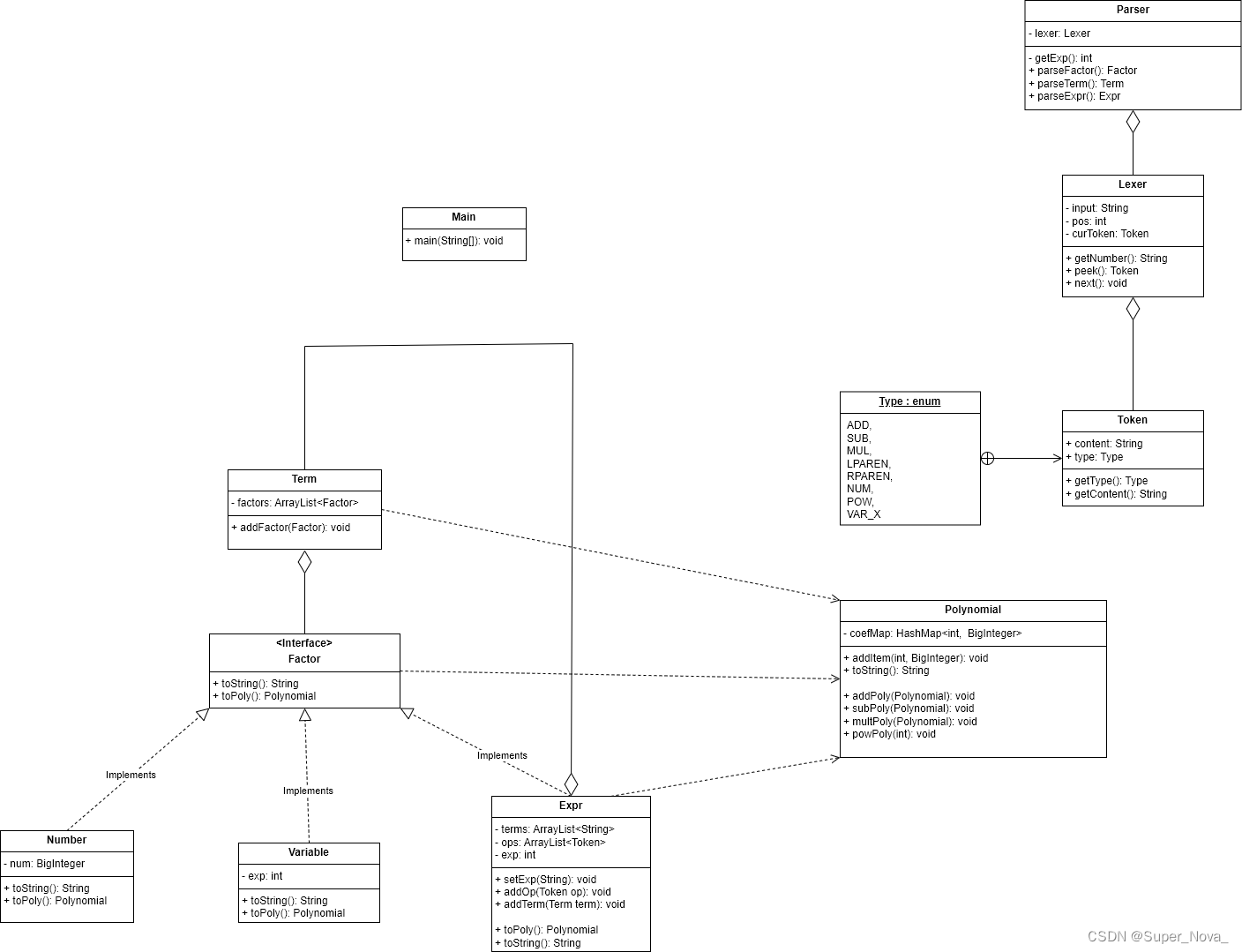
在这一次中我完成了架构的搭建,后续两次迭代都沿用了hw1的基本框架。第一次作业UML类图如下:
2.1.1 预处理
本次作业输入只有一行,预处理也比较简单,只完成两件事:去除空白符+合并连续正负号;如此以来后续便不涉及到处理空串的情况。
2.1.2 表达式解析:Token + Lexer + Parser
此处便不得不提OO课程组今年提供的实验以及oolens公众号对菜狗无微不至的关怀了orz(OO课程组伟大无需多言!)——其实这一步要干的事情很简单:用递归下降的方法解析出expr、term和factor的组成成分直至最简单的常数/变量因子,并采用容器存储下来。
2.1.3 表达式展开/计算:Polynomial
最开始的想法是将表达式的计算直接在Factor类中完成,但这样无疑会极大加重以上类的负担——因此,我在这一部分设了Polynomial(多项式)类,作为表达式计算、输出的统一"中转站" 。
Polynomial的转换
考虑到本次作业中构成Polynomial的Monomial(单项式)形式可统一为(BigInteger)coef * x ^ (int)exp,我在Polinomial类中以HashMap存储每个单项式,这样做的好处就是后续计算合并同类项十分方便。
// Polynomial.java
private final HashMap<Integer, BigInteger> exp2Coef = new HashMap<>();
// 以x的指数为Key,单项式系数coef为Value
随后要做的便是将Expr, Term, Factor转换到Polynomial这个统一形式下准备计算,即依次实现**toPoly()**方法。这对于只有一项的Number类与Varible类是十分轻松的;而Term和Expr类的toPoly()方法则同样需要递归下降。
Polinomial的计算
依次实现addPoly(), subPoly(), multPoly(), power()方法实现计算功能。
2.1.4 表达式输出
延续上一部分思路,Expr, Term, Factor的输出也同一到Polynomial的形式下,只对Polynomial实现一个toString()方法即可,具体实现比较简单,只需每项都按coef * x ^ exp输出,中间用+-连接。
2.2 第二次作业
第二次作业的新要求在于指数函数和自定义函数的引入~~,和往年的三角函数比着实友善不止一点~~。本质上来说,hw1中的基本架构是可以直接沿用的,故接下来重点围绕新增要求展开阐述。
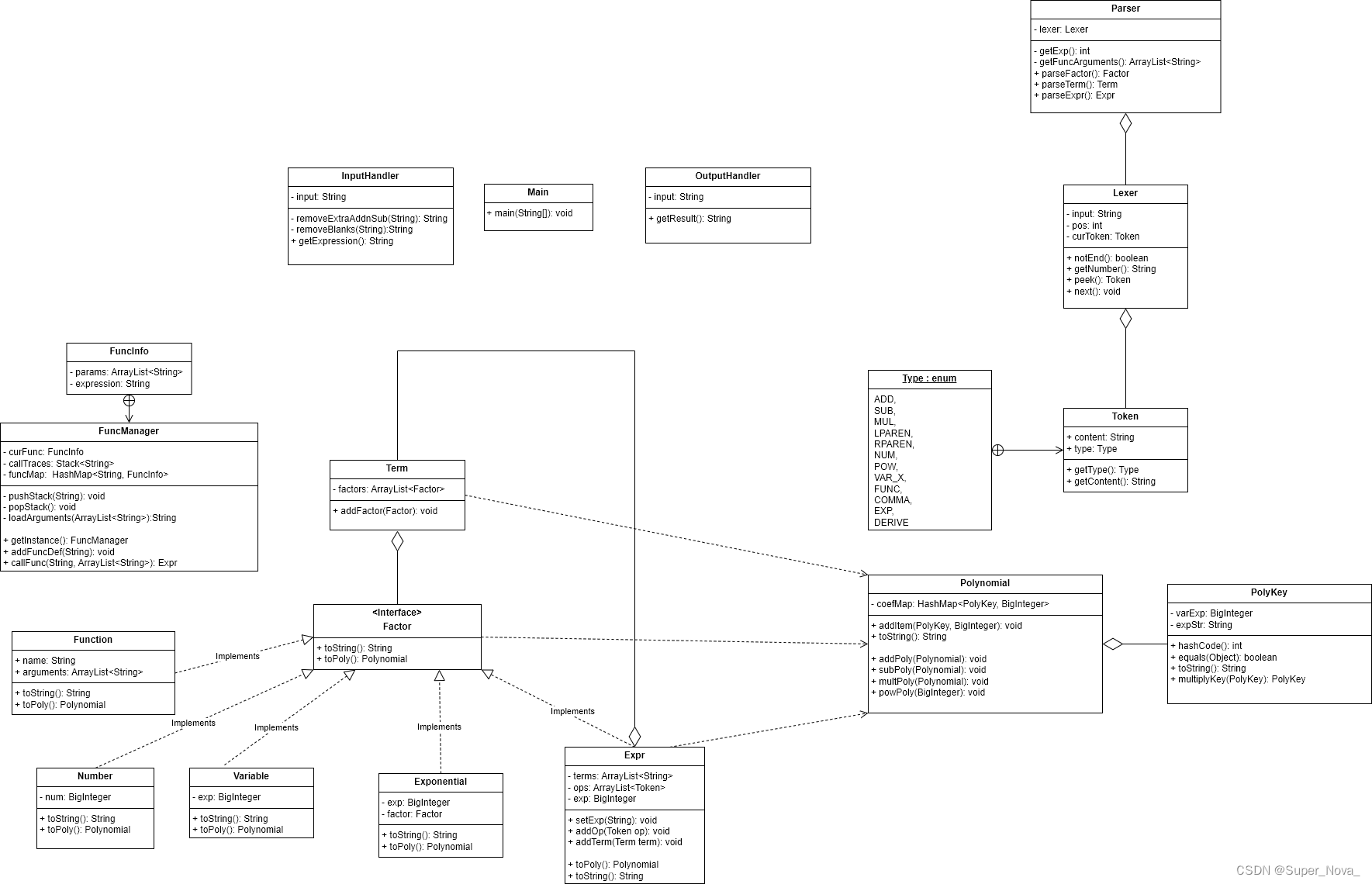
以下为第二次作业UML类图:
2.2.1 预处理部分
受理论课上荣老师的启发,这一次将输入输出分别封装到了新类InputHandler和OutputHandler中,以便简化主类Main的功能并利好后续扩展。其中InputHandler一方面完成hw1中输入表达式删除空白符和连续正负号的功能,另一方面传入函数定义。
2.2.2 自定义函数部分
**面对新要求时,我认为应当思考的第一件事是这一要求多大程度上影响了我们原来的架构设计。**自定义函数的加入虽然引入了不少复杂的细节,却并没有影响到基本的设计层次,所以对策便是在合理的位置实现合理的新功能。
处理自定义函数的基本策略:将函数实参(arguments)以字符串级替换的方法代替定义中的形参(parameters),再调用已有方法解析得到的表达式。具体实现思路就是围绕以下几个问题进行——
Q1: 如何优雅地、面向对象地管理函数定义与调用?
我新增了FuncManager类专门负责管理函数,其预期功能就是InputHandler处理输入的函数定义交给FuncManager,当Parser提供参数、函数名时得到结果。FuncManager类对外的public方法只有三种:
// FuncManager.java
public static FuncManager getInstance() {
return funcManager;
}
public void addFuncDef(String def) {
// ...
}
public Expr callFunc(String funcName, ArrayList<String> arguments) {
// ...
}
getInstance():FuncManager采用单例模式,对外提供getInstance()方法访问其唯一对象;addFuncDef():FuncManager采用此方法接受来自InputHandler类的函数定义输入,并维护出函数的形参列表和表达式——我采用了HashMap<String, FuncInfo> funcMap实现这一点,其中Key为函数名(String),Value为形参+表达式(内部类FuncInfo);callFunc():接受的两个参数:String funcName,ArrayList<String> arguments都来自于Parser类中的parseFactor()方法,即Parser类只负责处理出函数名与实参是什么,而根据定义将其转化为Expr类就是FuncManager类解决的问题了。
Q2: 如何安全地进行传参(字符串替换)?
直观地来想,我们的预期是传参就是将形参(x, y, z)同步地替换为对应实参——这种替换是字符串级别的,类似于C语言中的#define宏。此时就有可能出现以下问题:
-
exp中也有x,替换x时如何避免exp中的x被替换?
第一反应是把exp(以及后续的dx)全部替换为一个无关字符,完成传参后再恢复。不过出于更好的可扩展性考虑,也可以利用正则表达式中的
\b\B元字符,如\bx\b就可以仅匹配x。 -
我们的实参最终表达式中允许存在x,那么如何应对替换形参中可能引入新的x?(典型的例子:g(z, x) = z,带解析表达式:g(x, 1),如稍有不慎便会《意想不到地》解析出结果为"1" )
我们不希望"后来引入的x"被替换,所以只需将新引入的x替换为一个无关字符,完成后再恢复即可。
综上,我把以上功能封装在了private方法loadArguments(ArrayList<String>)中,长这样:
// FuncManager.java
private String loadArguments(ArrayList<String> arguments) {
String string = curFunc.expression.replaceAll("exp", "&");
string = string.replaceAll("dx", "#");
for (int i = 0; i < arguments.size(); i++) {
final String param = curFunc.params.get(i);
String arg = arguments.get(i).replaceAll("x", "@");
string = string.replaceAll(param, "(" + arg + ")");
}
string = string.replaceAll("&", "exp").replaceAll("#", "dx").replaceAll("@", "x");
return string;
}
Q3: 如何在嵌套调用时维护调用信息?
为了模拟一般函数调用过程,我在FuncManager类中维护了一个函数调用栈,并对内提供了pushStack()和popStack()方法;以上准备工作全部完结,最关键的callFunc(funcName,arguments)方法就以如下的简单形式呈现出来了:(个人认为还是相当优美的)
public Expr callFunc(String funcName, ArrayList<String> arguments) {
pushStack(funcName); // f/g/h
Parser newParser = new Parser(new Lexer(loadArguments(arguments)));
Expr expr = newParser.parseExpr();
popStack();
return expr;
}
2.2.3 指数函数
与自定义函数不同,指数函数的加入改变了单项式的基本形式,coef * x^(varExp) * exp(expStr);为了能基本沿用hw1的基本架构,我选择了对Polynomial中HashMap的Key进行重构。
具体做法:新建一个PolyKey类,维护x的指数BigInteger varExp与exp内的表达式String expStr——采用String类维护exp中的表达式是一个自然的选择,因为既然我们新建了一个PolyKey类作为HashMap的Key,就不可能绕开重写PolyKey类的equals()和hashcode()方法,而无疑采用String维护表达式时重写equals()与hashcode()成本是最小的。
另外,指数函数的引入可能导致Polynomial类中toString()和multPoly(Polynomial)方法复杂度大幅提高;为此,我在PolyKey类中分别实现toSring()和multKey(PolyKey)方法,Polynomial类相应方法中直接调用即可——由此观之,Polynomial类和PolyKey类之间是一个part-of的关系,这也是层次化设计的体现。
2.3 第三次作业
第三次作业这一次新要求只有两点:函数定义允许嵌套(hw2已能够实现)+新增求导因子
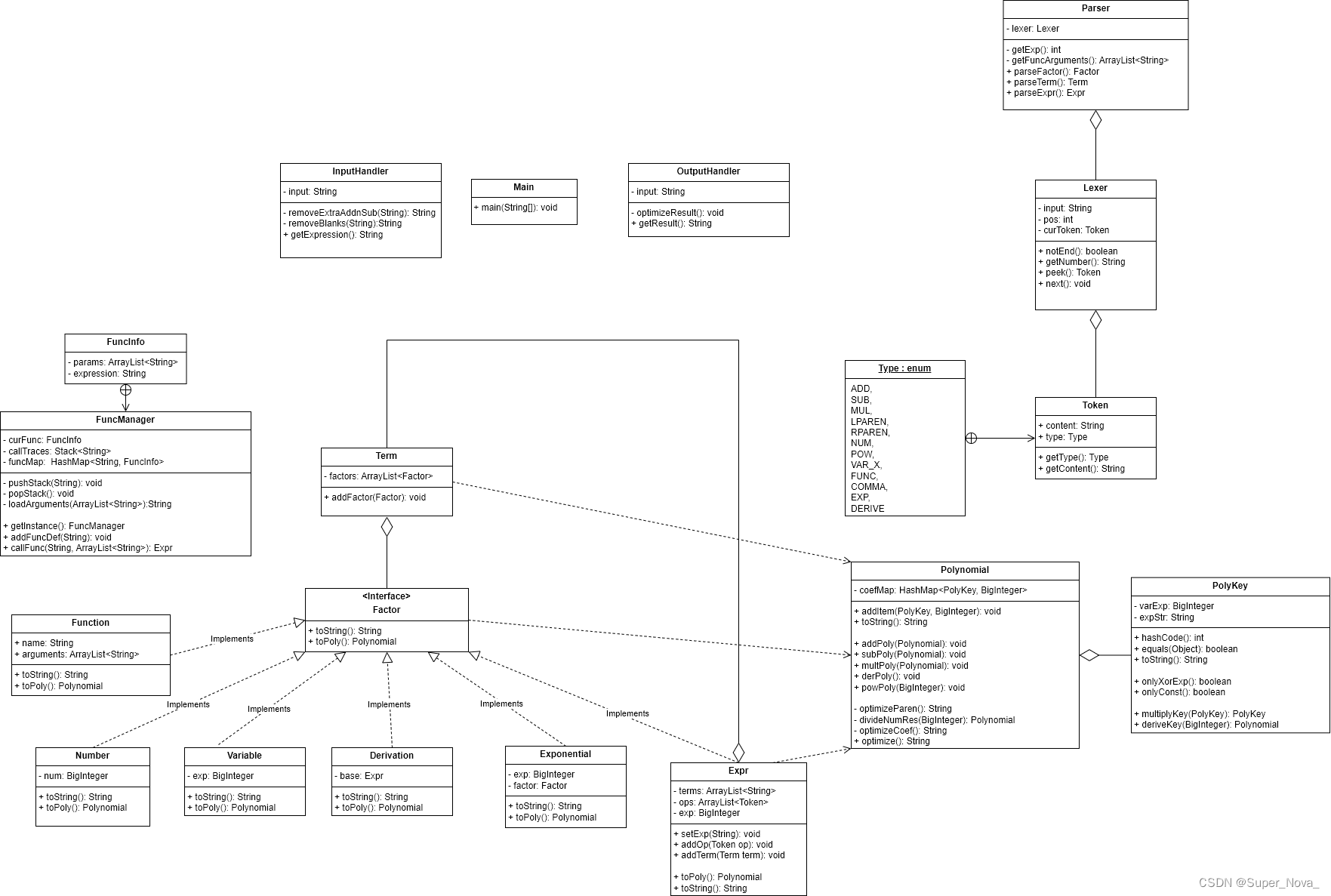
2.3.1 求导因子
对任何新增因子,还是按照hw1整体思路那样分两步:解析成分+计算结果。前者新建Factor类的实现Derivation类+修改Token, Lexer和Parser类相关部分即可;后者则于Polynomial类下进行。下面还是重点说明第二部分:计算。
直观来想,对Polynomial求导,相当于对其每一项求导结果相加;Polynomial类只需忠实地翻译这一点,因而该层求导的形式十分简单,而复杂的单项式求导细节则封装在了PolyKey的deriveKey()方法;PolyKey类的deriveKey()方法则重点关注coef * x^(varExp) * exp(expStr)的单项式求导展开,这同样是一个递归下降的计算过程,直接调用已有方法即可。
2.3.2 性能优化
这里的优化主要是两种形式下的优化:
- 一种是形如
exp((x*2)),可以优化为exp(x)^2,可以概括为"提指数去一层括号"——这一类是针对exp内只有一个单项式的情况; - 一种是形如
exp((100*x+200*x^2)),可以优化为exp((x+2*x^2))^100,可以概括为"提系数公因子"——这一类是针对exp内项数>=2, 并且提出所有项系数公因子后可以缩减输出长度的情况。
对第一种情况这里还是必须提醒自己"千万不能在潜在地牺牲正确性的情况下优化",必须严格按指导书要求+进行充分测试;第二种情况是受讨论区中cxc大佬的启发实现的,简单概括就是:可以验证最优解一定在提出的公因数为gcd/q, 1<=q<=9的情况中。
还有一个问题:优化放在哪里进行?起初为了图省事我直接把优化嵌入toString()方法中,很快发现一些复杂度并不算太高的数据会超时,所以将优化最终放在了OutputHandler类中——这也是更加符合面向对象思维的做法。
2.4 架构设计心得
第一周着手写作业时,我抱着毕其功于一役的想法上来便动手写代码,并且妄想将表达式的计算在解析过程中"顺便"完成——也即将计算整合入Parse类的方法中。事实证明这一想法引发了一场血光之灾,在后续一整天内我费尽周章完成最简单计算后便举步维艰,此时压力简直不输当年一周写完P5!但回头再来看,倘若起初便本着层次化设计的理念充分规划,其实是可以少走很多弯路的。
我将自己理解的"层次化设计"概括为以下两方面,总体来看与OO**“封装"与"抽象”**的特性紧密联系:
-
每一个类只负责自己的工作
Token,Lexer,Parser,Factor(Number, Variable, Expr等)类服务于表达式的解析,而Polynomial类则服务于计算与输出,从Factor到Polynomial的toPoly()方法搭建起了这两大部分功能的桥梁。将表达式解析与计算两大步骤分离开来,并建立起Polynomial类这一**“中转站”**是我个人设计的关键。
-
(方法)对外屏蔽具体实现细节
我认为这里是很能体现OO第一单元课程设计目标之处,也是递归下降法的理解要点。如果不能理解这一点,恐怕就会在parseExpr(),parseTerm()和parseFactor()的嵌套调用中顾虑重重——其实这与上一点本质上是统一的,只不过是从一个更微观的角度理解OO的"封装"特性。
3.0 程序复杂度分析
这一部分主要利用idea插件MetricsLoader进行复杂度分析(针对三次迭代完成后的最终结果)
3.1 分析维度
3.1.1 方法复杂度(Method Metrcis)
-
ev(G) - 基本复杂度:衡量程序非结构化程度。非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。
因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。
-
Iv(G) - 模块设计复杂度:衡量模块判定结构,即模块和其他模块的调用关系。 软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
-
v(G) - 圈复杂度:衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护。经验表明,程序的可能错误和高的圈复杂度有着很大关系。
-
cogC - 理解难度 :它将一段代码被阅读和理解时的复杂程度,估算成一个具体数字。出现"break"中止了线性的代码阅读理解,如出现循环、条件、try-catch、switch-case、一串的and or操作符、递归,以及jump to label:代码因此更复杂。
3.1.2 类复杂度(Class Metrcis)
- OCavg:类的方法的平均循环复杂度。
- OCmax:类的方法的最高循环复杂度。
- WMC:类的总循环复杂度。
3.2 Method Metrcis Analysis
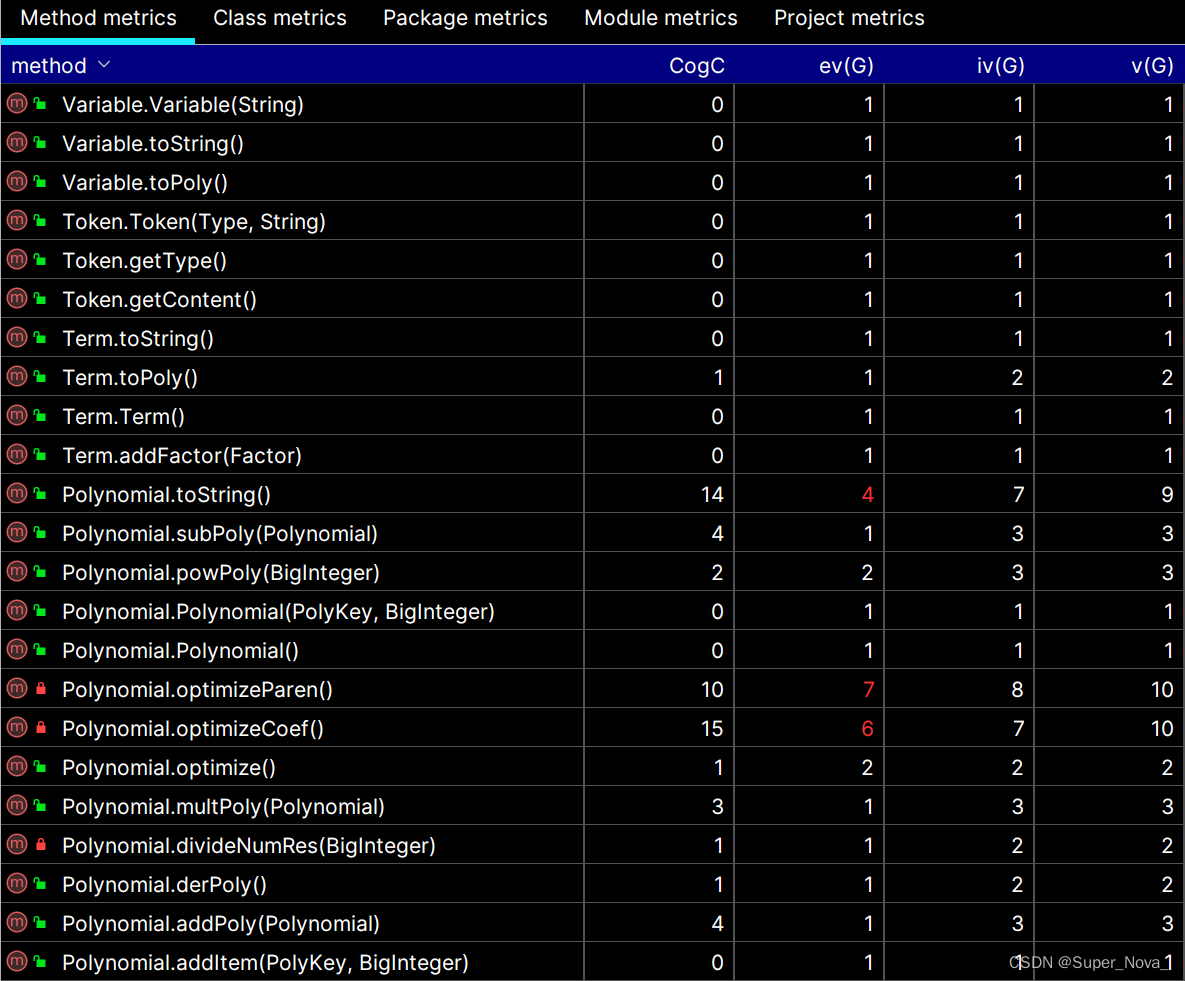
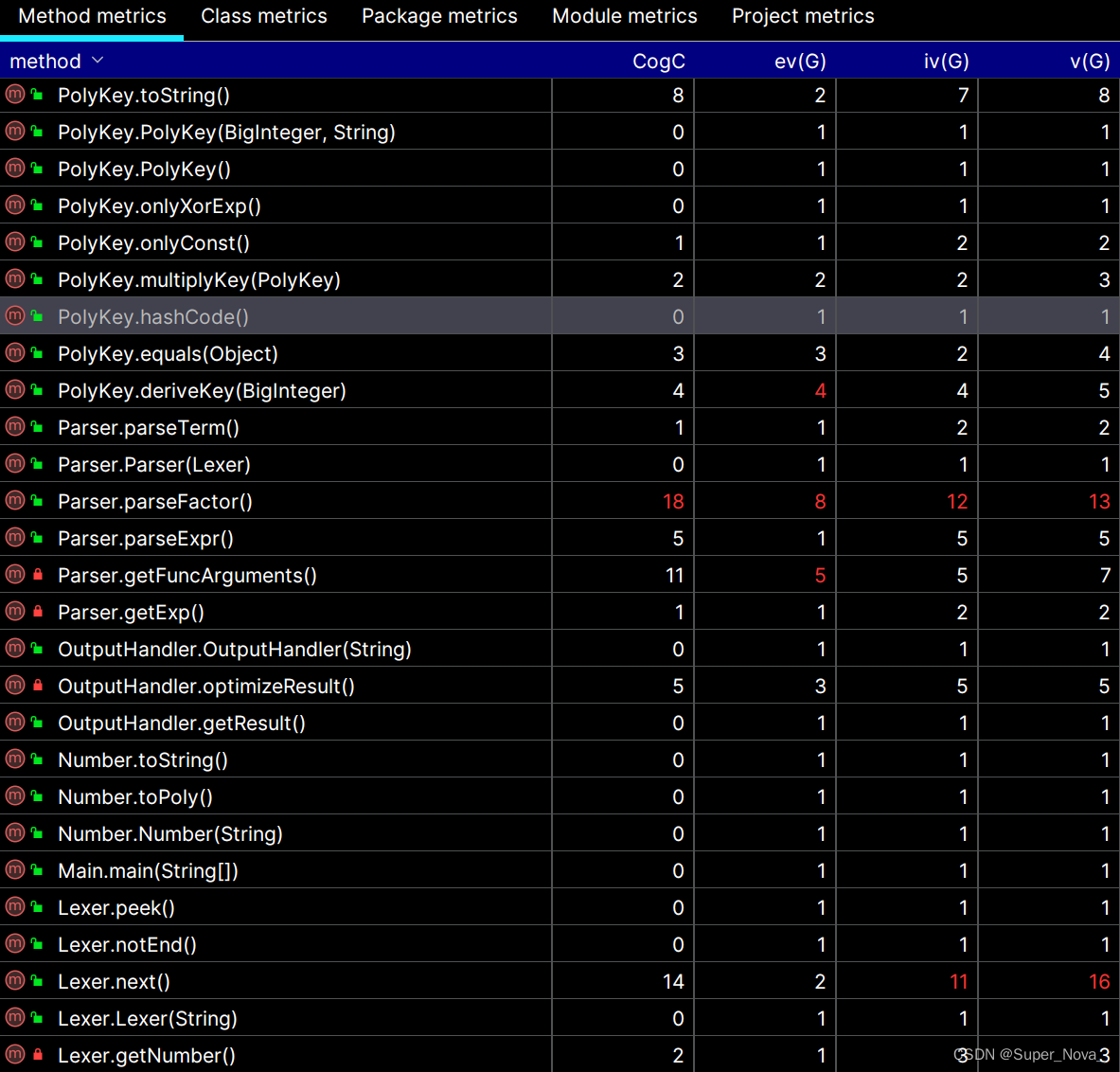
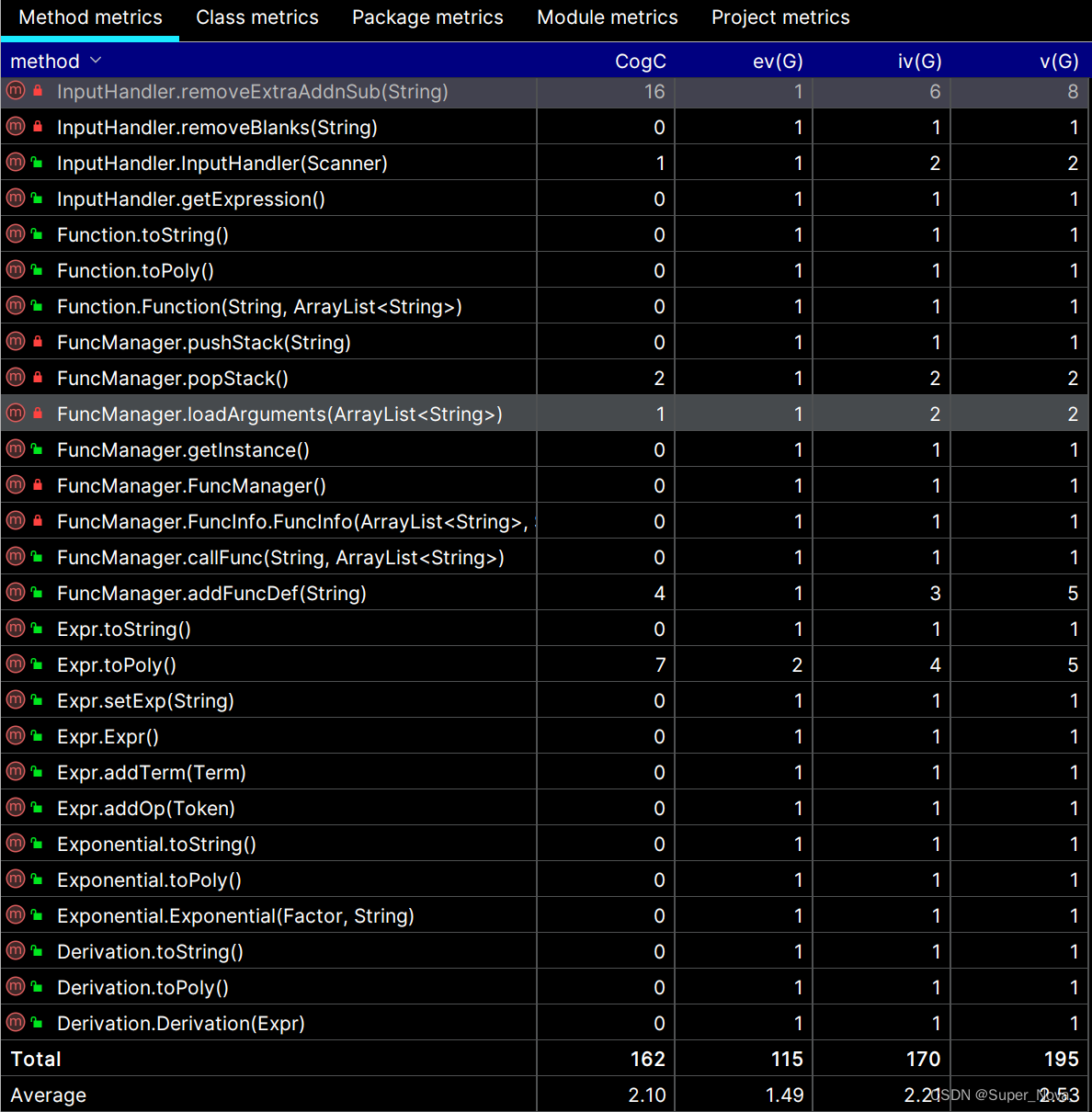
可以看出,方法复杂度整体看上去还是比较乐观的。 以下选取两个方法典型说明:
-
Lexer.next():iv(G)和v(G)较高,而cogC和ev(G)较低——这主要是因为该方法主体为一个12条分支的if语句,用于识别Token,所以耦合度较高,但好在功能清晰,理解起来十分容易。 -
Parser.ParseFactor():该方法算是四项指标全爆红的唯一重灾区了,因为该方法负责识别lexer.peek()的类型,并按照其类型的不同划分到Factor接口的若干实现并分块进行解析。为尽可能降低本方法的理解难度,我提取出了2个private类:
private int getExp(),private ArrayList<String> getFuncArgs();除此之外,当我意识到不破坏代码结构的前提下降低复杂度的工作已难以为继,便加入了大量注释辅助理解,大概像这样:(当然,最佳策略似乎应该是把每个if分支下都单独提出)public Factor parseFactor() { Token.Type type = lexer.peek().getType(); String content = lexer.peek().getContent(); if (type.equals(Token.Type.LPAREN)) { // *************** EXPRESSION *************** // lexer.next(); // ( Expr expr = parseExpr(); lexer.next(); // ) if (lexer.peek().getType().equals(Token.Type.POW)) { expr.setExp(String.valueOf(getExp())); } return expr; } else if (type.equals(Token.Type.NUM)) { // *************** NUMBER *************** // lexer.next(); return new Number(content); } // ... }
3.3 Class Metrics Analysis
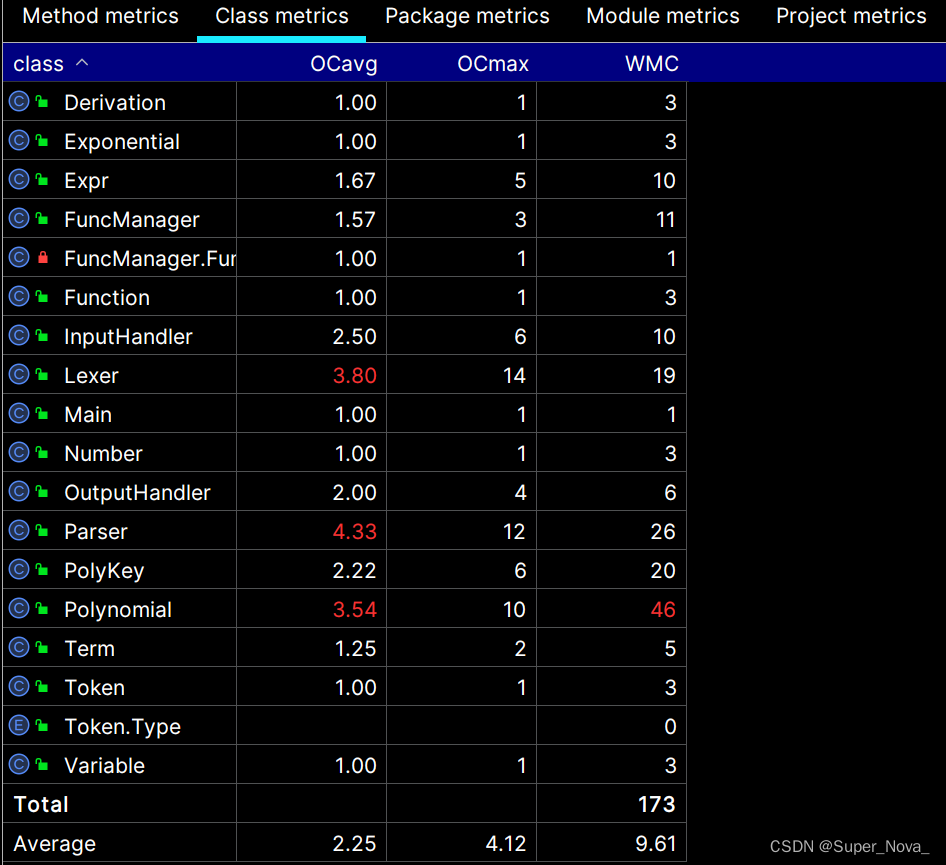
类复杂度的重灾区主要在Parser类与Polynomial类。前者主要是因为随着迭代中因子种类增加parseFactor()的复杂度也随之大大增加;而后者则是因为Polynomial类中同时有着计算(addPoly(Polynomial), multPoly(Polynomial)等),输出(toString())以及优化(optimizeParen(), optimizeCoef())三大功能的方法。
4.0 Bug & Hack
4.1 bug分析
本单元三次公测+互测中,最惨烈的毫无疑问是hw2——强测爆3个数据点,互测的同质bug也数不胜数…总结起来其实是两个问题:
4.1.1 int存指数的问题
hw1中,因存在至多嵌套一层括号的限制我用int存指数就苟过了所有测试数据,第二次题目要求中取消这一限制而我却忘了更正。事实上,hw1采用int存储指数的决策本身就是不可靠的——这种bug最好的避免方法就是在甲方无理地提出修改要求前未雨绸缪。
4.1.2 错误的优化/需求分析问题
exp((-x))我直接优化掉了一层括号,这是未能仔细、充分阅读指导书要求导致的;避免这种错误一方面要明确要求,一方面要在考虑优化时严格确保正确性!
4.1.3 递归下降的出口/剪枝问题
这一点拿出来特别强调,因为这是我在强测、互测结束后发现的bug(没错,未被hack到),故事从某A房数据点说起——
3
g(z)=exp(exp(exp(exp(z))))
f(y)=exp(exp(exp(exp(g(y)))))
h(x)=exp(exp(exp(exp(f(x)))))
h(f(g(exp(exp(exp(exp(x^8)))))))
不得不说这个数据看上去并不起眼,当我出乎意料发现自己竟十分钟跑不完第一反应是即将面对大规模重构经过观察CPU时间分布,我发现与其说我存在性能问题弗如说这是一个实实在在的bug,不妨简单解释:我的设计中,即便exp(x^8)转化为Term也必须经过相乘(*1)操作,里面有一段长这样:
// PolyKey.java
public PolyKey multiplyKey(PolyKey right) {
BigInteger varExp = this.varExp.add(right.varExp);
if (this.expStr.equals("0") && right.expStr.equals("0")) {
// EXIT
return new PolyKey(varExp, "0");
// 人话:只有左右两边exp()项**都**不存在才会退出递归过程
}
String newExpr = this.expStr + "+" + right.expStr;
Parser parser = new Parser(new Lexer(newExpr));
String expStr = parser.parseExpr().toPoly().toString(); // 再次解析`x^8+0`
return new PolyKey(varExp, expStr);
}
这个递归出口十分严格,导致出现如上特殊样例时递归的复杂度大增(有点像递归求fibonacci),修复的话再加一个简单剪枝就可以秒出结果了:
// PolyKey.java
public PolyKey multiplyKey(PolyKey right) {
// ...
// *** !!!!!MORE EXITS!!!!!! *** //
if (this.expStr.equals("0")) {
return new PolyKey(varExp, right.expStr);
}
if (right.expStr.equals("0")) {
return new PolyKey(varExp, this.expStr);
}
// ...
}
虽然最后《有惊无险》没被hack,但这一处bug于我还算是相当有启发的(不得不承认此前着实小看了此样例背后的创造力
4.2 hack小经验
经过第一单元三次互测,我认为所有hack策略大抵都处在下面两极之间:
- "饱和轰炸式"hack:基本方法就是将程序交给本地评测机大量跑数据;这样做的优点是省心又省时,缺点是很多时候只能发现一些简单、基本的bug,在A房内可能难有用武之地;
- "外科手术式"hack:这类hack需要针对目标程序源代码的设计缺陷手捏数据精准打击——虽然杀伤力十足但显然分析源代码需要大量时间(
遑论阅读他人架构时情不自禁的血压飙升
毫无疑问绝对地采用二者之一都不可取,我认为最佳方法应该是结合起来:在总结提炼一些常见易错点的基础上,有的放矢地构造样例+阅读代码。
一个成功的案例是hw2因讨论区有提出一种可能优化:将exp()中的表达式提取某个公因子为指数;此时就存在一个极不合理的策略:为了寻找使结果最短的那个因子,对最大公因子gcd再次分解质因数甚至直接从1开始遍历。
针对这一点我输入测试样例:exp((188167972192200*x+282251958288300*exp(x^2))),果然发现一个程序TLEhack成功;阅读发现其代码中有这样的片段,验证了我的猜想:
private BigInteger GetBestNum(BigInteger gcd) {
// ...
for (; num.compareTo(gcd) <= 0; num = num.add(BigInteger.ONE)) {
if (!gcd.remainder(num).equals(BigInteger.ZERO)) {
continue;
}
// ...
return bestNum;
}
5.0 心得体会
主要的 [架构设计心得](# 2.4 架构设计心得) 已在上文总结,下面总结一些零散的心得:
- 优先进行充分分析、规划与设计,不急于实现
- 善于利用课程组&讨论区&往年学长学姐提供的宝贵资源
- 程序的结构的完整性、正确性 > 性能分
本学期OO的Unit1到此就告一段落了,在完成三次迭代练习的过程中我也不断追问自己:我们到底在学什么?答案一定是(至少不止于)简单完成三次作业,更多地是了解一般面向对象的开发模式,尤其是体会面向对象的设计与构造思想;尽管课程组不可能面面俱到地模拟出未来工作的情境,但至少能利用好现有舞台深度体验正确性、简洁性、可扩展性、性能之间的trade-off,在反复实践中逐步实现从小镇做题家到卓越工程师的伟大飞越!
智能推荐
Docker 快速上手学习入门教程_docker菜鸟教程-程序员宅基地
文章浏览阅读2.5w次,点赞6次,收藏50次。官方解释是,docker 容器是机器上的沙盒进程,它与主机上的所有其他进程隔离。所以容器只是操作系统中被隔离开来的一个进程,所谓的容器化,其实也只是对操作系统进行欺骗的一种语法糖。_docker菜鸟教程
电脑技巧:Windows系统原版纯净软件必备的两个网站_msdn我告诉你-程序员宅基地
文章浏览阅读5.7k次,点赞3次,收藏14次。该如何避免的,今天小编给大家推荐两个下载Windows系统官方软件的资源网站,可以杜绝软件捆绑等行为。该站提供了丰富的Windows官方技术资源,比较重要的有MSDN技术资源文档库、官方工具和资源、应用程序、开发人员工具(Visual Studio 、SQLServer等等)、系统镜像、设计人员工具等。总的来说,这两个都是非常优秀的Windows系统镜像资源站,提供了丰富的Windows系统镜像资源,并且保证了资源的纯净和安全性,有需要的朋友可以去了解一下。这个非常实用的资源网站的创建者是国内的一个网友。_msdn我告诉你
vue2封装对话框el-dialog组件_<el-dialog 封装成组件 vue2-程序员宅基地
文章浏览阅读1.2k次。vue2封装对话框el-dialog组件_
MFC 文本框换行_c++ mfc同一框内输入二行怎么换行-程序员宅基地
文章浏览阅读4.7k次,点赞5次,收藏6次。MFC 文本框换行 标签: it mfc 文本框1.将Multiline属性设置为True2.换行是使用"\r\n" (宽字符串为L"\r\n")3.如果需要编辑并且按Enter键换行,还要将 Want Return 设置为 True4.如果需要垂直滚动条的话将Vertical Scroll属性设置为True,需要水平滚动条的话将Horizontal Scroll属性设_c++ mfc同一框内输入二行怎么换行
redis-desktop-manager无法连接redis-server的解决方法_redis-server doesn't support auth command or ismis-程序员宅基地
文章浏览阅读832次。检查Linux是否是否开启所需端口,默认为6379,若未打开,将其开启:以root用户执行iptables -I INPUT -p tcp --dport 6379 -j ACCEPT如果还是未能解决,修改redis.conf,修改主机地址:bind 192.168.85.**;然后使用该配置文件,重新启动Redis服务./redis-server redis.conf..._redis-server doesn't support auth command or ismisconfigured. try
实验四 数据选择器及其应用-程序员宅基地
文章浏览阅读4.9k次。济大数电实验报告_数据选择器及其应用
随便推点
灰色预测模型matlab_MATLAB实战|基于灰色预测河南省社会消费品零售总额预测-程序员宅基地
文章浏览阅读236次。1研究内容消费在生产中占据十分重要的地位,是生产的最终目的和动力,是保持省内经济稳定快速发展的核心要素。预测河南省社会消费品零售总额,是进行宏观经济调控和消费体制改变创新的基础,是河南省内人民对美好的全面和谐社会的追求的要求,保持河南省经济稳定和可持续发展具有重要意义。本文建立灰色预测模型,利用MATLAB软件,预测出2019年~2023年河南省社会消费品零售总额预测值分别为21881...._灰色预测模型用什么软件
log4qt-程序员宅基地
文章浏览阅读1.2k次。12.4-在Qt中使用Log4Qt输出Log文件,看这一篇就足够了一、为啥要使用第三方Log库,而不用平台自带的Log库二、Log4j系列库的功能介绍与基本概念三、Log4Qt库的基本介绍四、将Log4qt组装成为一个单独模块五、使用配置文件的方式配置Log4Qt六、使用代码的方式配置Log4Qt七、在Qt工程中引入Log4Qt库模块的方法八、获取示例中的源代码一、为啥要使用第三方Log库,而不用平台自带的Log库首先要说明的是,在平时开发和调试中开发平台自带的“打印输出”已经足够了。但_log4qt
100种思维模型之全局观思维模型-67_计算机中对于全局观的-程序员宅基地
文章浏览阅读786次。全局观思维模型,一个教我们由点到线,由线到面,再由面到体,不断的放大格局去思考问题的思维模型。_计算机中对于全局观的
线程间控制之CountDownLatch和CyclicBarrier使用介绍_countdownluach于cyclicbarrier的用法-程序员宅基地
文章浏览阅读330次。一、CountDownLatch介绍CountDownLatch采用减法计算;是一个同步辅助工具类和CyclicBarrier类功能类似,允许一个或多个线程等待,直到在其他线程中执行的一组操作完成。二、CountDownLatch俩种应用场景: 场景一:所有线程在等待开始信号(startSignal.await()),主流程发出开始信号通知,既执行startSignal.countDown()方法后;所有线程才开始执行;每个线程执行完发出做完信号,既执行do..._countdownluach于cyclicbarrier的用法
自动化监控系统Prometheus&Grafana_-自动化监控系统prometheus&grafana实战-程序员宅基地
文章浏览阅读508次。Prometheus 算是一个全能型选手,原生支持容器监控,当然监控传统应用也不是吃干饭的,所以就是容器和非容器他都支持,所有的监控系统都具备这个流程,_-自动化监控系统prometheus&grafana实战
React 组件封装之 Search 搜索_react search-程序员宅基地
文章浏览阅读4.7k次。输入关键字,可以通过键盘的搜索按钮完成搜索功能。_react search