PyTorch学习笔记(5)——论一个torch.Tensor是如何构建完成的?_aten/aten.h-程序员宅基地
技术标签: PyTorch框架学习 PyTorch
最近在准备学习PyTorch源代码,在看到网上的一些博文和分析后,发现他们发的PyTorch的Tensor源码剖析基本上是0.4.0版本以前的。比如说:在0.4.0版本中,你是无法找到
a = torch.FloatTensor()中FloatTensor的usage的,只能找到a = torch.FloatStorage()。这是因为在PyTorch中,将基本的底层THTensor.hTHStorage.h都放在名为Aten的后端中了(TH是torch7下面的一个重要的库),并将之前放在torch/csrc/generic中的Tensor.h删除。即相比之前做了模块解耦的工作。
0.前言(楔子)
我们知道,PyTorch中的Tensor的底层数据结构是Storage。那么Storage是什么?其实很简单,Storage是一个连续(对应内存中的一段连续地址)的一维数组,且里面的元素类型是一样的(比如都为Int,Float等)。容易理解,Tensor就是维度上Storage的扩展。
前面提到,基于PyTorch 0.4.0版本及目前最新的开源代码中,我发现:用户是无法找到a = torch.FloatTensor()中FloatTensor的usage的,只能找到a = torch.FloatStorage()。PyTorch开发者为了避免冗杂代码,所以在torch/csrc/generic中,将Tensor.h和Tensor.cpp都删掉了。只保留了Storage.h和Storage.cpp,注意csrc目录的作用:
将ATen中的基于torch 7的原生THTensor转换为Torch Python的THPTensor
什么是THTensor,什么是THPTensor,包括后面还会见到的如THDPTensor、THCSPTensor等,都会在后面介绍。
下面,我将从源码中找到Storage,并逐步分析,究竟它是如何被封装成我们日常使用的torch.FloatTensor等类型的。
class DoubleStorage(_C.DoubleStorageBase, _StorageBase):
pass
class FloatStorage(_C.FloatStorageBase, _StorageBase):
pass
...
class IntStorage(_C.IntStorageBase, _StorageBase):
pass
不过,为了更好的学习代码,我们需要一些预备知识:
- 1)Python如何拓展C/C++库
- 2)Python的实现机制
这些内容将放在本笔记最后,我将使用常见的API,用C语言写module,然后被Python调用的例子进行展示。
1. 在Python扩展C
由class IntStorage(_C.IntStorageBase, _StorageBase): 可以看出,IntStorage
关于这块的详细介绍将在最后介绍,Pytorch中的拓展模块定义代码主要在torch/csrc/Module.cpp中,直接在Module.cpp找到我们关注的地方来进行说明:
#include "torch/csrc/python_headers.h"
#include <ATen/ATen.h>
#include "THP.h"
#ifdef USE_CUDNN
#include "cudnn.h"
#endif
#ifdef USE_C10D
#include "torch/csrc/distributed/c10d/c10d.h"
#endif
...
#define ASSERT_TRUE(cmd) if (!(cmd)) return NULL
...
static PyObject* initModule() {
...
#if PY_MAJOR_VERSION == 2
ASSERT_TRUE(module = Py_InitModule("torch._C", methods.data()));
// python3不支持Py_InitModule.
// 现在, 用户可以创建一个PyModuleDef structure,并将其引用传递给 PyModule_Create.
#else
static struct PyModuleDef torchmodule = {
PyModuleDef_HEAD_INIT,
"torch._C",
NULL,
-1,
methods.data()
};
...
}
...
// 各种Torch Python类型的Storage初始化
ASSERT_TRUE(THPDoubleStorage_init(module));
ASSERT_TRUE(THPFloatStorage_init(module));
ASSERT_TRUE(THPHalfStorage_init(module));
ASSERT_TRUE(THPLongStorage_init(module));
...
#if PY_MAJOR_VERSION == 2
PyMODINIT_FUNC init_C()
#else
PyMODINIT_FUNC PyInit__C()
#endif
{
#if PY_MAJOR_VERSION == 2
initModule();
#else
return initModule();
#endif
}
// 到达结尾
那几个头文件很重要,#include <ATen/ATen.h>是因为PyTorch的很多模块,即这里要分析的Storage就是基于ATen中的TH,TH表示Torch,因为PyTorch是从Torch 7移植过来的。相应地,THP表示Torch Python。TH和 THP的转换定义在torch/csrc下的头文件#include "THP.h"。
后面的USE_CUDNN和USE_C10D分别对应是否使用CUDNN和分布式。这里的分析以最基础的CPU上的Storage为例进行说明,不关注CUDNN和分布式。
在编译过程中用户可以创建一个PyModuleDef structure,并将其引用传递给 PyModule_Create,完成了torch._C的定义,接下来就是各种Torch Python类型的Storage初始化。
下面就是写setup.py了,在setup.py中,主要就是写Extension和setup:
torch._C的Extension编写
- setup编写
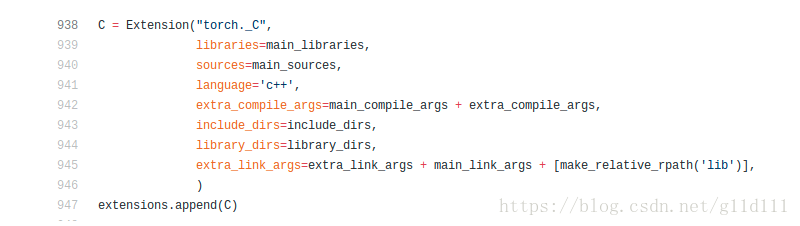

写好了setup.py就可以直接用python setup.py install安装,安装成功的话提示类似如下:
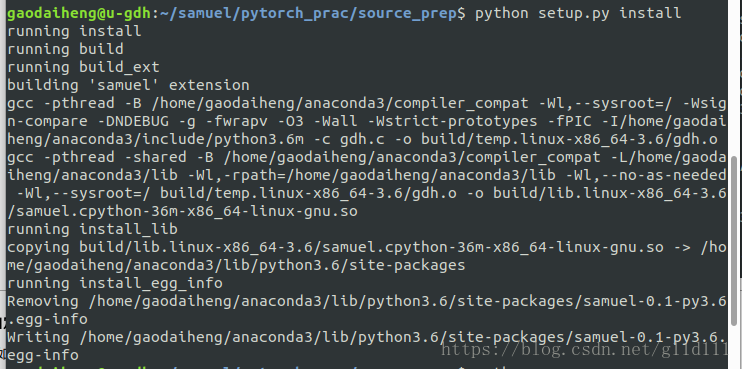
这样就可以直接在.py文件引用torch这个包了。
2. THPDoubleStorage_init(module)的来由
现在让我们回归重点,那就是THPDoubleStorage_init(module)是从哪里来的?直接在源码中查找是找不到的。通过刚才的铺垫,应该了解到THP是由TH转换而成的。
2.1 Python C 对象映射
本小节内容转自zqh_zy ——pytorch源码:C拓展
以C实现的Python为例,对于int类型,需要为其定义该类型:
typedef struct tagPyIntObject
{
PyObject_HEAD;
int value;
} PyIntObject;
对应类型有:
PyTypeObject PyInt_Type =
{
PyObject_HEAD_INIT(&PyType_Type),
"int",
...
};
其中PyObject_HEAD为宏定义,定义了所有对象所共有的部分,包括对象的引用计数和对象类型等共有信息,这也是Python中多态的来源。PyObject_HEAD_INIT是类型初始化的宏定义,简单来看如下:
#define PyObject_HEAD \
int refCount;\
struct tagPyTypeObject *type
#define PyObject_HEAD_INIT(typePtr)\
0, typePtr
同样地,Pytorch拓展的Tensor类型与Python的一般类型的定义类似,torch/csrc/generic目录下的Storage.h中有类似定义:
struct THPStorage {
PyObject_HEAD
THWStorage *cdata;
};
现在的重点就变成了THWStorage *cdata,还记得在Module.cpp中的#include 'THP.h'吗?THP.h的第27行开始,将THWStorage定义为THStorage。现在是不是感觉有点懂了?对的,我们通过Storage.h和THP.h将THPStorage结构体里面的数据类型变成了原来Torch 7框架中的基本数据类型THStorage了!
所以,虽然我们看起来是在用THPStorage,但是实际上,Pytorch映射为由ATen中TH库的THStorage和THTensor。
#define THWStorage THStorage
#define THWStorage_(NAME) THStorage_(NAME)
#define THWTensor THTensor
#define THWTensor_(NAME) THTensor_(NAME)
2.2 ATen的TH库
好了,由上面的分析,我们将一个THPStorage的底层定位到了ATen/src/TH中。下面,我们从THStorage.h,一步一步开始分析:
- ①
THStorage.h
由代码可以看出,其实THStorage.h保存的目的就是为了兼容性,重点在于THStorageFunctions.h。
#pragma once
#include "THStorageFunctions.h"
// Compatability header. Use THStorageFunctions.h instead if you need this.
- ②
THStorageFunctions.h
这个头文件我们重点关注下面几行
#define THStorage_(NAME) TH_CONCAT_4(TH,Real,Storage_,NAME)
#include "generic/THStorage.h"
#include "THGenerateAllTypes.h"
#include "generic/THStorage.h"
#include "THGenerateHalfType.h"
#include "generic/THStorageCopy.h"
#include "THGenerateAllTypes.h"
#include "generic/THStorageCopy.h"
#include "THGenerateHalfType.h"
其中#define THStorage_(NAME) TH_CONCAT_4(TH,Real,Storage_,NAME)是定义了一个字符串拼接宏。
它的作用很直观,比如NAME = init, Real = Float的时候,那么我们通过这个宏,就会得到:
THStorage_init -------> THFloatStorage_init
而THFloatStorage_init就是在Module.cpp初始化中的内容:
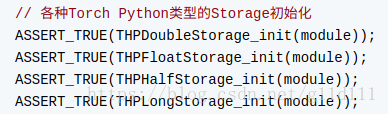
现在,我们好奇的是在宏命令中的Real是在哪里定义的?容易发现,Real是由aten/src/TH/目录下包含的一系列THGenerateDoubleType.h、THGenerateFloatType.h等THGenerate[Tensor类型]Type.h中。
- ③
THGenerateDoubleType.h
以Double为例,看一下它的头文件内容。
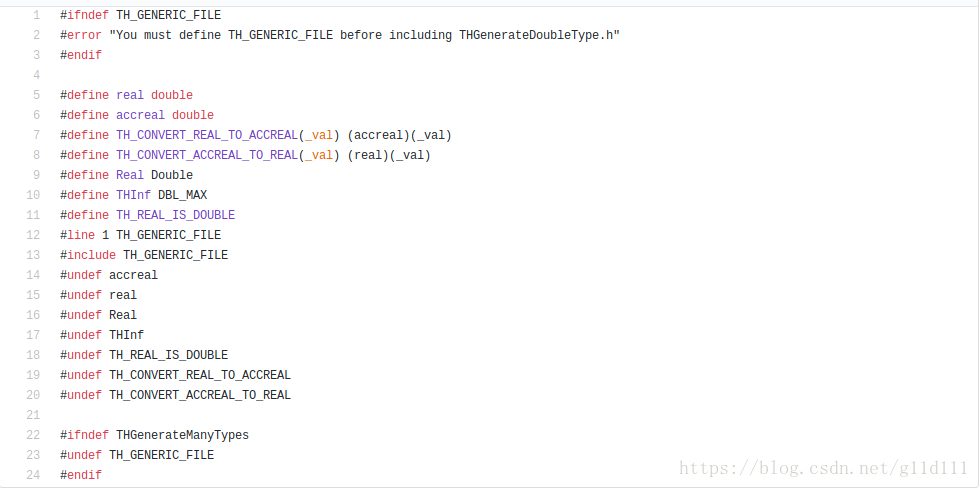
这里需要注意的重点是第5行和第9行,那么我们就知道Real是如何定义的了。
#define real double
#define Real Double
Real定义找到使用场景了,那么real呢?
- ④
THStorageClass.hpp
现在,从THStorageClass.h定位到THStorageClass.hpp,其从40行开始定义了THStorage的结构体。这里重点关注这些成员里重点关注at::ScalarType scalar_type、at::DataPtr data_ptr、 ptrdiff_t size就可以了。
scalar_type 是变量类型:int,float等等;
data_ptr 是一维数组的地址
比如 int a[3] = {1,2,3},data_ptr是数组a的地址,对应的size是3,不是sizeof(a),scalar_type是int。
...
struct TH_CPP_API THStorage
{
THStorage() = delete;
THStorage(at::ScalarType, ptrdiff_t, at::DataPtr, at::Allocator*, char);
THStorage(at::ScalarType, ptrdiff_t, at::Allocator*, char);
// 关注下面3个成员变量
at::ScalarType scalar_type;
at::DataPtr data_ptr;
ptrdiff_t size;
// -----
std::atomic<int> refcount;
std::atomic<int> weakcount;
char flag;
at::Allocator* allocator;
std::unique_ptr<THFinalizer> finalizer;
struct THStorage* view;
THStorage(THStorage&) = delete;
THStorage(const THStorage&) = delete;
THStorage(THStorage&&) = delete;
THStorage(const THStorage&&) = delete;
template <typename T>
inline T* data() const {
auto scalar_type_T = at::CTypeToScalarType<th::from_type<T>>::to();
if (scalar_type != scalar_type_T) {
AT_ERROR(
"Attempt to access Storage having data type ",
at::toString(scalar_type),
" as data type ",
at::toString(scalar_type_T));
}
return unsafe_data<T>();
}
template <typename T>
inline T* unsafe_data() const {
return static_cast<T*>(this->data_ptr.get());
}
};
现在我们知道了THStorage的结构体,那么接下来,就去THStorageClass.cpp查看其构造函数:
#include "THStorageClass.hpp"
THStorage::THStorage(
at::ScalarType scalar_type,
ptrdiff_t size,
at::DataPtr data_ptr,
at::Allocator* allocator,
char flag)
: scalar_type(scalar_type),
data_ptr(std::move(data_ptr)),
size(size),
refcount(1),
weakcount(1), // from the strong reference
flag(flag),
allocator(allocator),
finalizer(nullptr) {
}
THStorage::THStorage(
at::ScalarType scalar_type,
ptrdiff_t size,
at::Allocator* allocator,
char flag)
: THStorage(
// 标量类型
scalar_type,
size,
allocator->allocate(at::elementSize(scalar_type) * size),
allocator,
flag) {
}
现在,可能细心的读者会发现,之前预定义的real还没用到啊?这东西到底在哪里用呢?
- ⑤
generic/THStorage.cpp
答案就是TH库的generic/THStorage.cpp 里用!下面的代码就是使用的例子。通过将 THStorageClass.hpp 、THStorageClass.cpp THStorage.cpp联合分析,终于找到了在THGenerate[Tensor类型]Type.h定义real的使用地点。
THStorage* THStorage_(newWithSize)(ptrdiff_t size)
{
THStorage* storage = new THStorage(
at::CTypeToScalarType<th::from_type<real>>::to(),
size,
getTHDefaultAllocator(),
TH_STORAGE_REFCOUNTED | TH_STORAGE_RESIZABLE);
return storage;
}
2.3 转向Tensor
通过2.1和2.2的分析,我们能够明白一个Storage的组成方式:
THPStorage(Torch Python层的结构体定义,位于csrc/generic/Storage.h)
——>
THWStorage——(THWSorage类型的具体内容,位于csrc/generic/Storage.h)
——>
THStorage(宏定义转换,位于csrc/THP.h)
——>
THStorage的结构体 (位于ATen/src/TH/THStorageClass.hpp)
——>
THStorage的两种构造方法(位于ATen/src/TH/THStorageClass.cpp)
跟Storage类似,Tensor的结构体定义在aten/src/TH/THTensor.hpp中,可以看出,它完全是基于Storage来构建的,对应的是THStorageClass.cpp的第一种构造函数。
...
struct THTensor
{
THTensor(THStorage* storage)
: refcount_(1)
, storage_(storage)
, storage_offset_(0)
, sizes_{
0}
, strides_{
1}
, is_zero_dim_(false)
{
}
~THTensor() {
if (storage_) {
THStorage_free(storage_);
}
}
...
}
...
3. THPStorage的实现
目前,前面的内容已经梳理明白了。那么就让我们把目光转回到映射关系:C/C++对象————>Python类型
接触过Python源码的人会比较清楚,定义一个新类型需要:
-
① 定义该对象包括哪些内容
-
② 为对象定义类型
3.1 定义对象包含内容
现在,我们找到pytorch/torch/csrc/generic目录下的Storage.cpp。
这里面就定义了类型中包含的内容:
PyTypeObject THPStorageType = {
PyVarObject_HEAD_INIT(NULL, 0)
"torch._C." THPStorageBaseStr, /* tp_name */
sizeof(THPStorage), /* tp_basicsize */
0, /* tp_itemsize */
(destructor)THPStorage_(dealloc), /* tp_dealloc */
0, /* tp_print */
0, /* tp_getattr */
0, /* tp_setattr */
0, /* tp_reserved */
0, /* tp_repr */
0, /* tp_as_number */
0, /* tp_as_sequence */
&THPStorage_(mappingmethods), /* tp_as_mapping */
0, /* tp_hash */
0, /* tp_call */
0, /* tp_str */
0, /* tp_getattro */
0, /* tp_setattro */
0, /* tp_as_buffer */
Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE, /* tp_flags */
NULL, /* tp_doc */
0, /* tp_traverse */
0, /* tp_clear */
0, /* tp_richcompare */
0, /* tp_weaklistoffset */
0, /* tp_iter */
0, /* tp_iternext */
0, /* will be assigned in init */ /* tp_methods */
0, /* will be assigned in init */ /* tp_members */
0, /* tp_getset */
0, /* tp_base */
0, /* tp_dict */
0, /* tp_descr_get */
0, /* tp_descr_set */
0, /* tp_dictoffset */
0, /* tp_init */
0, /* tp_alloc */
THPStorage_(pynew), /* tp_new */
};
显然,结构体中包括了很多指针,如最后的THPStorage_(pynew),该方法在该类型对象创建时调用,对应Python类层面中的__new__函数。
THPStorage_(pynew)定义在当前的Storage.cpp中,主要工作就是申请内存和分配(并检查参数,将数据转移到gpu显存等等————36行开始),有兴趣的同学自行看吧…
3.2 为对象定义类型
现在,要看的是把各种Storage类型加入到”_C“模块下供上层Python调用。
回到torch/csrc/Module.cpp中的一系列初始化:
// 各种Torch Python类型的Storage初始化
ASSERT_TRUE(THPDoubleStorage_init(module));
ASSERT_TRUE(THPFloatStorage_init(module));
ASSERT_TRUE(THPHalfStorage_init(module));
ASSERT_TRUE(THPLongStorage_init(module));
该部分初始化对应到torch/csrc/generic/Storage.cpp中的THPStorage_(init)(PyObject *module):
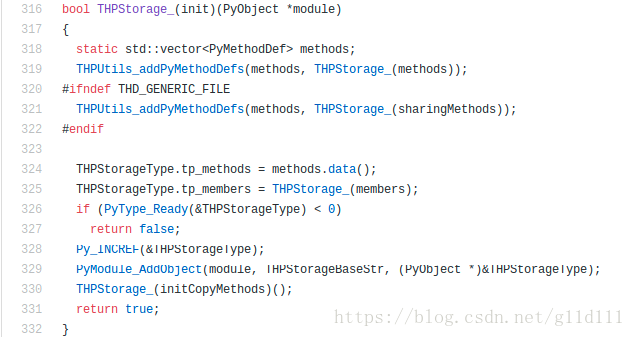
该段代码中需要解释的主要就是:
1)Storage模块的添加
上面的第329行,PyModule_AddObject的作用就是像module里面添加模块,其定义如下:
//将名为name的PyObject指针value加入到模块module中去
int PyModule_AddObject(PyObject *module, const char *name, PyObject *value){
...
}
用法如下:一般是判断是否将模块导入成功
而其中的第2个参数THPStorageBaseStr则是一个在Storage.h中定义的**拼接宏**参数:

作为一个字符串拼接宏,对不同类型,THPStorageBaseStr最终转换成[Type]StorageBase:
以Real为Int为例:
经过此THPStorageBaseStr这个字符串拼接宏,我们得到了IntStorageBase。
即通过 ① THPStorageBaseStr字符串拼接宏 ② 函数PyModule_AddObject就将IntStorageBase、FloatStorageBase等内容添加到_C下面。
由此,我们得到了Python层可以继承的_C.FloatStorageBase,_C.DoubleStorageBase等等。
2)Storage对象的方法集的指定
在Python中,在定义一个对象后,对应的类型结构体中,会包含一个指针,指向该类型可以调用的方法集,例如Python内置类型set的用法:
a = set()
a.add(10)
在PyTorch的Storage类型中,这个可以指向可以调用的方法集的指针即为tp_methods,该指针的赋值如下,等于methods.data()。
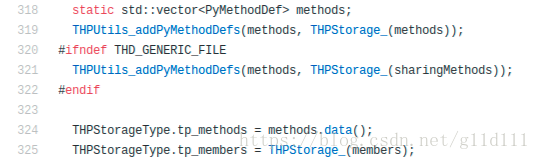
其中methods是由上面(319,321)的THPUtils_addPyMethodDefs(methods, THPStorage_(xxx))来将xxx导入到methods中的。
319行-321行含义:添加自定义的方法集,如果THD_GENERIC_FILE的宏没有定义,那么就将通用方法集添加到Tensor中去。
这些方法包括max()、min()等等,详细内容请查看官方文档。
4. 预备知识
4.1 如何写Python/C 扩展
官网资料:http://book.pythontips.com/en/latest/python_c_extension.html
提到写扩展,首先要问问为什么我们需要写扩展呢? 答案很如下:
1) You want speed and you know C is about 50x faster than Python.
2) Certain legacy C libraries work just as well as you want them to, so you don’t want to rewrite them in python.
3) Certain low level resource access - from memory to file interfaces.
4) Just because you want to.
主要有3种方法:1)Ctypes 2)SWIG 3)Python/C API(最广泛使用)
我们以第3种为例进行说明
4.1.1 简介
所有的Python对象(objects)都以PyObject结构体的形式存在,Python.h的头文件中包含很多函数来操作它。
举个例子,一个PyObject对象是一个PyListType(即Python中的list),我们就可以对结构体使用PyList_Size()函数来获得这个列表的长度(相当于len(list))。
假设我们要写一个很简单的函数,官网的例子是对list求和(list里面都是int)。
代码看起来长这样,看起来很正常。但是唯一不同之处在于:Package addList是用C写的
#Though it looks like an ordinary python import, the addList module is implemented in C
import addList
l = [1,2,3,4,5]
print "Sum of List - " + str(l) + " = " + str(addList.add(l))
4.1.2 写adder.c
include <Python.h>隐含了一些标准的头文件: stdio.h, string.h, errno.h, limits.h, assert.h and stdlib.h (if available)
2.addList_add(...)接收PyObject类型的结构体。传过来的参数 通过 PyArg_ParseTuple()将tuple拆分成一个个单独的element。
其中,
第一个参数是要解析的参数变量,
第二个参数是解析方法,也就是下面的"O", "siO"等,剩下的参数就是指解析出的内容的对应对象地址。
int n;
char *s;
PyObject* list;
PyArg_ParseTuple(args, "siO", &s, &n, &list);
另外,我们不需要PyArg_ParseTuple()的返回值。下面是adder.c的代码
(需要注意,这里面最后跟一些教程不一样,是我自己改的,因为那些教程是基于Python2的写法,对于Python3是不能用的):
```C
//Python.h这个头文件拥有所有我们需要的数据类型(用以表征Python对象类型)和函数定义(用以操作Python对象)
#include <Python.h>
//这就是在Python代码里面需要调用的函数————通常的命名规则是
//{module-name}_{function-name}
static PyObject* addList_add(PyObject* self, PyObject* args){
PyObject * listObj;
//解析输入参数args(类型为PyObject指针) 参数传过来的默认形式是tuple(元组),我们将它解析
// 这里只有一个list,下面会介绍当有多个输入时,应该如何解析。
// 在,PyArg_ParseTuple里面,第2个参数中:‘i’ 表示 integer, ‘s’ 表示 string ‘O’ 表示一个 Python object
// 如果解析多个参数:
// int n;
// char *s;
// PyObject* list;
// PyArg_ParseTuple(args, "siO", &s, &n, &list);
if (! PyArg_ParseTuple( args, "O", &listObj))
return NULL;
// 现在已经将参数args 解析到 listObj对象中了
long length = PyList_Size(listObj);
// 求和
long i = 0;
//
long sum = 0; // short sum = 0;
for(i = 0; i < length; i++){
// 从ListObj中逐个取元素,每个元素同样地,也是一个python对象
PyObject* temp = PyList_GetItem(listObj, i);
// 因为这个temp实际上也是一个python对象,所以将它转换为C中原生类型中的Long (我试试Short)
long elem = PyInt_AsLong(temp);
// short elem = PyInt_AsShort(temp);
sum += elem;
}
//value returned back to python code - another python object
//build value here converts the C long to a python integer
// 将值返回给Python代码,即还需要将C long/short 转换成Python Integer
return Py_BuildValue("i", sum);
}
// 文档说明:
static char addList_docs[] =
"add( ): add all elements of the list\n";
/* This table contains the relavent info mapping -
<Python模块中的函数名称>, <对应C/C++中的函数体>,
<函数期望的参数格式>, <函数的文档说明>
*/
static PyMethodDef addList_funcs[] = {
{
"add", (PyCFunction)addList_add, METH_VARARGS, addList_docs},
{
NULL, NULL, 0, NULL}
};
/*
注意:Python3不支持`Py_InitModule`. 现在, 用户可以创建一个`PyModuleDef` structure,并将其引用传递给
`PyModule_Create`.
结构体样式
2018/7/27 by samuel
*/
static struct PyModuleDef addList_gaga =
{
PyModuleDef_HEAD_INIT,
"addList", /* name of module */
"测试模块_by samuel ko", /* module documentation, may be NULL */
-1, /* size of per-interpreter state of the module, or -1 if the module keeps state in global variables. */
addList_funcs
};
/*
然后,你的`PyMODINIT_FUNC`函数形如下面
*/
PyMODINIT_FUNC PyInit_addList(void)
{
return PyModule_Create(&addList_gaga);
}
4.1.3 写setup.py
对于我们这里的简单情况,setup.py很简单:
"""
@author:samuel
"""
#build the modules
from distutils.core import setup, Extension
setup(name='addList', version='0.1',
ext_modules=[Extension('addList', ['adder.c'])])
我是自己写了一个,没用教程上的,效果如下:
5. 结尾
首先,写这篇文章是受到一个北邮的同学在简书上发表的PyTorch之Tensor源码分析的启发,又看了菠菜僵尸——对pytorch中Tensor的剖析的文章。加之准备学习一下PyTorch的源代码,把头绪缕缕清楚,所以才有了这篇基于最新的PyTorch源码的Tensor、Storage分析。
当然,由于内容太多,不是所有的细节都进行了详细描述。除此之外,有些内容的理解也可能不对,希望得到大家的批评指正。
智能推荐
【备忘录】 iPad air3 pro 10.5 原装键盘 失灵 维修_ipad10.5键盘套没反应-程序员宅基地
文章浏览阅读2.5k次。并不是苹果说的触点问题,而是软布导线被腐蚀断线问题。用铜箔胶带粘一下就好了。不过二手直接买一个咸鱼上也就三百多,也不贵。这个明显是苹果设计缺陷。直接丢了挺可惜的。拆的时候小心点。我的QQ: 13008312096,有空的话可以帮忙有偿代处理。参考链接如下:nullhttps://www.youtube.com/watch?v=buNYHzMZJdk修复好的样子,毫无违和感:..._ipad10.5键盘套没反应
gif图用photoshop快速抽帧,压缩,去底,修改时间_gif抽帧-程序员宅基地
文章浏览阅读1.3w次,点赞3次,收藏13次。网上下载的gif图很多都不透底,而且尺寸时间什么的都不合适,用ps简单修改一下就好了1.抽帧很多gif图帧数很多,抽帧可以大幅压缩gif大小1.导入gif到ps2.勾选动作和时间轴面板这时我们发现帧和图层的隐藏显示是相对应的这样的话我们操作图层就会打乱帧,我们要让所有的图层都显示,但又不干扰帧的显示3.这时我们就要把它转换为视频时间轴4.然后再转换帧>>转换为..._gif抽帧
c++ 优先队列_面试必知必会|堆和优先队列-程序员宅基地
文章浏览阅读235次。通过本文将了解到以下内容:优先队列的概念优先队列的实现优先队列的应用1.优先队列的概念优先队列是计算机科学中的一类抽象数据类型。优先队列中的每个元素都有各自的优先级,优先级最高的元素最先得到服务;优先级相同的元素按照其在优先队列中的顺序得到服务。优先队列至少需要支持下述操作:a.插入带优先级的元素b.取出具有最高优先级的元素c.查看最高优先级的元素。综合考虑插入和删除的性能 优先队列一般采用堆来实..._优先队列 c++面试
windows系统VMware安装Linux虚拟机、Linux配置JDK环境、Linux安装tomcat、Linux安装mysql、Linux通过SSH连接Navicat 数据库可视化工具_vm中linux下载安装mysql jdk-程序员宅基地
文章浏览阅读281次。windows系统VMware安装Linux虚拟机、配置JDK环境、安装tomcat、安装mysql、安装redis第一部分VMware安装Linux—————————————————————————————————xshell、VMware工具链接:解压之后安装VMware工具xshell不需要安装解压可直接使用..._vm中linux下载安装mysql jdk
Python 加密解密_咕咕加密v4-程序员宅基地
文章浏览阅读1k次。# -*- coding: utf-8 -*-import hashlib'''加密解密'''#MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,# 通常用一个32位的16进制字符串表示。md5 = hashlib.md5()update = md5.update('hhhhhaaa')print(md5.hexdigest())#SHA1的结果是160..._咕咕加密v4
使用cesium primitive api绘制三维插值图,热力图_cesium 插值点-程序员宅基地
文章浏览阅读1.4k次,点赞3次,收藏13次。【代码】使用cesium primitive api绘制三维插值图。_cesium 插值点
随便推点
Ubuntu18.04安装教程——超详细的图文教程_ubuntu系统18.04-程序员宅基地
文章浏览阅读10w+次,点赞112次,收藏974次。Ubuntu18.04镜像_ubuntu系统18.04
二、Json对象、Json数组和Json字符串_json字符串数组-程序员宅基地
文章浏览阅读6.7k次,点赞3次,收藏17次。一、Json字符串和Json对象定义:1、Json字符串:所谓字符串:单引号或者双引号引起来,是一个String类型的字符串:如下:var person='{"name":"shily","sex":"女","age":"23"}';//json字符串console.log(person)console.log(person.name)console.log(typeof person) 2、Json对象:最显著的特征:对象的值可以用 “对象.属性” 进行访问,_json字符串数组
Linux系统100条命令:关于Ubuntu和 CentOS 7 相同功能的不同的终端操作命令_ubuntu 命令跟centos-程序员宅基地
文章浏览阅读718次。CentOS 7:ip link set interface_name up 或 ip link set interface_name down。Ubuntu:ifconfig interface_name up 或 ifconfig interface_name down。CentOS 7:编辑 /etc/sysconfig/network-scripts/ifcfg-eth0 文件。Ubuntu:编辑 /etc/network/interfaces 文件。_ubuntu 命令跟centos
windows10下VS2019编译jpegsrc.v9e.tar.gz为lib静态库(已验证)_jpeg library error vs2019-程序员宅基地
文章浏览阅读652次。jpegsr9e windows vs2019生成方法,以及库下载_jpeg library error vs2019
重磅?华为 Mate60/Pro 系列网速实测结果公布,最高 1205.57 Mbps_华为mate60pro+核实网络-程序员宅基地
文章浏览阅读647次。总的来说,华为Mate 60/Pro系列手机的高速网速表现引起了广泛的关注,这也是消费者对该系列手机购买热情高涨的一个重要因素。可以看出,华为Mate 60/Pro系列手机的网速表现非常出色,这也是消费者购买该系列手机的一个重要原因。此前,华为Mate 60 Pro的供应量已经增至1500万至1700万台,而最新消息称,华为Mate 60 Pro和Mate 60 Pro+的出货量甚至已上调至2000万台。目前,在中国市场上,手机竞争愈发激烈,不仅华为Mate 60系列,其他品牌的手机也都受到了高温的迎接。_华为mate60pro+核实网络
access查找出生日期年份_access怎样利用出生日期计算年龄呀!-程序员宅基地
文章浏览阅读7.1k次。公告: 为响应国家净网行动,部分内容已经删除,感谢读者理解。话题:access怎样利用出生日期计算年龄呀!回答:lt;%set rs = server.createobject("adodb.recordset") curid=request("id") sql = "UPDATE pany SET a_num=a_num+1,day_count=day_count+1 WHERE day_lda..._access出生年份表达式