数据结构与算法-17-跳表-程序员宅基地
上两节我们讲了二分查找算法。当时我讲到,因为二分查找底层依赖的是数组随机访问的特性,所以只能用数组来实现。如果数据存储在链表中,就真的没法用二分查找算法了吗?
实际上,我们只需要对链表稍加改造,就可以支持类似"二分"的查找算法。我们把改造之后的数据结构叫作跳表(Skip list),也就是今天要讲的内容。
跳表这种数据结构对你来说,可能会比较陌生,因为一般的数据结构和算法书籍里都不怎么会讲。但是它确实是一种各方面性能都比较优秀的动态数据结构,可以支持快速插入、删除、查找操作,写作起来也不复杂,甚至可以替代红黑树(Red-black tree)。
Redis中的有序集合(Sorted Set)就是用跳表来实现的。如果你有一定基础,应该知道红黑树也可以实现快速地插入、删除和查找操作。那Redis为什么会选择用跳表实现有序集合呢?为什么不用红黑树呢?学完今天的内容,你就知道答案了。
如何理解"跳表"
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头遍历链表。这样查找效率就会很低,时间复杂度会很高,是O(n)。
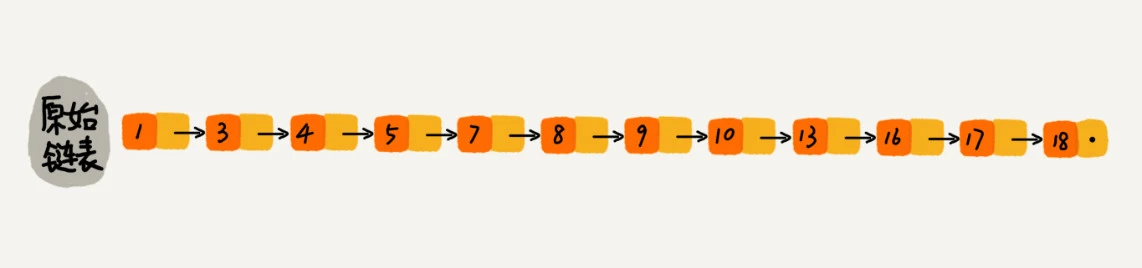
那怎么来提高查找效率呢?如果像图中那样,对链表建立"索引",查找起来是不是就会更快一些呢?没两个节点提取一个节点到上一级,我们把抽出来的那一级叫作索引或索引层。
你可以看我画的图。图中的down表示down指针,指向下一级节点。
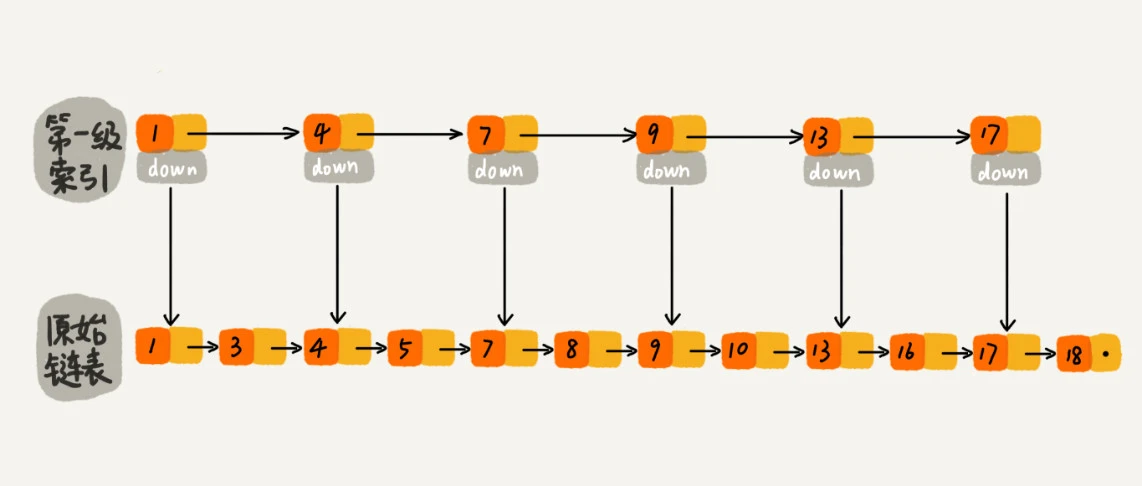
如果我们现在要查找某个节点,比如16。我们可以现在索引层遍历,当遍历到索引层中值为13的结点时,我们发现下一个节点是17,那要查找的节点16肯定就在这两个节点之间。然后我们通过索引层节点的down指针,下降到原始链表这一层,继续遍历。这个时候,我们只需要在遍历2个结点,就可以找到值等于16的这个节点了。这样,原来如果要查找16,需要遍历10个节点,现在只需要遍历7个结点。
从这个例子中,我们看出,加来一层索引之后,查找一个节点需要遍历的节点个数减少了,也就是说查找效率提高了。那如果我们在加一级索引呢?效率会不会提升更多呢?
跟前面建立第一级索引的方式相似,我们在第一级索引的基础之上,每两个节点就抽出一个节点到第二级索引。现在我们再来查找16,只需要遍历6个结点了,需要遍历的结点数量又减少了。
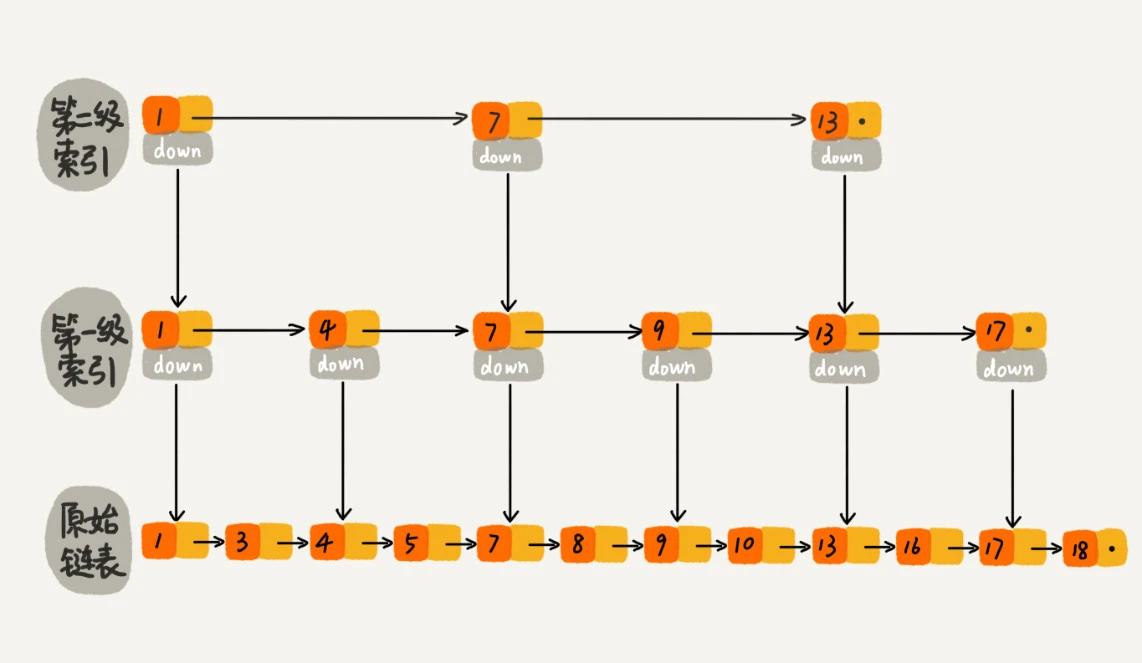
我举的例子数据量不大,所以即便加了两级索引,查找效率的提升也并不明显。为了让你能真切地感受索引提升查询效率。我画了一个包含64个节点的链表,按照前面讲的这种思路,建立了五级索引。
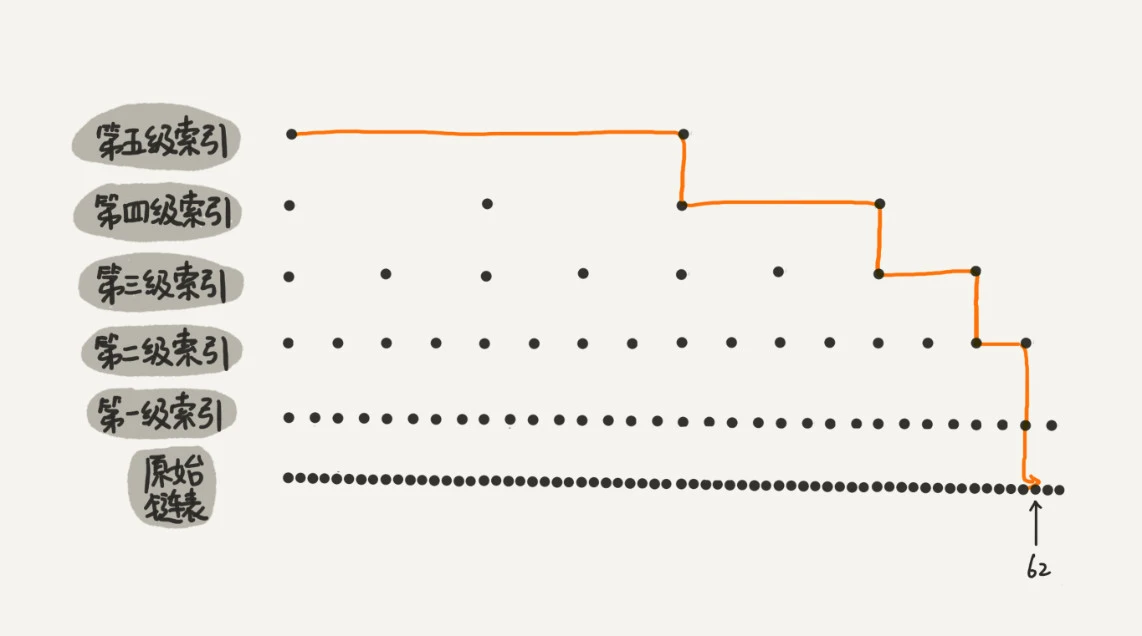
从图中我们可以看出,原来没有索引的时候,查找62需要遍历62个结点,现在只需要遍历11个节点,速度是不是提高了很多?所以,当链表的长度n比较大时,比如1000、10000的时候,在构建索引之后,查找效率的提升就会非常明显。
前面讲的这种链表加多级索引的结构,就是跳表。我通过例子给你展示了跳表是如何减少查询次数的,现在你应该比较清晰地知道,跳表确实是可以提高查询效率的。接下来,我会定量地分析一下,用跳表查询到底有多快。
用跳表查询到底有多快?
前面我讲过,算法的执行效率可以通过时间复杂度来度量,这里依旧可以用。我们知道,在一个单链表查询某个数据的时间复杂度是O(n)。那在一个具有多级索引的跳表中,查询某个数据的时间复杂度是多少呢?
这个时间复杂度的分析方法比较难想到。我把问题分解一下,先来看这样一个问题,如果链表里有n个结点,会有多少级索引呢?
按照我们刚才讲的,每两个节点会抽出一个节点作为上一级索引的节点,那第一级索引的结点个数大约就是n/2,第二级索引的接地那个数大约就是n/4,第三级索引的节点个数大约就是n/8,依次类推,也就是说,第k级索引的节点个数是k-1级索引的节点个数的1/2,那第k级索引接地那的个数就是n/(2^k)。
假设索引有h级,最高级的索引有2个结点。通过上面的公式,我们可以得到n/(2^h) = 2,从而求得h=㏒₂n-1 。如果包含原始链表这一层,整个跳表的高度就是㏒₂n。我们在跳表中查询某个数据的时候,如果每一层都要遍历m个节点,那在跳表中查询一个数据的时间复杂度就是O(m*logn)。
那这个m的值是多少呢?按照前面这种索引结构,我们每一级索引都最多只需要遍历3个接地那,也就是说m=3,为什么是3呢?我来解释一下。
假设我们要查找的数据是x,在k级索引中,我们遍历到y节点之后,发现x大于y,小于后面的节点z,所以我们通过y的down指针,从第k级索引下降到第k-1级索引。在第k-1级索引中,y和z之间只有3个节点(包含y和z),所以,我们在k-1级索引中最多只需要遍历3个节点,依次类推,每一级索引都最多只需要遍历3个节点。
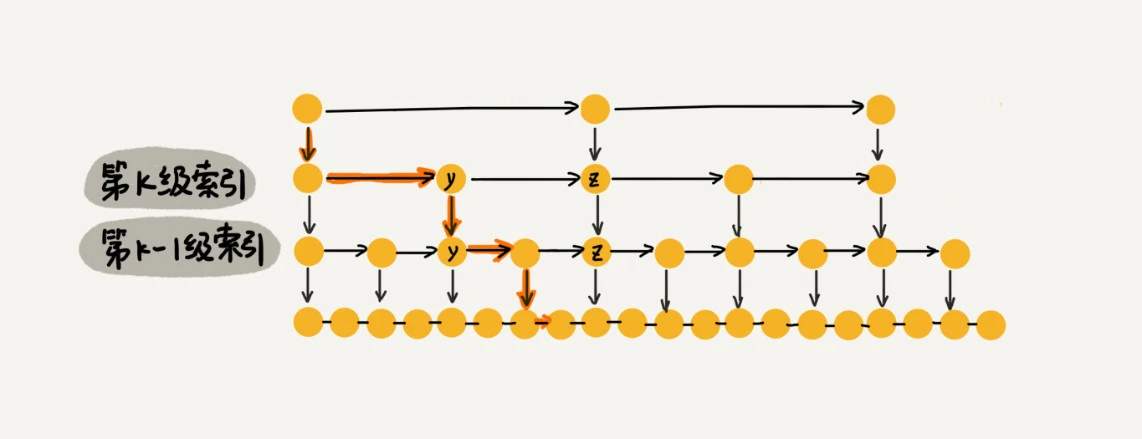
通过上面的分析,我们得到m=3,所以在跳表中查询任意数据的时间复杂度就是O(logn)。这个查找的时间复杂度跟二分查找是一样的。欢聚话说,我们其实是基于单链表实现了二分查找,是不是很神奇?不过,天下没有免费的午餐,这种查询效率的提升,前提是建立了很多级索引,也就是我们在链表(上):如何实现LRU缓存淘汰算法?讲过的空间换时间的设计思路。
跳表是不是浪费内存?
比起单纯的单链表,跳表需要存储多级索引,肯定要消耗更多的存储空间。那到底需要消耗多少额外的存储空间呢?我们来分析一下跳表的空间复杂度。
跳表的空间复杂度分析并不难,我在前面说了,假设原始链表大小为n,那第一级索引大约有n/2个结点,第二级索引大约n/4个结点,以此类推,每上升一级就减少一半,知道剩下2个结点。如果我们把每层索引的节点数写出来,就是一个等比数列。

这几级索引的结点总和就是n/2 + n/4 + n/8 ... + 8 + 4 + 2 = n -2。所以,跳表的空间复杂度是O(n)。也就是说,如果将包含n个结点的单链表构造成跳表,我们需要额外再用接近n个结点的存储空间。那我们有没有办法降低索引占用的内存空间呢?
我们前面都是每两个节点抽一个节点到上级索引,如果我们每三个节点或五个节点,抽一个节点到上级索引,是不是就不用那么多索引节点了呢?我画了一个每三个节点抽一个示意图,你可以看下。
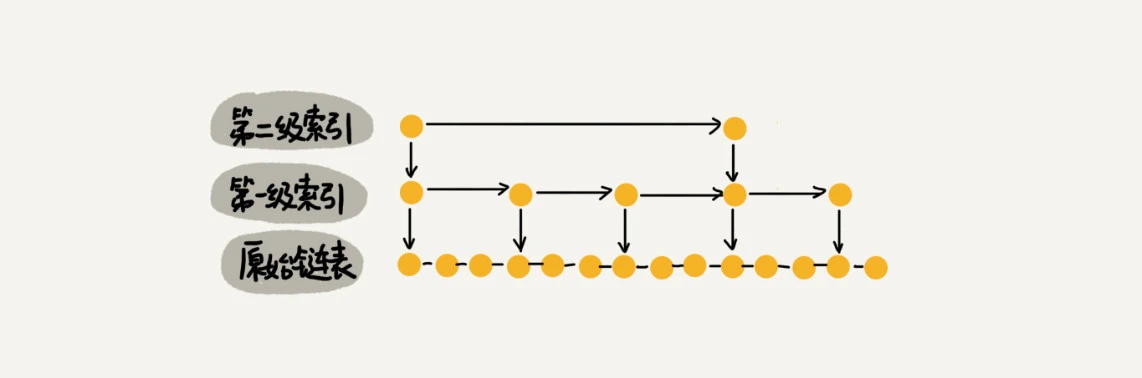
从图中可以看出,第一级索引需要大约n/3个结点,第二级索引需要大约n/9个结点。每往上一级,索引节点个数都除以3。为了方便计算,我们假设最高一级的索引节点个数是1。我们把每级索引的接地那个数都写下来,也是一个等比数列。

通过等比数列求和公式,总的索引节点大约就是n/3+n/9+n/27+...+9+3+1=n/2。尽管空间复杂度还是O(n),但比上面的每两个节点抽一个节点的索引构建方法,要减少了一半的索引节点存储空间。
实际上,在软件开发中,我们不必太在意索引占用的额外空间。在讲数据结构和算法时,我们习惯性地把药处理的数据看成整数,但是在实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引节点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引节点大很多时,那索引占用的额外空间就可以忽略了。
高效的动态插入和删除
跳表长什么样子我想你应该已经很清楚,它的查找操作我们刚才也讲过了。实际上,跳表这个动态数据结构,不仅支持查找操作,还支持动态的插入、删除操作,而且插入、删除操作的时间复杂度也是O(logn)。
我们现在来看下,如何在跳表中插入一个数据,一级它是如何做大O(logn)的时间复杂度的?
我们知道,在单链表中,一旦定位好要插入的位置,插入节点的时间复杂度是很低的,就是O(1)。但是,这里为了保证原始链表中数据的有序性,我们需要先找到要插入的位置,这个查找操作就会比较耗时。
对于纯粹的单链表,需要遍历每个节点,来找到插入的位置。但是,对于跳表来说,我们讲过查找某个节点的时间复杂度是O(logn),所以这里查找某个数据应该插入的位置,方法也是类似的,时间复杂度也是O(logn),我画了一张图,你可以很清晰地看到插入的过程。

好了,我们再来看删除操作。
如果这个节点在索引中也有出现,我们除了要删除原始链表中的节点,还还要删除索引中的。因为单链表中的删除操作需要拿到要删除节点的前驱节点,然后通过指针操作完成删除。所以在查找要删除的节点的时候,一定要获取前驱节点。当然,如果我们用的是双向链表,就不需要考虑这个问题。
跳表索引动态更新
当我们不停地往跳表中插入数据时,如果我们不更新索引,就有可能出现某2个索引节点之间数据非常多的情况,极端情况下,跳表还会退化成单链表。
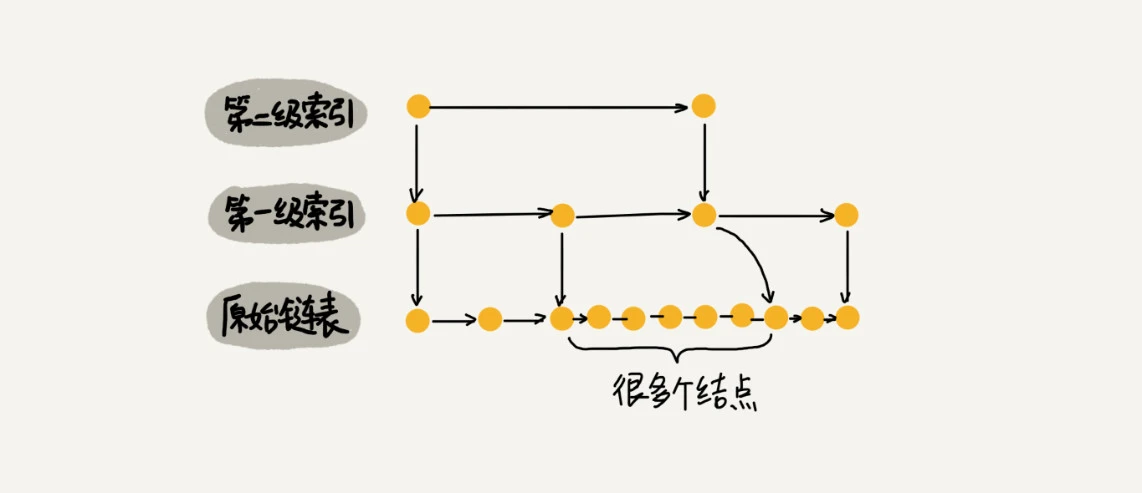
作为一种动态数据结构,我们需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表中节点多了,索引节点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。
如果你了解红黑树、AVL树这样平衡二叉树,你就知道它们是通过左右旋的方式保持左右子树的大小平衡(如果不了解也没关系,我们后面会讲),而跳表是通过随机函数来维护前面提到的"平衡性"。
当我们往跳表中插入数据的时候,我们可以选择同时将这个数据插入到部分索引层中。如何选择加入哪些索引层呢?
我们通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第 K 级这 K 级索引中。

随机函数的选择很有讲究,从概率上来讲,能够保证跳表的索引大小和数据大小平衡性,不至于性能过度退化。至于随机函数的选择,我就不展开讲解了。如果你感兴趣的话,可以看看我在 GitHub 上的代码或者 Redis 中关于有序集合的跳表实现。
跳表的实现还是稍微有点复杂的,我将 Java 实现的代码放到了 GitHub 中,你可以根据我刚刚的讲解,对照着代码仔细思考一下。你不用死记硬背代码,跳表的实现并不是我们这节的重点。
解答开篇
今天的内容到此就讲完了。现在,我来讲解一下开篇的思考题:为什么 Redis 要用跳表来实现有序集合,而不是红黑树?
Redis 中的有序集合是通过跳表来实现的,严格点讲,其实还用到了散列表。不过散列表我们后面才会讲到,所以我们现在暂且忽略这部分。如果你去查看 Redis 的开发手册,就会发现,Redis 中的有序集合支持的核心操作主要有下面这几个:
- 插入一个数据;
- 删除一个数据;
- 查找一个数据;
- 按照区间查找数据(比如查找值在[100,356]之间的数据);
- 迭代输出有序列表
其中,插入、删除、查找以及迭代输出有序序列这几个操作,红黑树也可以完成,时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
对于按照区间查找数据这个操作,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了。这样做非常高效。
当然,Redis 之所以用跳表来实现有序集合,还有其他原因,比如,跳表更容易代码实现。虽然跳表的实现也不简单,但比起红黑树来说还是好懂、好写多了,而简单就意味着可读性好,不容易出错。还有,跳表更加灵活,它可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
不过,跳表也不能完全替代红黑树。因为红黑树比跳表的出现要早一些,很多编程语言中的 Map 类型都是通过红黑树来实现的。我们做业务开发的时候,直接拿来用就可以了,不用费劲自己去实现一个红黑树,但是跳表并没有一个现成的实现,所以在开发中,如果你想使用跳表,必须要自己实现。
内容小结
今天我们讲了跳表这种数据结构。跳表使用空间换时间的设计思路,通过构建多级索引来提高查询的效率,实现了基于链表的“二分查找”。跳表是一种动态数据结构,支持快速地插入、删除、查找操作,时间复杂度都是 O(logn)。
跳表的空间复杂度是 O(n)。不过,跳表的实现非常灵活,可以通过改变索引构建策略,有效平衡执行效率和内存消耗。虽然跳表的代码实现并不简单,但是作为一种动态数据结构,比起红黑树来说,实现要简单多了。所以很多时候,我们为了代码的简单、易读,比起红黑树,我们更倾向用跳表。
参考:
智能推荐
TimeGen 软件的使用_timegen 字体太小-程序员宅基地
文章浏览阅读1.1k次。官网 http://www.xfusionsoftware.com/timegen 是一款实用的画时序图工具,软件提供了直观的用户界面和丰富实用的绘图工具,可以帮助用户轻松绘制各种序列图、顺序图、循序图等,同时timegen还拥有实用的快捷键操作功能,能够让你绘图时序图更加轻松,且可以自由设置各个文本框的属性字体样式、字体 大小和颜色等。下面简单介绍一下他的应用:主要参考:https://blog.csdn.net/qq_25144391/article/details/104423988?ops__timegen 字体太小
adb shell uiautomator dump /doinf/uidumpa.xml 一切正常,就是没有显示这个文件。_adb shell uiautomator dump无效-程序员宅基地
文章浏览阅读1.2k次。返回的UI hierchary dumped to: /doinf/uidumpa.xml但是手机里就是没有这个文件。这是什么情况啊?_adb shell uiautomator dump无效
kaldi中声纹识别ivector模型_kaldi i-vector-程序员宅基地
文章浏览阅读4.4k次,点赞2次,收藏24次。1.数据准备:无论使用kaldi来做语音识别还是说话人识别,第一步就是数据准备,对于说话人识别来说,需要准备的几个文件为wav.scp,utt2spk,spk2utt这三个文件。对应的格式如下: 1.1 wav.scp有两列,第一列是key,这个可以一定要唯一;第二列是 wav的路径wavpath; 1.2 utt2spk也有两列,第一列是key,与wav.scp的第一列一样;..._kaldi i-vector
2019-程序员宅基地
文章浏览阅读4.2k次。序言2019年好像没几天就要结束了,所以写个渣渣凑个数量,爱看的看看,不爱看的滑过。2019是猪队友的元年,所以总结为2个字就是炮灰。风言风语1 猪队友你..._office2019专业增强版激活
Git(五)常用命令精简整理_git bash命令-程序员宅基地
文章浏览阅读896次。全局设置git config --global user.name "acgkaka"git config --global user.email "[email protected]"初始化.git文件夹git init将当前文件夹连接到test远程仓库git remote add origin https://gitee.com/acgkaka/test.git将本地的当前分支推送到远程的master分支,同时指定origin为默认主机,(后面再使用git push的时候就可以不加任_git bash命令
spring boot2.0自定义注入mongoTemplate使用审计标签@EnableMongoAuditing报错_springboot2.0+mongotemplate-程序员宅基地
文章浏览阅读6k次。项目原来在spring boot1.5.9版本时候使用@EnableMongoAuditing用同样的方法注入并没有报错,当切换到2.0版本是莫名其妙的出问题了,搞的我一脸懵逼,花了好久都没解决,后来偶然看到我们公司一个大佬的自定义注入的的方式,瞬间感觉到了王者和青铜的差距。 下面是配置代码@Configuration@EnableMongoAuditing@PropertySourc..._springboot2.0+mongotemplate
随便推点
USB3.0:VL817Q7-C0的LAYOUT指南(三)_usb3.0 layout-程序员宅基地
文章浏览阅读1.5k次。本文着重讲解市面上常见的USB3.0集线器驱动芯片威盛VL817-Q7C0的layout布局处理以及注意事项。可分为三小节。 前文已经讲过VL系列的第一小节:《线路布局重点说明》以及第二小节《PCB布局检查》。本文着重讲解第三小节:《VL芯片布局的注意事项》。VLI芯片布局注意事项1.高速对线的阻抗:(包括线宽,线距,SMD&DIP PAN的处理)二层板/板厚1.6mm......_usb3.0 layout
有没有遇到过Anaconda中Spyder无法更新到4.0.1的问题?_spyderutility4.0升级-程序员宅基地
文章浏览阅读3.6k次,点赞2次,收藏13次。在anaconda的使用过程中,时不时会遇到类似Spyder等无法更新的问题,这种问题即使通过重新安装Anaconda也无法解决。这里直接放上我成功解决Spyder更新的方法链接:Trouble updating to Spyder 4.0.0.通常,我们可以通过命令 conda update spyder获取最新版本,然而,即使是在刚安装好anaconda后,也会提示当前版本是3.3.6。无..._spyderutility4.0升级
分治算法思想及应用_分治思想-程序员宅基地
文章浏览阅读3.8k次,点赞5次,收藏22次。一. 分治算法介绍1. 分治算法思想2. 分治算法适用条件3. 分治算法的引入二. 分治算法的应用1. 快速排序2. 快排划分函数求topk问题3. 归并排序4. 合并k个有序单链表5. 对数时间求中位数算法思想_分治思想
Linux|minio对象存储服务的部署和初步使用总结_linux部署minio-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏5次。minio是一个非常轻量化的对象存储服务,是可以算到云原生领域的。该服务是使用go语言编写的,因此,主文件就一个文件,它的下载,部署什么的都是非常简单的,一般两三步就可以搭建好了,只是有一些细节问题需要在部署使用的时候注意。本文将就一个可用的minio存储服务部署做一个尽量详细的讲解,并探讨如何将该技术落地_linux部署minio
MATLAB2018a与VS2015 C++编译包安装下载的心路历程与解决之道_matlab安装vs2015编译器-程序员宅基地
文章浏览阅读1.9k次,点赞2次,收藏12次。前言:本着前人栽树后人乘凉的精神。感谢csdn朋友们所分享出来关于如何解决的安装方法,以我的下载安装的成功的经验来为困扰各位奉献一点力量。_matlab安装vs2015编译器
PL2586/USB2.0HUB工业级多口集线器扩展芯片|MA8601升级版_usb 扩展 芯片-程序员宅基地
文章浏览阅读355次。PL2586是旺玖新出的一款USB HUB 芯片PL2586是一项创新,它集成了符合USB-IF“电池充电规范修订版1.2”的功能,支持便携式设备的快速充电功能。此功能将PL2586转变为“通用充电解决方案”(UCS)兼容的基于电池的便携式设备的USB充电集线器,由GSMA推广。当在下游端口检测到符合B.C.标准的便携式设备时,PL2586中的专用端口可以处理充电请求。而且,在握手完成后,PL2586允许便携式设备达到900mA(高速);1.5A(低速/全速)来自充电下游端口(CDP)或1.5A来自_usb 扩展 芯片