tensorflow实现简单RNN_tensorflow rnn-程序员宅基地
技术标签: tensorflow rnn 深度学习
使用简单RNN预测谷歌的股票
import numpy as np
import tensorflow.keras as keras
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
def RNN(x_train, y_train):
regressor = keras.Sequential()
# add the first RNN and the Dropout to prevent overfitting
regressor.add(keras.layers.SimpleRNN(units=50, return_sequences=True,
input_shape=(x_train.shape[1], 1)))
# if the return_sequences is True, it means that it has another rnn upward,and it return
# (batch_size,time_step,units) shape matrix
# otherwise it return (batch_size,units) matrix
regressor.add(keras.layers.Dropout(0.2))
# add the second one
regressor.add(keras.layers.SimpleRNN(units=50, activation='tanh', return_sequences=True))
regressor.add(keras.layers.Dropout(0.2))
regressor.add(keras.layers.SimpleRNN(units=50))
regressor.add(keras.layers.Dropout(0.2))
# add the output layer
regressor.add(keras.layers.Dense(units=1))
# compile
regressor.compile(optimizer='adam', loss='mean_squared_error', metrics=['accuracy'])
regressor.fit(x=x_train, y=y_train, epochs=30, batch_size=32)
# print(regressor.summary())
return regressor
def visualization(real, pred):
plt.figure(figsize=(8, 4), dpi=80, facecolor='w', edgecolor='k')
plt.plot(real, color="orange", label="Real value")
plt.plot(pred, color="c", label="RNN predicted result")
plt.legend()
plt.xlabel("Days")
plt.ylabel("Values")
plt.grid(True)
plt.show()
if __name__ == "__main__":
data = pd.read_csv(r"dataset\geogle_stock_price\archive\Google_Stock_Price_Train.csv")
data = data.loc[:, ["Open"]].values
train = data[:len(data) - 50]
test = data[len(train):]
train.reshape(train.shape[0], 1)
scaler = MinMaxScaler(feature_range=(0, 1))
train_scaled = scaler.fit_transform(train)
# plt.plot(train_scaled)
# plt.show()
X_train = []
Y_train = []
time_step = 50
for i in range(time_step, train_scaled.shape[0]):
X_train.append(train_scaled[i - time_step:i, 0])
Y_train.append(train_scaled[i, 0])
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
inputs = data[len(data) - len(test) - time_step:]
inputs = scaler.transform(inputs)
X_test = []
for i in range(time_step, inputs.shape[0]):
X_test.append(inputs[i - time_step:i, 0])
X_test = np.array(X_test)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
model = RNN(X_train, Y_train)
pred = model.predict(X_test)
pred = scaler.inverse_transform(pred)
visualization(real=test, pred=pred)
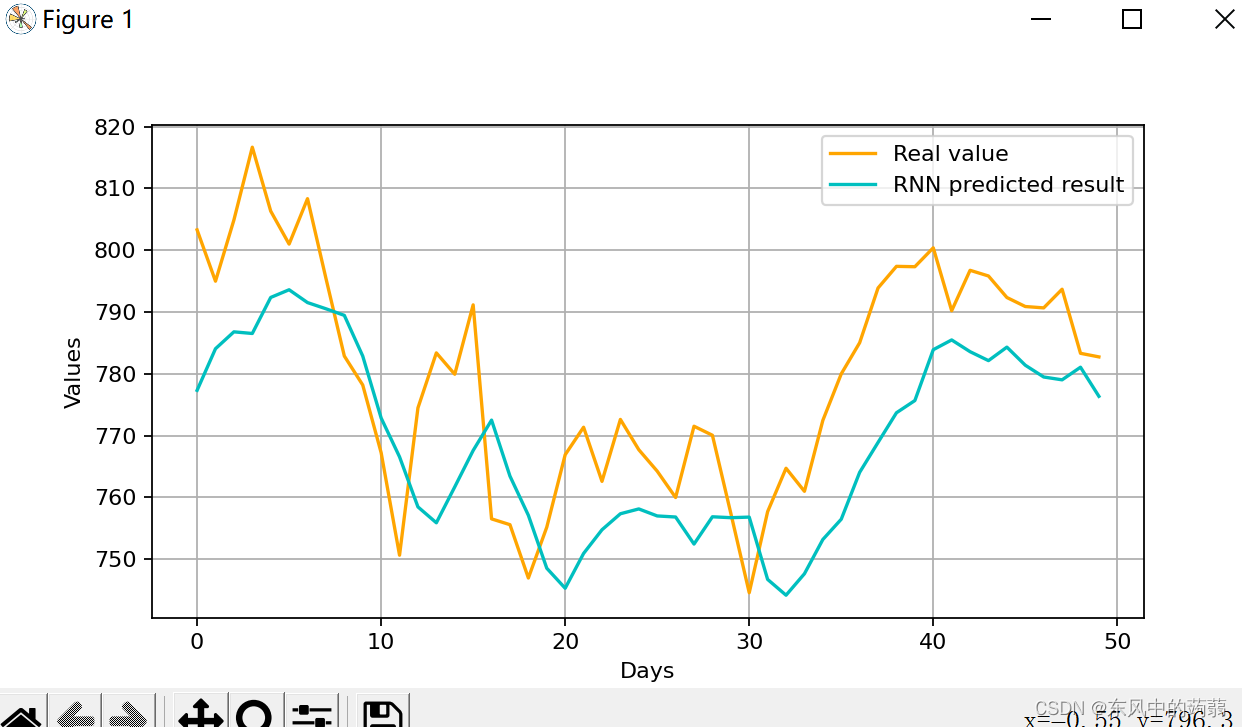
- 简单的RNN会遇到例如梯度消失无法嵌套太多层、单项传播无法考虑后面对前面的影响等各种问题
LSTM模型预测
# -*-coding = utf-8
import numpy as np
import tensorflow.keras as keras
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
def RNN(x_train, y_train):
regressor = keras.Sequential()
# add the first RNN and the Dropout to prevent overfitting
regressor.add(keras.layers.SimpleRNN(units=50, return_sequences=True,
input_shape=(x_train.shape[1], 1)))
# if the return_sequences is True, it means that it has another rnn upward,and it return
# (batch_size,time_step,units) shape matrix
# otherwise it return (batch_size,units) matrix
regressor.add(keras.layers.Dropout(0.2))
# add the second one
regressor.add(keras.layers.SimpleRNN(units=50, activation='tanh', return_sequences=True))
regressor.add(keras.layers.Dropout(0.2))
regressor.add(keras.layers.SimpleRNN(units=50))
regressor.add(keras.layers.Dropout(0.2))
# add the output layer
regressor.add(keras.layers.Dense(units=1))
# compile
regressor.compile(optimizer='adam', loss='mean_squared_error')
# a important point: we do not give a metric such as accuracy in the CNN or ohter neural network
#
regressor.fit(x=x_train, y=y_train, epochs=30, batch_size=32)
# print(regressor.summary())
return regressor
def LSTM(x_train, y_train):
model = keras.Sequential()
model.add(keras.layers.LSTM(units=10, activation='tanh', input_shape=(None, 1)))
# ten units LSTM
model.add(keras.layers.Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=1, epochs=15)
return model
def visualization(real, pred):
plt.figure(figsize=(8, 4), dpi=80, facecolor='w', edgecolor='k')
plt.plot(real, color="orange", label="Real value")
# plt.plot(pred, color="c", label="RNN predicted result")
plt.plot(pred, color='r', label='LSTM predicted result')
plt.legend()
plt.xlabel("Days")
plt.ylabel("Values")
plt.grid(True)
plt.show()
if __name__ == "__main__":
data = pd.read_csv(r"dataset\geogle_stock_price\archive\Google_Stock_Price_Train.csv")
data = data.loc[:, ["Open"]].values
train = data[:len(data) - 50]
test = data[len(train):]
train.reshape(train.shape[0], 1)
scaler = MinMaxScaler(feature_range=(0, 1))
train_scaled = scaler.fit_transform(train)
# plt.plot(train_scaled)
# plt.show()
X_train = []
Y_train = []
time_step = 50
for i in range(time_step, train_scaled.shape[0]):
X_train.append(train_scaled[i - time_step:i, 0])
Y_train.append(train_scaled[i, 0])
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
inputs = data[len(data) - len(test) - time_step:]
inputs = scaler.transform(inputs)
X_test = []
for i in range(time_step, inputs.shape[0]):
X_test.append(inputs[i - time_step:i, 0])
X_test = np.array(X_test)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
# model = RNN(X_train, Y_train)
model = LSTM(X_train, Y_train)
pred = model.predict(X_test)
pred = scaler.inverse_transform(pred)
visualization(real=test, pred=pred)
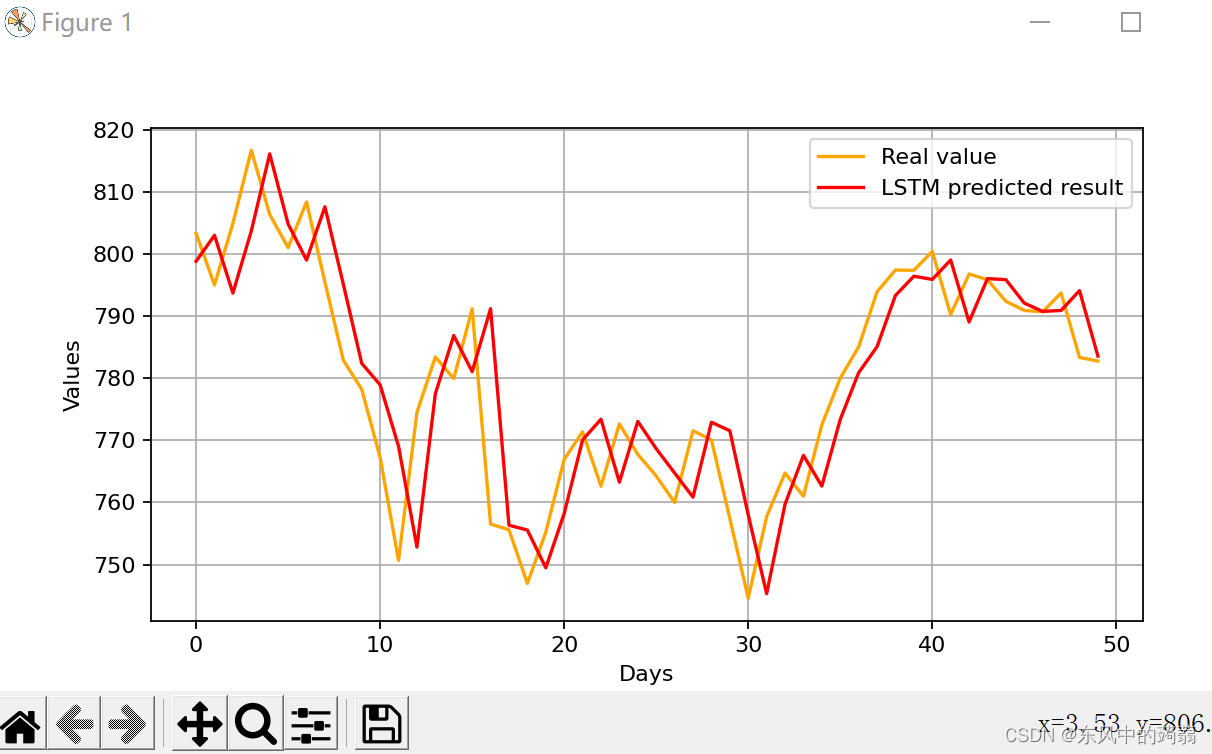
可以看到LSTM模型的预测效果比简单CNN要好很多,基本上复现了真实的股价,只是在时间上面有一些延迟。
modifie RNN
智能推荐
OGRE License & FBReader License_pathfinder license-程序员宅基地
文章浏览阅读971次。1 、OGRE 采用MITLicensing FAQQ: Is OGRE really free?If you abide by the open source licensing conditions, yes.Q: Do I have to release my own source code if I use OGRE?A: No.Q: Do I have to_pathfinder license
Qt使用QOpcUa类_qtopcua-程序员宅基地
文章浏览阅读6.6k次,点赞6次,收藏37次。QT QOPCUA_qtopcua
【5G之道】第七章:上行链路物理层处理_5g occ-程序员宅基地
文章浏览阅读4k次,点赞3次,收藏23次。传输信道处理:上行链路共享信道UL-SCH的物理层处理,以及随后以基本的OFDM时频网格的形式到上行链路物理资源的映射;处理步骤:与下行链路类似,上行链路载波聚合情况下,不同组分载波对应带有独立物理层处理的单独传输信道:对每个传输块末尾添加一个CRC;编码分割,对于大于6144bit的传输块分割,并对每个码块添加CRC;信道编码;速率适配和物理层混合ARQ功能;比特级加扰;数据调制;DFT预编码;天线映射;至物理资源的映射:调度器分配一组用于上行链路传输的资源块对,用于承载UL-S_5g occ
torchvision.datasets.FashionMNIST报错[WinError 10054] 远程主机强迫关闭了一个现有的连接_torchvision.datasets下载mnist显示远程主机强迫关闭了一个现有的连接-程序员宅基地
文章浏览阅读1.5k次,点赞6次,收藏6次。项目场景: 在李沐老师视频课Softmax 回归 + 损失函数 + 图片分类数据集【动手学深度学习v2】中用到了FashionMNIST数据集。问题描述:trans = transforms.ToTensor()#下载到上一级目录的data文件中,下载的是训练数据集,类型时tensor,从网上下载mnist_train = torchvision.datasets.FashionMNIST( root="../data", train=True, transform=trans, down_torchvision.datasets下载mnist显示远程主机强迫关闭了一个现有的连接
Python 子类不可以直接访问父类的私有方法和私有属性_python 私有成员变量 子类没法调用?-程序员宅基地
文章浏览阅读2.7k次。子类对象不能在自己的方法内部直接访问父类的私有方法和私有属性。注意:在对象的方法内部是可以访问自己所在类的私有属性和私有方法。代码举例:class A(): #父类 def __init__(self): self.num1 =100 self.__num2 = 200 def __test(self): ..._python 私有成员变量 子类没法调用?
【完结篇】c# winfrom 工作流程图开发、自动表单开发、拖拽控件、流程图自定义拖拽连线、 全自动报表表单设计_c# 开发拖拽流程软件-程序员宅基地
文章浏览阅读2.1k次,点赞5次,收藏8次。报表配置完毕后,前端可以进行根据配置条件筛选结果。表单自由设计,支持全选、移动等功能。报表配置,根据表单自动配置报表。系统设置-角色与权限管理。流程节点配置-经办人。流程节点配置-可写字段。流程节点配置-流转设置。..._c# 开发拖拽流程软件
随便推点
天锐绿盾 | 如何防止开发部门源代码泄露、外泄?-程序员宅基地
文章浏览阅读1k次,点赞31次,收藏5次。天锐绿盾是一款专为企业设计的数据防泄密解决方案,尤其针对软件开发部门的源代码保护提供了多维度、全方位的防护措施。
IO密集型线程和CPU密集型线程_io密集型和cpu密集型 线程数-程序员宅基地
文章浏览阅读3k次。CPU密集任务只有在真正的多核CPU上才可能得到加速,而在单核CPU上,无论你开几个模拟的多线程该任务都不可能得到加速,因为CPU总的运算能力就只有这么多。CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作CPU读写IO(硬盘/内存)时,IO可以在很短的时间内完成,而CPU还有许多运算要处理,因此,CPU负载很高。IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等IO (硬盘/内存) 的读写操作,因此,CPU负载并不高。_io密集型和cpu密集型 线程数
Arduino编译错误解决办法:fork/exec:…\arm-none-eabi-g++.exe: The filename or extension is too long_ardinuo运行报错:exec: "/bin/arm-none-eabi-g++": file d-程序员宅基地
文章浏览阅读4.2k次,点赞2次,收藏6次。编译错误解决办法:fork/exec:…\arm-none-eabi-g++.exe: The filename or extension is too long内容来自Edge Impulse当使用Arduino编译STM或Arduino文件时,当要编译的目标文件列表超过命令行中的Windows最大字符数(32k)时,通常会引发此错误。如果使用的2.0版本以下IDE版本,可参考以下方法:如果是Arduino则使用前两种方法即可,Adafruit、esp32、STM32参照后面的方法1.在Ardu_ardinuo运行报错:exec: "/bin/arm-none-eabi-g++": file does not exist
Unicode的基本知识总结_61448 uncode是什么-程序员宅基地
文章浏览阅读680次。Unicode的基本知识总结前言一、Unicode是什么?二、Unicode的编码与实现1.Unicode的编码方式2.Unicode的实现方式总结前言秋招面试某公司的时候,面试官突然发难,问起了Unicode的相关知识,使我手足无措,今天抽出时间来专门学习整理一下相关知识一、Unicode是什么?Unicode,中文又称万国码、国际码、统一码、单一码,是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。二、Unicode._61448 uncode是什么
富文本编辑器:editor.md_editor编辑器-程序员宅基地
文章浏览阅读2.7k次,点赞5次,收藏21次。富文本编辑器Editormd简介Editor.md——功能非常丰富的编辑器,左端编辑,右端预览,非常方便,完全免费官网:https://pandao.github.io/editor.md/主要特征支持“标准” Markdown / CommonMark 和 Github 风格的语法,也可变身为代码编辑器;支持实时预览、图片(跨域)上传、预格式文本/代码/表格插入、代码折叠、搜索替换、只读模式、自定义样式主题和多语言语法高亮等功能;支持 ToC 目录(Table o_editor编辑器
一读就错的68个姓氏,第一个就读错了_任作为姓氏很多人读错-程序员宅基地
文章浏览阅读733次。一读就错的68个姓氏,第一个就读错了转载:http://cul.qq.com/a/20170414/032417.htm[摘要]我国有很多姓氏,看起来都是常见的字,一写就会,可是一读,就不是那个样子了,往往读错,让人啼笑皆非。我国有很多姓氏,看起来都是常见的字,一写就会,可是一读,就不是那个样子了,往往读错,让人啼笑皆非。中国的姓氏中,除了有生僻字,还有不少容易读错的姓_任作为姓氏很多人读错