基于tensorflow深度学习的猫狗分类识别-毕业设计_宠物细分识别模型-程序员宅基地
技术标签: tensorflow 深度学习 分类
基于tensorflow深度学习的猫狗分类识别

作者简介:机器学习,深度学习,卷积神经网络处理,图像处理
B站项目实战:https://space.bilibili.com/364224477
如果文章对你有帮助的话, 欢迎评论 点赞 收藏 加关注+
♂代码获取:@个人主页
目录
实验背景
近年来,深度学习在计算机视觉领域取得了巨大的成功,尤其是在图像分类任务上。图像分类是计算机视觉领域的基本问题之一,而猫狗分类作为图像分类中的经典问题,吸引了广泛的研究兴趣。猫狗分类问题具有很高的实际应用价值。在现实世界中,人们经常需要对动物进行分类,如在宠物识别、动物行为分析和动物保护等领域。传统的图像分类方法通常需要手工设计特征提取器和分类器,这在处理复杂的图像数据时面临着挑战。
深度学习通过学习端到端的特征提取和分类模型,不需要手动设计特征提取器,因此在猫狗分类问题上具有巨大的潜力。卷积神经网络(Convolutional Neural Networks,简称CNN)是深度学习中最常用的模型之一,特别适用于图像数据的处理。猫狗分类问题的研究可以帮助我们深入理解深度学习在图像分类任务中的应用,并且可以为其他图像分类问题的研究提供经验和指导。此外,研究人员还可以通过比较不同深度学习模型的性能和对比传统方法的效果,评估深度学习在猫狗分类问题上的优势和局限性。
此外,随着深度学习模型的不断发展和算力的提升,研究人员可以尝试更复杂的模型架构、数据增强技术和迁移学习方法,以进一步提高猫狗分类任务的准确性和鲁棒性。因此,基于深度学习的猫狗分类实验具有重要的研究价值,可以推动深度学习在图像分类领域的发展,同时为实际应用场景提供更好的解决方案。
实验目的
本实验的目的是基于深度学习方法进行猫狗分类,通过设计和训练深度神经网络模型,实现对输入图像进行准确的猫狗分类。具体目标包括:
1.建立一个高性能的猫狗分类模型:通过深度学习技术,构建一个能够从原始图像数据中自动学习到猫狗分类特征的神经网络模型。该模型能够准确地对输入图像进行分类,具备较高的分类准确率和泛化能力。
2.探索不同深度学习模型的性能差异:比较不同深度学习模型(如卷积神经网络、残差网络等)在猫狗分类任务上的性能表现,评估它们的准确率、召回率、精确率等指标,并分析其优势和不足之处。
3.优化模型性能:通过调整模型的超参数、网络结构以及训练策略等,进一步提高猫狗分类模型的性能。例如,可以尝试不同的激活函数、优化器、学习率调度等,以提高模型的收敛速度和泛化能力。
4.数据增强和处理:应用数据增强技术,如随机裁剪、旋转、翻转等,扩充训练数据集的多样性,提高模型对于各种场景和变化的鲁棒性。同时,对原始图像数据进行预处理,如图像归一化、均衡化等,以便更好地适应模型输入要求。
5.评估模型性能:使用独立的测试数据集对训练好的模型进行评估,计算分类准确率、混淆矩阵等指标,评估模型的性能。同时,可以与其他传统方法进行比较,验证基于深度学习的方法在猫狗分类问题上的优越性。
实验环境
Python3.9
Jupyter notebook
实验过程
1.加载数据
首先导入本次实验用到的第三方库
接着定义我们数据集的路径
定义训练集、测试集、验证集生成器
将生成器连接到文件夹中的数据
可视化一些数据图片,来个九宫格展示
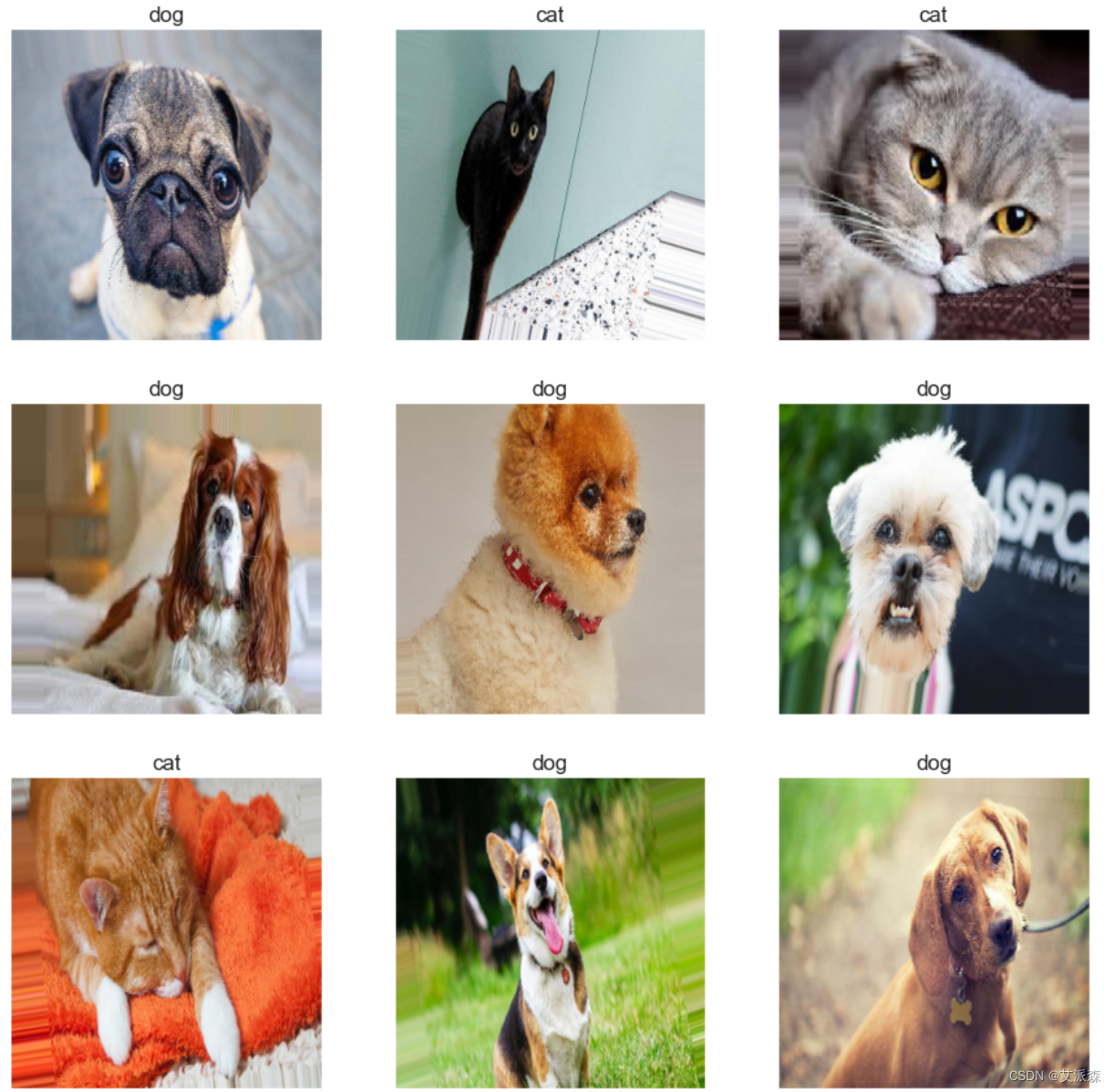
2.数据预处理
3.构建模型
构建模型、定义优化器
保存模型
4.训练模型
5.模型评估
将模型训练和验证的损失可视化出来、以及训练和验证的准确率
对验证数据集进行评估
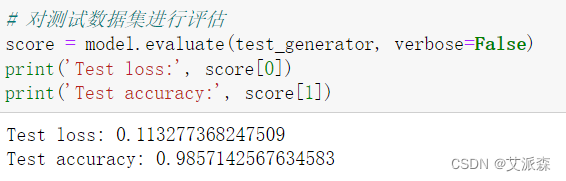
对测试数据集进行评估
将模型的混淆矩阵一热力图的形式展示
源代码
import numpy as np
import random
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.metrics import confusion_matrix
import seaborn as sns
sns.set(style='darkgrid', font_scale=1.4)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
from tensorflow import keras
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications.inception_resnet_v2 import InceptionResNetV2, preprocess_input
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
# 数据集路径
train_dir = './train'
test_dir = './test'
CFG = dict(
seed = 77,
batch_size = 16,
img_size = (299,299),
epochs = 5,
patience = 5
)
train_data_generator = ImageDataGenerator(
validation_split=0.15,
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
preprocessing_function=preprocess_input,
shear_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
val_data_generator = ImageDataGenerator(preprocessing_function=preprocess_input, validation_split=0.15)
test_data_generator = ImageDataGenerator(preprocessing_function=preprocess_input)
# 将生成器连接到文件夹中的数据
train_generator = train_data_generator.flow_from_directory(train_dir, target_size=CFG['img_size'], shuffle=True, seed=CFG['seed'], class_mode='categorical', batch_size=CFG['batch_size'], subset="training")
validation_generator = val_data_generator.flow_from_directory(train_dir, target_size=CFG['img_size'], shuffle=False, seed=CFG['seed'], class_mode='categorical', batch_size=CFG['batch_size'], subset="validation")
test_generator = test_data_generator.flow_from_directory(test_dir, target_size=CFG['img_size'], shuffle=False, seed=CFG['seed'], class_mode='categorical', batch_size=CFG['batch_size'])
# 样本和类的数量
nb_train_samples = train_generator.samples
nb_validation_samples = validation_generator.samples
nb_test_samples = test_generator.samples
classes = list(train_generator.class_indices.keys())
print('Classes:'+str(classes))
num_classes = len(classes)
# 可视化一些例子
plt.figure(figsize=(15,15))
for i in range(9):
ax = plt.subplot(3,3,i+1)
ax.grid(False)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
batch = train_generator.next()
imgs = (batch[0] + 1) * 127.5
label = int(batch[1][0][0])
image = imgs[0].astype('uint8')
plt.imshow(image)
plt.title('cat' if label==1 else 'dog')
plt.show()
base_model = InceptionResNetV2(weights='imagenet', include_top=False, input_shape=(CFG['img_size'][0], CFG['img_size'][1], 3))
x = base_model.output
x = Flatten()(x)
x = Dense(100, activation='relu')(x)
predictions = Dense(num_classes, activation='softmax', kernel_initializer='random_uniform')(x)
# 构建模型
model = Model(inputs=base_model.input, outputs=predictions)
for layer in base_model.layers:
layer.trainable = False
# 定义优化器
optimizer = Adam()
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 保存模型
save_checkpoint = keras.callbacks.ModelCheckpoint(filepath='model.h5', monitor='val_loss', save_best_only=True, verbose=1)
early_stopping = keras.callbacks.EarlyStopping(monitor='val_loss', patience=CFG['patience'], verbose=True)
# 训练模型
history = model.fit(
train_generator,
steps_per_epoch=nb_train_samples // CFG['batch_size'],
epochs=CFG['epochs'],
callbacks=[save_checkpoint,early_stopping],
validation_data=validation_generator,
verbose=True,
validation_steps=nb_validation_samples // CFG['batch_size'])
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs_x = range(1, len(loss_values) + 1)
plt.figure(figsize=(10,10))
plt.subplot(2,1,1)
plt.plot(epochs_x, loss_values, 'b-o', label='Training loss')
plt.plot(epochs_x, val_loss_values, 'r-o', label='Validation loss')
plt.title('Training and validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
# Accuracy
plt.subplot(2,1,2)
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
plt.plot(epochs_x, acc_values, 'b-o', label='Training acc')
plt.plot(epochs_x, val_acc_values, 'r-o', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend()
plt.tight_layout()
plt.show()
# 对验证数据集进行评估
score = model.evaluate(validation_generator, verbose=False)
print('Val loss:', score[0])
print('Val accuracy:', score[1])
# 对测试数据集进行评估
score = model.evaluate(test_generator, verbose=False)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# 混淆矩阵
y_pred = np.argmax(model.predict(test_generator), axis=1)
cm = confusion_matrix(test_generator.classes, y_pred)
# 热力图
plt.figure(figsize=(8,6))
sns.heatmap(cm, annot=True, fmt='d', cbar=True, cmap='Blues',xticklabels=classes, yticklabels=classes)
plt.xlabel('Predicted label')
plt.ylabel('True label')
plt.title('Confusion matrix')
plt.show()
智能推荐
React学习记录-程序员宅基地
文章浏览阅读936次,点赞22次,收藏26次。React核心基础
Linux查磁盘大小命令,linux系统查看磁盘空间的命令是什么-程序员宅基地
文章浏览阅读2k次。linux系统查看磁盘空间的命令是【df -hl】,该命令可以查看磁盘剩余空间大小。如果要查看每个根路径的分区大小,可以使用【df -h】命令。df命令以磁盘分区为单位查看文件系统。本文操作环境:red hat enterprise linux 6.1系统、thinkpad t480电脑。(学习视频分享:linux视频教程)Linux 查看磁盘空间可以使用 df 和 du 命令。df命令df 以磁..._df -hl
Office & delphi_range[char(96 + acolumn) + inttostr(65536)].end[xl-程序员宅基地
文章浏览阅读923次。uses ComObj;var ExcelApp: OleVariant;implementationprocedure TForm1.Button1Click(Sender: TObject);const // SheetType xlChart = -4109; xlWorksheet = -4167; // WBATemplate xlWBATWorksheet = -4167_range[char(96 + acolumn) + inttostr(65536)].end[xlup]
若依 quartz 定时任务中 service mapper无法注入解决办法_ruoyi-quartz无法引入ruoyi-admin的service-程序员宅基地
文章浏览阅读2.3k次。上图为任务代码,在任务具体执行的方法中使用,一定要写在方法内使用SpringContextUtil.getBean()方法实例化Spring service类下边是ruoyi-quartz模块中util/SpringContextUtil.java(已改写)import org.springframework.beans.BeansException;import org.springframework.context.ApplicationContext;import org.s..._ruoyi-quartz无法引入ruoyi-admin的service
CentOS7配置yum源-程序员宅基地
文章浏览阅读2w次,点赞10次,收藏77次。yum,全称“Yellow dog Updater, Modified”,是一个专门为了解决包的依赖关系而存在的软件包管理器。可以这么说,yum 是改进型的 RPM 软件管理器,它很好的解决了 RPM 所面临的软件包依赖问题。yum 在服务器端存有所有的 RPM 包,并将各个包之间的依赖关系记录在文件中,当管理员使用 yum 安装 RPM 包时,yum 会先从服务器端下载包的依赖性文件,通过分析此文件从服务器端一次性下载所有相关的 RPM 包并进行安装。_centos7配置yum源
智能科学毕设分享(算法) 基于深度学习的抽烟行为检测算法实现(源码分享)-程序员宅基地
文章浏览阅读828次,点赞21次,收藏8次。今天学长向大家分享一个毕业设计项目毕业设计 基于深度学习的抽烟行为检测算法实现(源码分享)毕业设计 深度学习的抽烟行为检测算法实现通过目前应用比较广泛的 Web 开发平台,将模型训练完成的算法模型部署,部署于 Web 平台。并且利用目前流行的前后端技术在该平台进行整合实现运营车辆驾驶员吸烟行为检测系统,方便用户使用。本系统是一种运营车辆驾驶员吸烟行为检测系统,为了降低误检率,对驾驶员视频中的吸烟烟雾和香烟目标分别进行检测,若同时检测到则判定该驾驶员存在吸烟行为。进行流程化处理,以满足用户的需要。
随便推点
STM32单片机示例:多个定时器同步触发启动_stm32 定时器同步-程序员宅基地
文章浏览阅读3.7k次,点赞3次,收藏14次。多个定时器同步触发启动是一种比较实用的功能,这里将对此做个示例说明。_stm32 定时器同步
android launcher分析和修改10,Android Launcher分析和修改9——Launcher启动APP流程(转载)...-程序员宅基地
文章浏览阅读348次。出处 : http://www.cnblogs.com/mythou/p/3187881.html本来想分析AppsCustomizePagedView类,不过今天突然接到一个临时任务。客户反馈说机器界面的图标很难点击启动程序,经常点击了没有反应,Boss说要优先解决这问题。没办法,只能看看是怎么回事。今天分析一下Launcher启动APP的过程。从用户点击到程序启动的流程,下面针对WorkSpa..._回调bubbletextview
Ubuntu 12 最快的两个源 个人感觉 163与cn99最快 ubuntu安装源下包过慢_un.12.cc-程序员宅基地
文章浏览阅读6.2k次。Ubuntu 12 最快的两个源 个人感觉 163与cn99最快 ubuntu下包过慢 1、首先备份Ubuntu 12.04源列表 sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup (备份下当前的源列表,有备无患嘛) 2、修改更新源 sudo gedit /etc/apt/sources.list (打开Ubuntu 12_un.12.cc
vue动态路由(权限设置)_vue动态路由权限-程序员宅基地
文章浏览阅读5.8k次,点赞6次,收藏86次。1.思路(1)动态添加路由肯定用的是addRouter,在哪用?(2)vuex当中获取到菜单,怎样展示到界面2.不管其他先试一下addRouter找到router/index.js文件,内容如下,这是我自己先配置的登录路由现在先不管请求到的菜单是什么样,先写一个固定的菜单通过addRouter添加添加以前注意:addRoutes()添加的是数组在export defult router的上一行图中17行写下以下代码var addRoute=[ { path:"/", name:"_vue动态路由权限
JSTL 之变量赋值标签-程序员宅基地
文章浏览阅读8.9k次。 关键词: JSTL 之变量赋值标签 /* * Author Yachun Miao * Created 11-Dec-06 */关于JSP核心库的set标签赋值变量,有两种方式: 1.日期" />2. 有种需求要把ApplicationResources_zh_CN.prope
VGA带音频转HDMI转换芯片|VGA转HDMI 转换器方案|VGA转HDMI1.4转换器芯片介绍_vga转hdmi带音频转换器,转接头拆解-程序员宅基地
文章浏览阅读3.1k次,点赞3次,收藏2次。1.1ZY5621概述ZY5621是VGA音频到HDMI转换器芯片,它符合HDMI1.4 DV1.0规范。ZY5621也是一款先进的高速转换器,集成了MCU和VGA EDID芯片。它还包含VGA输入指示和仅音频到HDMI功能。进一步降低系统制造成本,简化系统板上的布线。ZY5621方案设计简单,且可以完美还原输入端口的信号,此方案设计广泛应用于投影仪、教育多媒体、视频会议、视频展台、工业级主板显示、手持便携设备、转换盒、转换线材等产品设计上面。1.2 ZY5621 特性内置MCU嵌入式VGA_vga转hdmi带音频转换器,转接头拆解