Python爬取CNKI论文的信息_beautifulsoup爬取知网-程序员宅基地
技术标签: python
学了2天,简单的来总结一下。因为毕业设计是有关于推荐系统的相关内容,利用python爬取文献库是里面最基础的一步。
代码无任何难度,不懂得直接复制代码上网查询也能明白具体代码的意思。
选择CNKI的原因很简单:
1、知网的网页源代码中,查询的结果是存储在iframe里面的,单纯的python+request是很难读取到iframe里面的内容的。我爬了一个晚上没爬出来。。
2、CNKI的网页源代码中,查询的结果没有iframe等框架,相对来说容易爬取。
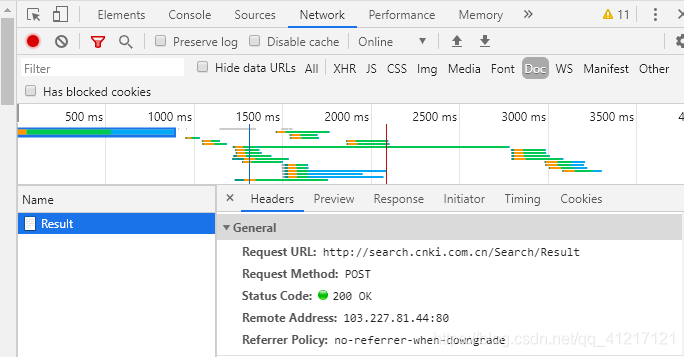
1、利用post的方法获取网页信息
CNKI和其他文献库不一样,当你在搜索框里搜索相应的内容的时候,跳转的页面的url还是原先未跳转的url,会出现url为定向的问题。此时不能用urlopen的方式采取get方法进行网页的爬取。我最终选择了request的表单数据提交方式。
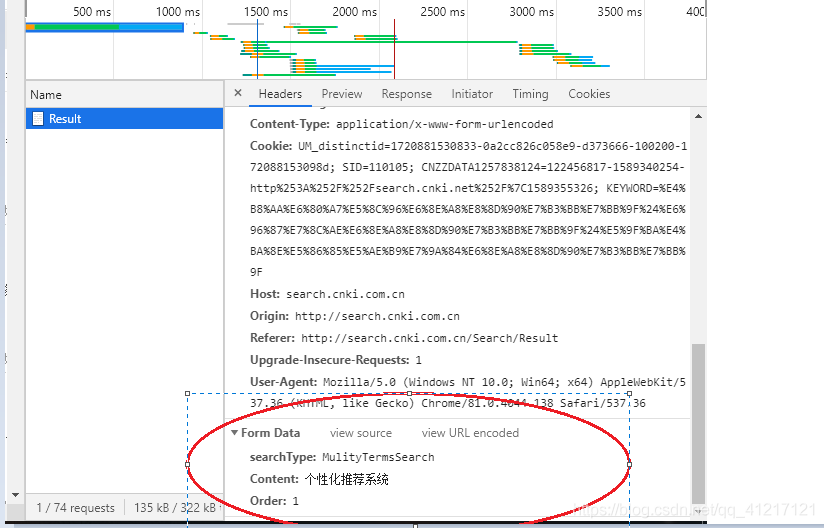
2、利用beautifulsoup进行网页相应标签的爬取
beautifulsoup对于网页源代码中的特定标签的读取特别方便,所以最终采用的还是beautifulsoup的方式。
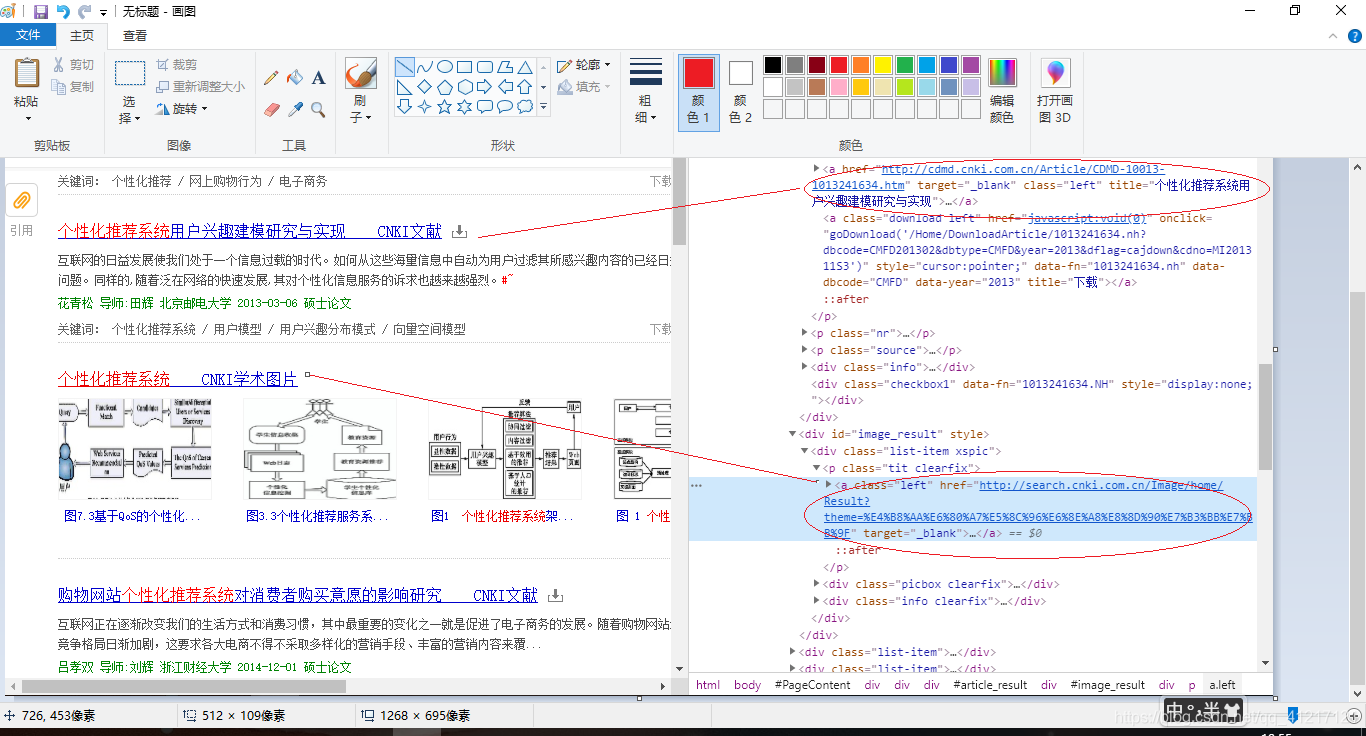
对于我个人的需求,我的爬取论文的情况对应的应该是第一种不包含任何图片,且有关键字提示;第二种不在我的爬取范围之内。
1、在beautifulsoup中,这两种链接的爬取区别区分不明显,且tag高度重合,所以此时我不能用beautifulsoup的find方法去读取a标签。
2、我的想法是一个论文的相应条目分开读取;
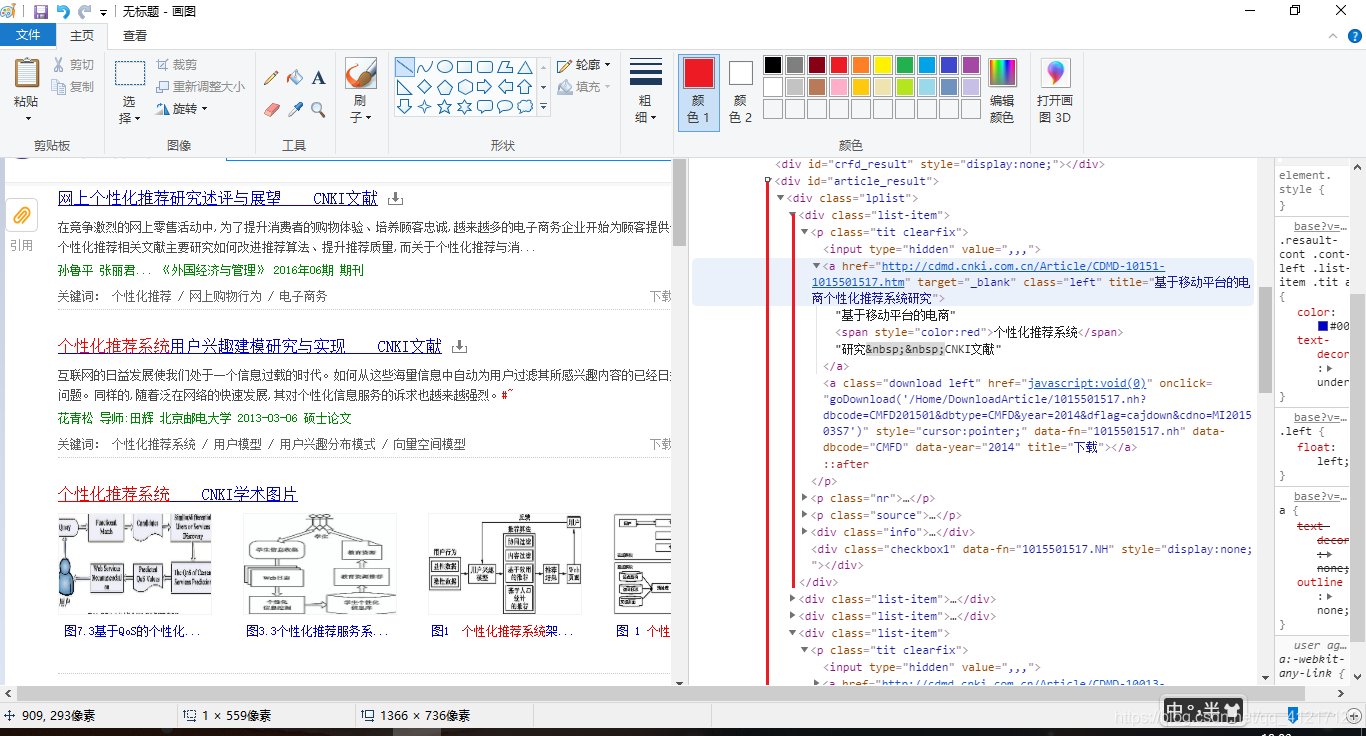
可以看出,搜索结果的一条结果,是在一个div class="list-item"里面的;而所有的搜索结果,是在一个div id = "article_result"里面的。所以我们的搜索方案现在就很明确了。
1、先将div id = "article_result"的内容全部爬取,里面包含了所有子的div class=“list-item”
2、针对每个div class=“list-item”,读取里面的论文题目和相关的关键字
为什么我不知觉读取所有的div class=“list-item”?因为通过观察可以发现,并不是所有的div class="list-item"标签里都会包含数据。在div id = "article_result"标签的范围之外,有很多div class="list-item"是不包含数据的。
3、利用beautifulsoup的方法将每个搜索结果读取,存入集合里面
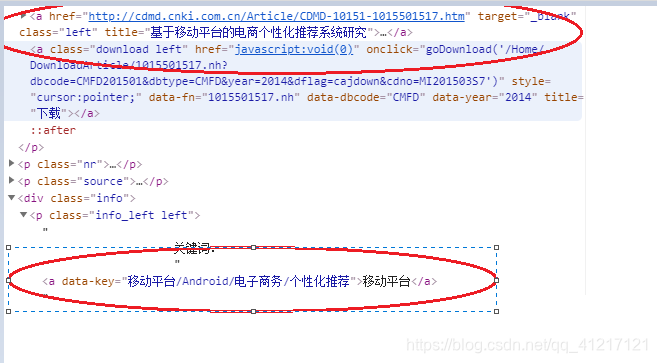
从图片的代码很容易得出,第一个圈的代码,我们需要从里面得出标题数据,数据在title属性里面;第二个圈得出的是关键词,数据在data-key属性里面。这里的解决方案可以利用正则表达式解决。
代码如下所示:
from bs4 import BeautifulSoup
from urllib.request import urlopen
import re
import random
import requests
url = "http://search.cnki.com.cn/Search/Result"
data = {
'searchType': 'MulityTermsSearch', 'Content': '基于内容的推荐系统'}
#此处的data存储的post所提交的参数,从第一步的图片能看的出来
titles =[]
#存储从CNKI读取的所有标题
tags = []
#存储读取的每个标题对应的关键字
res = requests.post(url, data=data)
html = res.text
soup = BeautifulSoup(html,'lxml')
sum_article = soup.find("div",{
"id":"article_result"})
sum_div = sum_article.find_all("div", {
"class":"list-item"})
for sub_div in sum_div:
#对于article里面的list-item作数据爬取
if sub_div != None:
sub_title = sub_div.find("a", {
"target": "_blank", "title": re.compile("(.+?)"),
"href": re.compile("http://(.*?).cnki.com.cn/Article/(.*?)")})
#此处用标签加上相应的正则表达式,可以爬出所有包含论文标题的数据
sub_tag = sub_div.find("a", {
"data-key": re.compile("(.+)")})
#此处用标签加上相应的正则表达式,可以爬出所有包含论文标题的关键字
titles.append(sub_title['title'])
tags.append(sub_tag['data-key'])
print(titles)
print(tags)
print(titles.__len__())
print(tags.__len__())
if tags.__len__() == titles.__len__():
print("长度相等")
#用来判断爬出的论文标题数量,和对应的关键字数量是否相等。相等即爬取正确`
建议可以去b站看一下莫烦python,讲的挺好的,可以快速入门以下基础。
智能推荐
ASP.NET MVC 模式-程序员宅基地
文章浏览阅读307次。ASP.NET MVC 是一个全新的Web应用框架ASP.NET 代表支撑应用框架的技术平台,表明ASP.NET MVC和传统的WebForm应用框架一样,都是建立在ASP.NET平台之上。MVC 表示该框架背后的设计思想,意味着ASP.NET MVC采用了MVC架构模式。MVC在20世纪70年代后期出现,产生于Xerox PARC施乐公司的帕洛阿尔托研究中心的Small..._aspnet mvvm
MacOS M1搭建Selenium环境_m1 mac selenium配置-程序员宅基地
文章浏览阅读350次。解压压缩包后,打开终端,进入当前chromedriver所在的路径,将chromedriver移动到默认路径(/usr/local/bin/)二、下载对应版本的浏览器驱动器:找到版本一致或最接近的版本的驱动器。若列表中含有selenium则表明安装成功。记得勾选上继承全局包,要不然会报错。_m1 mac selenium配置
UE4 OpenCV 插件 官方配置流程_ue4 opencv操作texture-程序员宅基地
文章浏览阅读4.6k次。谨以此片献给各种遇到坑的朋友。官网上的OpenCV 插件,根据github 上的描述 是针对UE4 4.16 版本以下的版本来提供的 OpenCV 采用的是3.0.0 , 也可以使用openCv 3.2.0环境描述:Ue4 4.15 OpenCV 3.2.0固有插件配置步骤:1, 创建一个C++ 的工程,打开后, 关闭即可。2,将OpenCV 的插件文件 解压缩之后, 将里面的文件..._ue4 opencv操作texture
使用Anaconda安装opencv-python-程序员宅基地
文章浏览阅读1w次,点赞3次,收藏11次。直接在cmd命令行输入:conda install --channel https://conda.anaconda.org/menpo opencv3 接着根据提示按Y即可
nyoj-236-心急的C小加_nyoj 心急的c小加-程序员宅基地
文章浏览阅读646次。#include#includestruct mubang{int x;int y;}a[5005];int cmp(const void *a,const void *b){struct mubang *c=(struct mubang *)a;struct mubang *d=(struct mubang *)b;if(c->x!=d->x)re_nyoj 心急的c小加
JavaEE基础知识讲解-程序员宅基地
文章浏览阅读1.7k次。学习JavaEE的你们是不是一头雾水呢? C/S client/server 客户端/服务器 B/C browser/server 浏览器/服务器 通过浏览器访问到对应页面,发送请求(同步请求,异步请求,ajax请求,会读接口文档)---服务器(云服务器:腾讯云服务器 阿里云服务器等等)---应用服务器Tomcat---匹配servlet---service业务处理---dao层 JDBC Hibemate,ORM---数据库---File---servlet(控制器Controller)MVC_javaee基础知识
随便推点
深度学习简介-程序员宅基地
文章浏览阅读910次,点赞28次,收藏19次。交互性检索是在检索用户不能构建良好的检索式(关键词)的情况下,通过与检索平台交流互动并不断修改检索式,从而获得较准确检索结果的过程。新闻推荐需要:获取用户请求,召回候选新闻,对候选新闻进行排序,最终给用户推出新闻。将用户持续浏览新闻的推荐过程看成一个决策过程,通过强化学习学习每一次推荐的最佳策略,提高用户的点击率。无人驾驶被认为是强化学习短期内能技术落地的一个应用方向,很多公司投入大量资源在无人驾驶上,其中百度的无人巴士“阿波龙”已经在北京、武汉等地展开试运营,自动无人驾驶的行车视野如下图所示。
前端开发工程师简历_前端简历-程序员宅基地
文章浏览阅读3.5w次,点赞102次,收藏685次。简历是什么找工作之前投递的个人信息和工作能力----不全面应该是:个人当前阶段的价值体现前者:我能卖多少钱;后者:我现在值多少钱建议:每隔半年/一年给自己做总结的时候写一份简历(相当于个人价值总结)面试要刻意、精心准备公司内部晋升答辩,需要精心准备(ppt、演讲基本要精心准备一个月的时间)面试,简历,同样需要精心准备目录面试官如何分析一份简历简历模板和内容个人信息教育经历专业技能工作经历项目经历体现自己的亮点课程总结注意:不要造假学历造假:学信网可查工作经历造假:可_前端简历
CentOS 通过yum安装gcc 4.8, 4.9, 5.2等高版本GCC_有gcc高版本的yum库-程序员宅基地
文章浏览阅读2.6k次。https://www.dwhd.org/20160724_085212.html_有gcc高版本的yum库
SpringBoot自动配置原理分析_springboot 自动配置分析与整合测试-程序员宅基地
文章浏览阅读320次。1起步依赖原理分析 1.1分析spring-boot-starter-parent 按住Ctrl点击pom.xml中的spring-boot-starter-parent,跳转到了spring-boot-starter-parent的pom.xml,xml配置如下(只摘抄了部分重点配置):<parent> <groupId>org.sp..._springboot 自动配置分析与整合测试
python2.7 Crypto 使用pip的安装方式 【橘小白】_python2.7 使用pycrypto-程序员宅基地
文章浏览阅读9.1k次。最近想要使用Crypto.Cipher 的AES模块,可总是找不到Crypto.Cipher接下来介绍几个坑1.AES是在pyCrypto中而不是crypto中2.这个pyCrypto中间的C一定要大写,不然也不能用接下来介绍正确的安装姿势1.首先需要现在一款编译器Microsoft Visual C++ Compiler for Python 2.7下载地址https://www.m..._python2.7 使用pycrypto
整数划分问题(递归&非递归)_n的划分种数,其中划分大于等于2非递归算法-程序员宅基地
文章浏览阅读2.9k次,点赞4次,收藏7次。递归算法:将正整数n表示成一系列正整数之和,n=n1+n2+...+nk,其中n1>=n2>=n3>=...>=nk>=1,k>=1。正整数n的这种表示称为正整数n的划分。正整数n的不同的划分个数城外正整数n的划分数,记作p(n)。例如,正整数6有如下11种不同的划分,所以p(6)=11。6;5+1;4+2;4+1+1;3+3;3+2+1;3+1+1+1;2+2+2_n的划分种数,其中划分大于等于2非递归算法