【论文简述】DSC-MVSNet: attention aware cost volume regularization based ondepthwise separable(CIS 2023)-程序员宅基地
一、论文简述
1. 第一作者:Song Zhang
2. 发表年份:2023
3. 发表期刊:Complex & Intelligent Systems
4. 关键词:MVS、三维重建、深度可分离卷积、通道注意力
5. 探索动机:基于深度学习的MVS方法很难平衡效率和有效性。
6. 工作目标:如何在保持效果的情况下显著减少计算量是研究的主要问题。
7. 核心思想:We propose the DSCMVSNet, a novel coarse-to-fine and end-to-end framework for more efficient and more accurate depth estimation in MVS.
- We propose a 3D UNet-shape network and firstly use the depthwise separable convolution for 3D cost volume regularization, which can effectively improve the model efficiency with performance maintained.
- We propose a 3D-Attention module to enhance the ability in cost volume regularization to fully aggregate the valuable information of cost volume and alleviate the problem of feature mismatching.
- We proposed an effective and efficient feature transfer module to upsample the LR depth map to obtain the HR depth map to achieve higher quality reconstruction.
8. 实验结果:
The proposed method outperforms the state-of-the-art method in dynamic areas with a significant error reduction of 21.3% while retaining its superiority in overall performance on KITTI. It also achieves the best generalization ability on the DDAD dataset in dynamic areas than the competing methods.
9.论文下载:
https://link.springer.com/content/pdf/10.1007/s40747-023-01106-3.pdf?pdf=button
https://github.com/zs670980918/DSC-MVSNet
二、实现过程
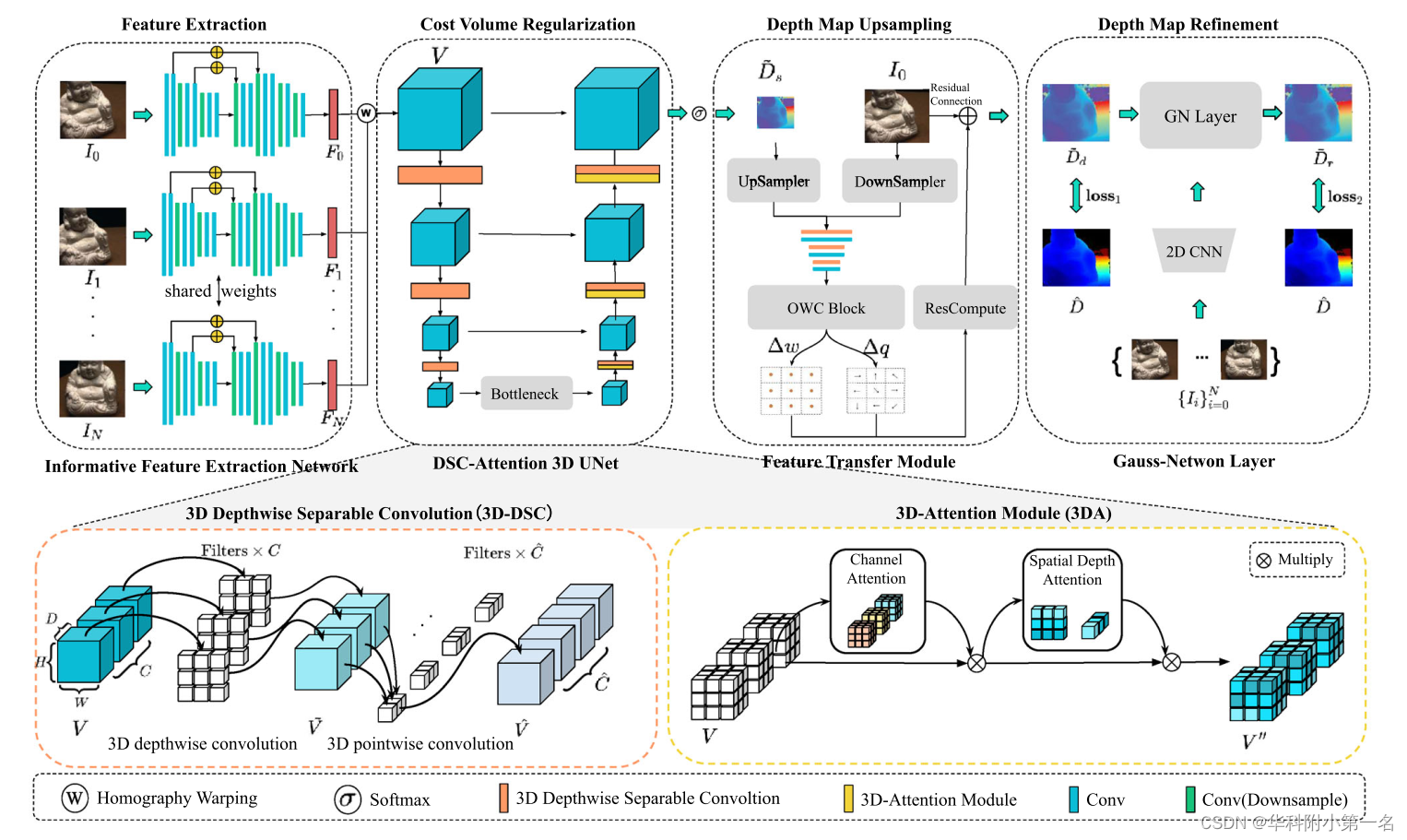
1. 总述
- 使用信息特征提取网络来提取相应的特征;
- 使用DSC-Attention 3D UNet来正则化粗糙代价体C×D×1/8H×1/8W;
- 使用特征转移模块来将LR深度图Ds∈1×1/8H×1/8W上采样到HR深度图Dd∈1×1/4H×1/4W;
- 利用输入图像和HR深度图,通过高斯牛顿网络层,得到改进后的深度图Dr∈1×1/4H×1/4W;
- 最后将改进后的深度图进行融合,得到点云。
2. 三维深度可分离卷积(3D-DSC)
将3D CNN分为3D depthwise卷积(depthwise是深度维度,可以对深度维度的代价体信息进行代价聚合)和3D pointwise卷积(pointwise是空间维度,在空间维度对代价体信息进行代价聚合)。
3D depthwise convolution。在每个通道的代价体上独立进行3D深度卷积,得到与通道无关的中间特征图,定义如式:
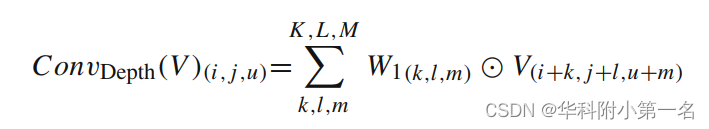
式中W1表示三维深度卷积的权值,V∈C×D×H×W表示代价体,i, j, u表示位置索引,K, L, M表示卷积的核大小。
3D pointwise convolution。3D逐点卷积作用于这些与通道无关的特征图,以聚合通道相关的信息,如定义:

式中,W2表示三维点向卷积的权值,V∈C×D×H×W表示中间特征图,N表示卷积的核大小。
这两个卷积依次执行,形成一个完整的卷积。其数学表达式定义为式:
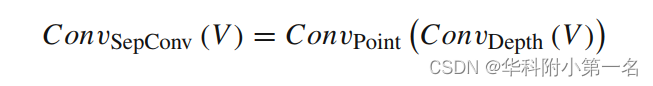
本文将3D-DSC正则化方案与其他主流正则化方案进行了理论比较,证明了该方案的有效性。用青色表示体素的感受野。水平是深度尺寸,垂直是通道尺寸。H和W分别表示高度和宽度。在这个图中,设H和W为一维。
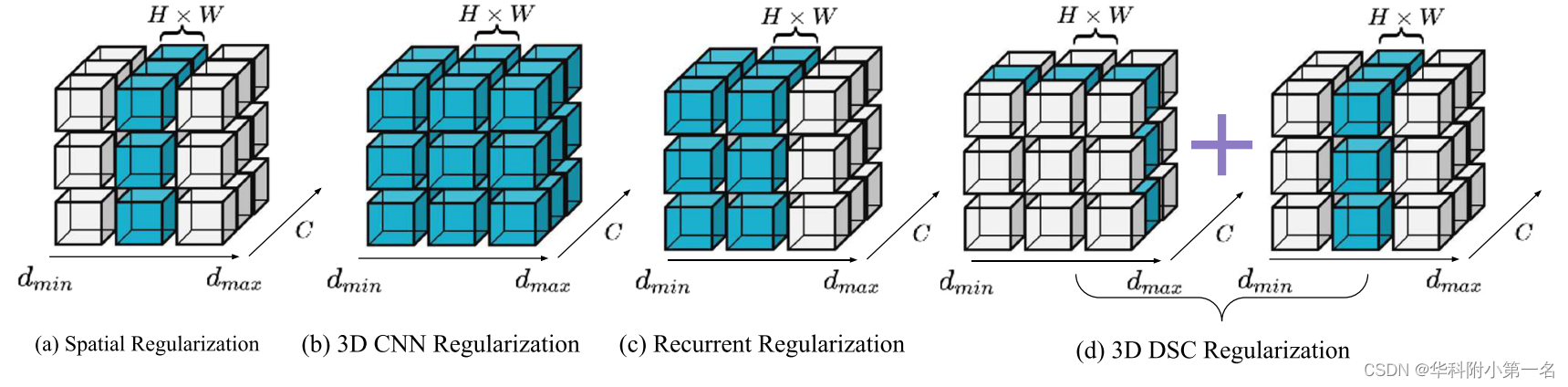
(a)空间正则化(spatial Regularization, SR),它过滤了不同深度的代价体。然而,由于感受野较小,SR的正则化结果受到很大影响;(b) 3D CNN正则化(3D-CNN),利用3D CNN获得更大的感受野进行代价体正则化。但它带来了更多的计算成本;(c)递归正则化是一种基于RNN的方法,提出了顺序处理,将代价体划分为与深度无关的代价图,以降低计算成本;(d)3D-DSC正则化是一种基于DSC的方法,将代价体分割成中间特征图,然后应用逐点卷积来建立这些中间特征图之间的关系,以保持模型的性能。与SR相比,我们的方法可以获得更大的接受野,而3D CNN正则化可以获得更好的性能,但也会带来更高的计算成本。然后比较了3D-DSC和3DCNN的效率。

3. 3D注意力模块(3DA)
3D-DSC虽然可以有效地聚合代价体信息,但仍然存在影响代价体质量的特征不匹配问题。当不同关键点的特征被错误匹配时,就会出现特征不匹配问题,这将导致代价体在不同深度处有相似置信度,最终导致深度估计不准确。具体而言,如图3下图所示,一个参考特征在不同深度匹配两个相似的源特征(佛像的两只手),不同深度的置信度在代价体上相似。这些相似的置信度将影响深度图的质量。并利用3DA来缓解这一问题。红色体素表示相似置信度;淡红色表示置信度减弱。

由于注意力机制可以通过计算不同的权重来突出重要信息,因此使用注意力机制来解决特征不匹配问题。3D注意力由两个模块组成,通过利用整个代价体的信息计算注意力权重来增强或削弱不同深度的相似的置信度,从而缓解了这一问题。
通道注意力块。通道注意力块对通道信息执行注意力。它由一个多层感知器(MLP)构造,作用于代价体V∈C×D×H×W的通道,以获得通道注意力增强权值Wˆ。将通道权值W与代价体V相乘,得到通道改进的代价体V‘∈C×D×H×W。通道注意力块定义为:
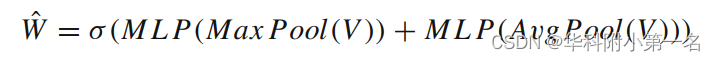
其中Max Pool为最大池化,AvgPool为平均池化。W∈C为通道注意力增强权值,两部分均共享MLP的权值。
空间深度注意力块。与普通注意力使用全感知(不区分空间和深度)不同,空间深度注意力块根据代价体的构成从两个不同维度感知代价信息,如:空间和深度。首先,使用核大小为1×7×7(相同深度的不同位置)的面向空间的各向异性卷积沿空间方向过滤代价体,以在保持相同深度的有用匹配信息的同时降低噪声。它为下一次面向深度的卷积提供了更准确的空间信息。然后用核大小为7×1×1(同一位置不同深度)的面向深度的各向异性卷积作用于深度维度,有效增强或减弱同一空间位置不同深度的匹配信息。最后,使用核大小为7×7×7的各向同性卷积,作用于多维(空间,深度),以充分聚合上述过程的信息。空间深度注意块的公式定义为:

式中σ为激活函数;W ̄∈1×D×H×W为空间深度权重;f1×7×7是空间向卷积,f7×1×1是深度向卷积,f7×7×7是整体卷积。
将这两个模块级联形成一个3D注意力模块,公式定义如下:

正则化后,在深度方向上使用softmax操作对[0,1]之间的所有值进行回归,形成深度估计的概率体P。最后,将不同深度假设平面值与概率体P相乘,得到LR深度图D~s。公式为:

4. 特征传输模块
上采样获得的高分辨率深度图直接影响点云结果的质量。为了获得高分辨率和精确的深度图,提出了一种用于低分辨率(LR)深度图上采样的特征传输模块(FTM)。
FTM的输入是一个三通道的参考图像I0∈3×H×W和单通道LR深度图Ds∈1×1/8H×1/8W。为了统一输入的尺度,首先使用双三次插值算法对LR深度图Ds进行上采样,得到更大尺度的深度图D~s∈1×1/4H×1/4W。将参考图像下采样为16通道图像I0∈16×1/4H×1/4W。在统一之后,提出了一个共同的偏移量和权重提取主干来获得参考图像和深度图的偏移量。该主干包含一个七层卷积特征提取网络、一个偏移卷积、一个权重卷积和一个sigmoid层。该主干定义为:
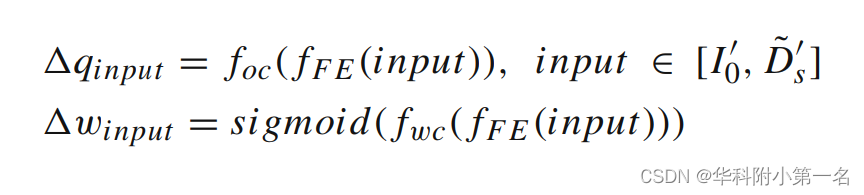
式中,fFE表示提取网络,foc表示偏移卷积,fwc表示权卷积,sigmoid表示sigmoid层。
然后使用OWC Block来计算权重∈k2/16×1/4H×1/4W和偏移∈k2/8×1/4H×1/4W,用于引导深度图上采样,其中k是一个超参数,设置k=12。具体来说,将相应的偏移量和权重相乘,然后通过PixelShuffle传递结果来获得目标偏移量和权重。然后利用偏移量引导特征采样,并将采样的特征与权值相乘得到最终结果。最后,通过残差相加块得到HR深度图。将上述过程的方程定义为:

其中fps表示PyTorch的的PixelShuffle操作,fgs表示grid_sample函数,Dres表示深度残差。
5. 信息特征提取网络
之前的方法很多仅使用顺序卷积操作从输入图像{Ii}i提取特征映射,这些图像只包含高级语义信息。低层次空间信息的丢失会影响重建结果的质量。因此,提出了一种利用跳跃连接传播低层次空间信息来聚合多层次特征信息的信息特征提取网络。这个网络有三个组件(Encoder, Decoder, Adjuster),架构如下表所示。每个卷积层代表一个卷积块、批归一化(BN)和ReLU。“sp”表示跳跃连接。

6. 代价体构建
定义为:

Vi是所有特征体的平均体。
7. 深度图改进
前一步得到的深度图质量不足,需要进一步改进。而在Fast-MVSNet中,高斯牛顿网络层是一种有效且高效的深度图改进模块。因此,使用高斯网络层对深度图改进图D∈1×1/4H×1/4W,用于MVS重建。
8. 训练损失
计算预测深度图与真实深度图之间的平均绝对值误差作为训练损失,如:

式中,D~d为HR深度图,D~r为改进后的深度图,D~为真实深度图,pvalid为真实深度图的有效点集,λ用于平衡loss1(p)和loss2(p)。在训练过程中,通常将λ设置为1.0。
9. 实验
9.1. 实现细节
设置RMSProp优化器,初始学习率设置为0.0008,每个epoch的衰减权值设为0.002。批大小设置为16,并在6个NVIDIA GTX 2080ti GPU设备上进行训练。
9.2. 与先进技术的比较

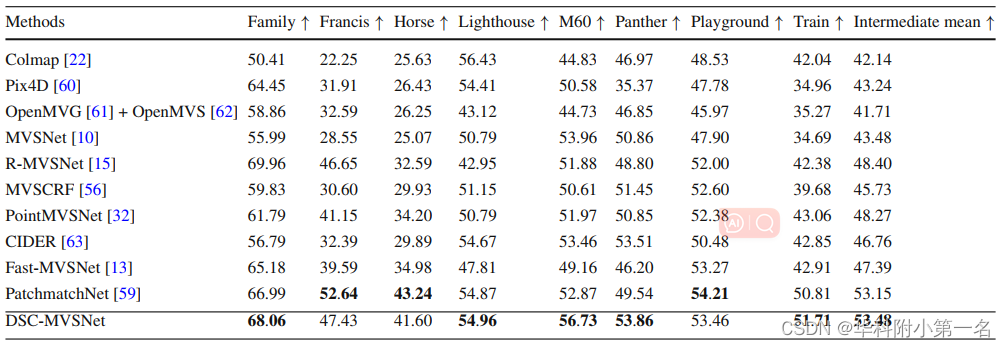

智能推荐
数据分析python代码开发工程化编写逻辑-个人总结_python工程化-程序员宅基地
文章浏览阅读1.1k次。团队开发git提交提交方法注意细节Byte-compiled / optimized / DLL filesC extensionsDistribution / packagingPyCharm filesJupyter NotebookUnit test / coverage reportsSphinx documentationDjangoFlask:thinking:协同开发细节模块管理根目录train.pypred.pydata配置argparseyaml_python工程化
动态规划--最优二叉搜索树_最优二叉搜索树算法实现-程序员宅基地
文章浏览阅读2k次。假期 2020.01.19题目描述最优二叉搜索树简单说来,就是使查找的过程消耗的次数最小,即大数据存储与查找方面的较优性能的算法。此处举例数字的存储与查找,如下图:其中pi为搜索概率,qi为不成功概率;思路分析对于寻找最优问题的算法,动态规划一直都是比较好的算法,这儿也是采用动态规划的算法实现该问题的解决。动态规划问题,一般是需要判断问题时候有最优子结构,那么此处设存在序列{s..._最优二叉搜索树算法实现
web.py 的基本使用方法_web.py怎么引用-程序员宅基地
文章浏览阅读450次。最近要快速做一些DEMO,所以直接用了web.py做后台web服务,记录下最基本最简单使用方法,理解一下它的逻辑。web.py的介绍就不说了,一搜就有,直接开始。我的环境是这样的:系统:ubuntu 22.04python: 3.8 (conda环境)如果大家用下来和我经历的不一样,那就再琢磨琢磨,总会解决的~_web.py怎么引用
Element-ui 对话框el-dialog点击关闭事件处理_el-dialog关闭事件-程序员宅基地
文章浏览阅读2w次,点赞8次,收藏9次。默认关闭的处理使用:visible.sync="dialogVisible"进行处理<el-dialog title="提示" :visible.sync="dialogVisible" width="30%" :before-close="handleClose"> <span>这是一段信息</span> <span slot="footer" class="dialog-footer"> <el-button @c_el-dialog关闭事件
Go必知必会系列:中间件与拦截器-程序员宅基地
文章浏览阅读1.7k次。在 Go 中,中间件(Middleware)是指用来连接两个或多个服务的组件或者模块。它通常被用于实现安全、验证、数据转换、监控等功能。
WebAssembly完全入门——了解wasm的前世今身-程序员宅基地
文章浏览阅读58次。前言接触WebAssembly之后,在google上看了很多资料。感觉对WebAssembly的使用、介绍、意义都说的比较模糊和笼统。感觉看了之后收获没有达到预期,要么是文章中的例子自己去实操不能成功,要么就是不知所云、一脸蒙蔽。本着业务催生技术的态度,这边文章就诞生了。前部分主要是对WebAssembly的背景做一些介绍,WebAssembly是怎么出现的,优势在哪儿。如果想直接开始撸代码试试..._-s use_xx wasm
随便推点
马化腾的电商梦,只能靠它来实现了~-程序员宅基地
文章浏览阅读655次,点赞23次,收藏18次。腾讯总裁刘炽平也曾称,腾讯在电商方面仍有非常大的发展空间,但仍希望能够循序渐进,一步一个脚印,逐渐打造适合自身的基础设施,在用户体验与商家投资回报率中找寻最佳平衡点。而视频号的话,没有什么引流品之类的低价品,只做利润品,商家拿着低价引流品去对接视频号主播,只会被主播看不起,认为没有实力。从视频号小店本身来看,当流量持续从商家的私域引入到小店成交,并促成源源不断的交易后,更便于养成用户在小店持续购买的习惯。现在已经在做视频号店铺的商家,和已经在做视频号的带货达人,都表示抖快淘目前是一片红海,
YOLOv5红外车辆检测pytorch实现_yolov5识别红外图像-程序员宅基地
文章浏览阅读343次。数据集收集与预处理: 首先,为了训练YOLOv5模型,需要收集大量标注有车辆目标的红外图像数据集。这些数据集应覆盖各种不同的场景和条件,以提高模型的泛化能力。然后,对图像进行预处理操作,包括图像大小调整、归一化、数据增强等,以提高模型的鲁棒性和适应性。模型架构: YOLOv5采用了一种基于卷积神经网络(CNN)的轻量级架构。它包括主干特征提取网络和检测头两个主要部分。特征金字塔网络: 为了在不同尺度下检测车辆目标,YOLOv5引入了特征金字塔网络。_yolov5识别红外图像
评估回归模型的指标:MSE、RMSE、MAE、R2、偏差和方差-程序员宅基地
文章浏览阅读2.6w次,点赞19次,收藏167次。在回归任务(对连续值的预测)中,常见的评估指标(Metric)有:平均绝对误差(Mean Absolute Error,MAE)、均方误差(Mean Square Error,MSE)、均方根误差(Root Mean Square Error,RMSE)和平均绝对百分比误差(Mean Absolute Percentage Error,MAPE),其中用得最为广泛的就是MAE和MSE。下面依次来..._r2分数
TinyBERT论文及代码详细解读-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏10次。General DistillationData Augmentation主要基于BERT预训练模型以及词向量(文中选择的Glove词向量)进行词级别的替换,实现数据增强。在官方代码中进行了17(NαN_\alphaNα)倍的增强,以GLUE/QQP数据集为例效果如下:id qid1 qid2 question1 question2 is_duplicate402555 536040 536041 how do i control my 40-something emotions _tinybert
基于贝塞尔曲线的变道轨迹规划_贝塞尔曲线 自动紧急换道-程序员宅基地
文章浏览阅读9k次,点赞14次,收藏118次。基于贝塞尔曲线的变道轨迹规划车辆的换道与超车是驾驶员常见的驾驶操作之一,无人驾驶车辆在行驶过程中也会频繁的面临此工况,车辆行驶过程中必须根据行驶环境中车车之间的相对速度与距离,以及车辆周边其他环境的变化信息,相应做出调整进而完成驾驶要求。在这个过程中,车辆必须对安全换道和超车的通过性做出准确评估,从而使车辆安全的运行。因此,无人车的轨迹规划是保证车辆安全行驶的重要组成部分。..._贝塞尔曲线 自动紧急换道
fedora14 15 16 apache mysql php yum安装_fedora 15如何安装zlib-程序员宅基地
文章浏览阅读714次。fedora14 15 16 apache mysql php yum安装2010年06月26日 星期六 10:14LAMP是Linux, Apache, MySQL, PHP的缩写.这篇教程将教你如何在一台Fedora 服务器上安装Apache2web服务器+PHP(mod_php) +MySQL .我已经测试无误,你可以放心使用。1. 前言_fedora 15如何安装zlib