中文实体命名识别工具使用汇总:Stanza、LAC、Ltp、Hanlp、foolnltk、NLTK、BosonNLP_pycharm中使用stanza工具,进行中文命名实体识别-程序员宅基地
实体命名识别
相关知识
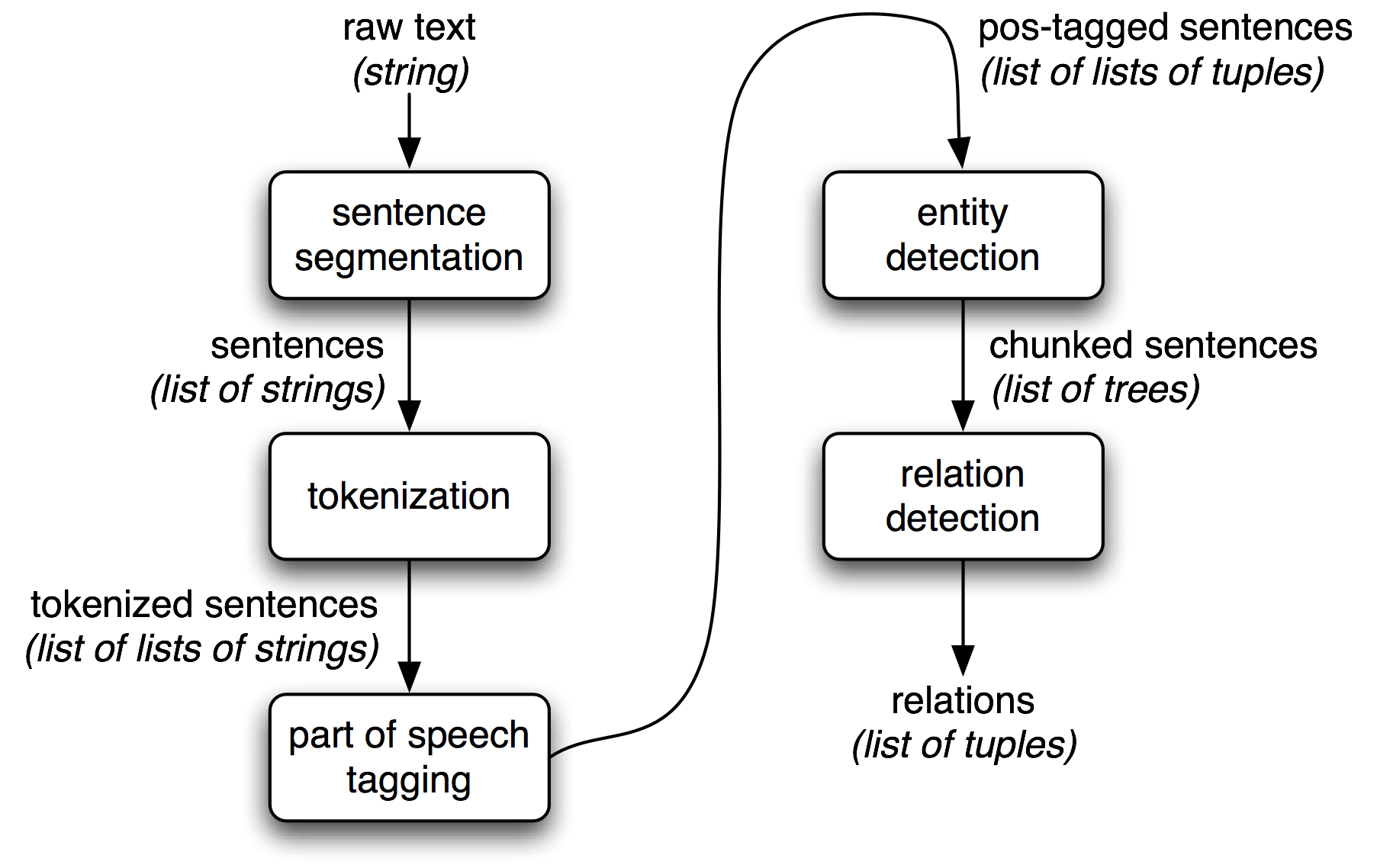
信息抽取:从数据库中抽取信息是容易的,但对于从自然文本中抽取信息则不那么直观。通常信息抽取的流程如下图:
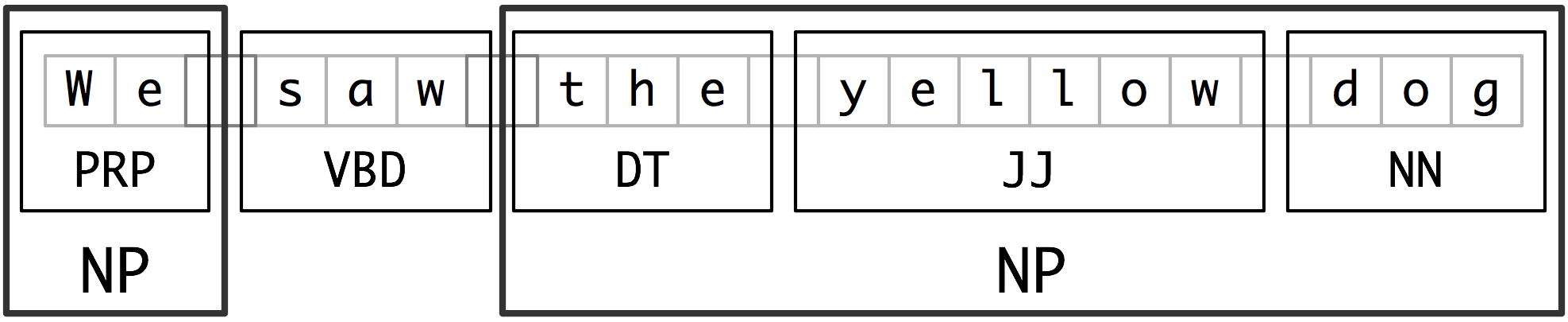
分块是实体识别(NER)使用的基本技术,词性标注是分块所需的最主要信息。下面以名词短语(NP)为例,展示如何分块。类似的还可以对动词短语,介词短语等进行分块。
命名实体识别(Named Entity Recognition,简称NER)用于识别文本中具有特定意义的实体。需要识别的实体可以分为三大类(实体类、时间类和数字类)和七小类(人名、机构名、地名、时间、日期、货币和百分比)。
Stanford CoreNLP 命名实体识别
一、简介:
CoreNLP是Java自然语言处理的一站式服务!CoreNLP使用户能够导出文本的语言注释,包括标记和句子边界、词性、命名实体、数值和时间值、依赖和选区解析、共指、情感、引用属性和关系。CoreNLP的核心是管道。管道接收原始文本,对文本运行一系列NLP注释器,并生成最终的注释集。管道产生核心文档,包含所有注释信息的数据对象,可以通过简单的API访问,并且可以序列化到Google协议缓冲区。
中文语料模型包中有一个默认的配置文件
StanfordCoreNLP-chinese.properties
指定pipeline的操作步骤以及对应的语料文件的位置,可以自定义配置文件,再引入代码中。实际上我们可能用不到所有的步骤,或者要使用不同的语料库,因此可以自定义配置文件,然后再引入。那在我的项目中,我就直接读取了该properties文件。(有时候我们只想使用ner功能,但不想使用其他功能,想去掉。然而,Stanford CoreNLP有一些局限,就是在ner执行之前,一定需要tokenize, ssplit, pos, lemma 的引入,大大增加了耗时。)
更多用法参见官网。
二、java版本使用
idea+maven搭建工程
1、在pom.xml 添加依赖:
<properties>
<corenlp.version>3.9.1</corenlp.version>
</properties>
<dependencies>
<!--CoreNLP的算法包-->
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-corenlp</artifactId>
<version>${corenlp.version}</version>
</dependency>
<!--英文语料包-->
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-corenlp</artifactId>
<version>3.9.1</version>
<classifier>models</classifier>
</dependency>
<!--中文预料包-->
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-corenlp</artifactId>
<version>${corenlp.version}</version>
<classifier>models-chinese</classifier>
</dependency>
</dependencies>
2、编写java程序
package com;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import edu.stanford.nlp.coref.CorefCoreAnnotations;
import edu.stanford.nlp.coref.data.CorefChain;
import edu.stanford.nlp.ling.CoreAnnotations;
import edu.stanford.nlp.ling.CoreLabel;
import edu.stanford.nlp.pipeline.Annotation;
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
import edu.stanford.nlp.semgraph.SemanticGraph;
import edu.stanford.nlp.semgraph.SemanticGraphCoreAnnotations;
import edu.stanford.nlp.trees.Tree;
import edu.stanford.nlp.trees.TreeCoreAnnotations;
import edu.stanford.nlp.util.CoreMap;
/**
代码思想:
将text字符串交给Stanford CoreNLP处理,
StanfordCoreNLP的各个组件(annotator)按“tokenize(分词), ssplit(断句), pos(词性标注), lemma(词元化), ner(命名实体识别), parse(语法分析), dcoref(同义词分辨)”顺序进行处理。
处理完后 List<CoreMap> sentences = document.get(SentencesAnnotation.class); 中包含了所有分析结果,遍历即可获知结果。
**/
public class StanfordChineseNlpExample2 {
public static void main(String[] args) throws Exception {
StanfordChineseNlpExample2 nlp=new StanfordChineseNlpExample2();
nlp.test();
}
public void test() throws Exception {
//构造一个StanfordCoreNLP对象,配置NLP的功能,如lemma是词干化,ner是命名实体识别等
StanfordCoreNLP pipeline = new StanfordCoreNLP("StanfordCoreNLP-chinese.properties");
String text = "袁隆平是中国科学院的院士,他于2009年10月到中国山东省东营市东营区永乐机场附近承包了一千亩盐碱地,";
long startTime = System.currentTimeMillis();
// 创造一个空的Annotation对象
Annotation document = new Annotation(text);
// 对文本进行分析
pipeline.annotate(document);
//获取文本处理结果
List<CoreMap> sentences = document.get(CoreAnnotations.SentencesAnnotation.class);
for (CoreMap sentence : sentences) {
// traversing the words in the current sentence
// a CoreLabel is a CoreMap with additional token-specific methods
for (CoreLabel token : sentence.get(CoreAnnotations.TokensAnnotation.class)) {
// 获取句子的token(可以是作为分词后的词语)
String word = token.get(CoreAnnotations.TextAnnotation.class);
System.out.println(word);
//词性标注
String pos = token.get(CoreAnnotations.PartOfSpeechAnnotation.class);
System.out.println(pos);
// 命名实体识别
String ne = token.get(CoreAnnotations.NormalizedNamedEntityTagAnnotation.class);
String ner = token.get(CoreAnnotations.NamedEntityTagAnnotation.class);
System.out.println(word + " | analysis : { original : " + ner + "," + " normalized : "
+ ne + "}");
//词干化处理
String lema = token.get(CoreAnnotations.LemmaAnnotation.class);
System.out.println(lema);
}
// 句子的解析树
Tree tree = sentence.get(TreeCoreAnnotations.TreeAnnotation.class);
System.out.println("句子的解析树:");
tree.pennPrint();
// 句子的依赖图
SemanticGraph graph =
sentence.get(SemanticGraphCoreAnnotations.CollapsedCCProcessedDependenciesAnnotation.class);
System.out.println("句子的依赖图");
System.out.println(graph.toString(SemanticGraph.OutputFormat.LIST));
}
long endTime = System.currentTimeMillis();
long time = endTime - startTime;
System.out.println("The analysis lasts " + time + " seconds * 1000");
// 指代词链
// 每条链保存指代的集合
// 句子和偏移量都从1开始
Map<Integer, CorefChain> corefChains = document.get(CorefCoreAnnotations.CorefChainAnnotation.class);
if (corefChains == null) {
return;
}
for (Map.Entry<Integer, CorefChain> entry : corefChains.entrySet()) {
System.out.println("Chain " + entry.getKey() + " ");
for (CorefChain.CorefMention m : entry.getValue().getMentionsInTextualOrder()) {
// We need to subtract one since the indices count from 1 but the Lists start from 0
List<CoreLabel> tokens = sentences.get(m.sentNum - 1).get(CoreAnnotations.TokensAnnotation.class);
// We subtract two for end: one for 0-based indexing, and one because we want last token of mention
// not one following.
System.out.println(
" " + m + ", i.e., 0-based character offsets [" + tokens.get(m.startIndex - 1).beginPosition()
+
", " + tokens.get(m.endIndex - 2).endPosition() + ")");
}
}
}
}
实体识别结果:
袁隆平 | analysis : {
original : PERSON, normalized : null}
是 | analysis : {
original : O, normalized : null}
中国 | analysis : {
original : ORGANIZATION, normalized : null}
科学院 | analysis : {
original : ORGANIZATION, normalized : null}
的 | analysis : {
original : O, normalized : null}
院士 | analysis : {
original : TITLE, normalized : null}
, | analysis : {
original : O, normalized : null}
他 | analysis : {
original : O, normalized : null}
于 | analysis : {
original : O, normalized : null}
2009年 | analysis : {
original : DATE, normalized : 2009-10-XX}
10月 | analysis : {
original : DATE, normalized : 2009-10-XX}
到 | analysis : {
original : O, normalized : null}
中国 | analysis : {
original : COUNTRY, normalized : null}
山东省 | analysis : {
original : STATE_OR_PROVINCE, normalized : null}
东营市 | analysis : {
original : CITY, normalized : null}
东营区 | analysis : {
original : FACILITY, normalized : null}
永乐 | analysis : {
original : FACILITY, normalized : null}
机场 | analysis : {
original : FACILITY, normalized : null}
附近 | analysis : {
original : O, normalized : null}
承包 | analysis : {
original : O, normalized : null}
了 | analysis : {
original : O, normalized : null}
一千 | analysis : {
original : NUMBER, normalized : 1000}
亩 | analysis : {
original : O, normalized : null}
盐 | analysis : {
original : O, normalized : null}
碱地 | analysis : {
original : O, normalized : null}
, | analysis : {
original : O, normalized : null}
The analysis lasts 989 seconds * 1000
大概可以识别到的类型有:人person、数字number、组织organization、头衔title、省/市/区/位置province/city/facility/location、日期/时间date/time
实时在线演示:https://corenlp.run/
三、python版本使用
- 安装斯坦福大学NLP组的Stanza 。(要求:Python3.6及以上的版本)
pip install stanza
- 下载中文模型打包文件
import stanza
stanza.download('zh')
出现问题:[WinError 10054] 远程主机强迫关闭了一个现有的连接。
解决方法:用梯子
- 使用
# coding utf-8
import stanza
# 可以通过pipeline预加载不同语言的模型,也可以通过pipeline选择不同的处理模块,还可以选择是否使用GPU:
zh_nlp = stanza.Pipeline('zh', use_gpu=False)
text = "马云在1998年7月31日出生于江苏省盐城市大丰区。"
doc = zh_nlp(text)
for sent in doc.sentences:
print("Sentence:" + sent.text) # 断句
print("Tokenize:" + ' '.join(token.text for token in sent.tokens)) # 中文分词
print("UPOS: " + ' '.join(f'{word.text}/{word.upos}' for word in sent.words)) # 词性标注(UPOS)
print("XPOS: " + ' '.join(f'{word.text}/{word.xpos}' for word in sent.words)) # 词性标注(XPOS)
print("NER: " + ' '.join(f'{ent.text}/{ent.type}' for ent in sent.ents)) # 命名实体识别
Sentence:马云在1998年7月31日出生于江苏省盐城市大丰区。
Tokenize:马云 在 1998 年 7 月 31 日 出生 于 江苏 省 盐城 市 大丰 区 。
UPOS: 马云/PROPN 在/ADP 1998/NUM 年/NOUN 7/NUM 月/NOUN 31/NUM 日/NOUN 出生/VERB 于/ADP 江苏/PROPN 省/PART 盐城/PROPN 市/PART 大丰/PROPN 区/PART 。/PUNCT
XPOS: 马云/NNP 在/IN 1998/CD 年/NNB 7/CD 月/NNB 31/CD 日/NNB 出生/VV 于/IN 江苏/NNP 省/SFN 盐城/NNP 市/SFN 大丰/NNP 区/SFN 。/.
NER: 马云/PERSON 1998年7月31日/DATE 江苏/GPE 盐城/GPE 大丰/GPE
更多详细信息见:斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
NLTK 命名实体识别
一、简介:
NLTK对于自然语言处理有很多开箱即用的API,本文主要介绍如何使用NLTK进行中文命名实体识别。由于NLTK不支持中文分词,所以本文使用了结巴分词。
二、搭建环境
环境:windows64+python3
前提:安装好python3,并且安装了numpy、matplotlib、pandas等一些常用的库
1、安装PyYAML模块和nltk模块
pip install pyyaml nltk
2、下载NLTK的数据包
方式一:界面下载
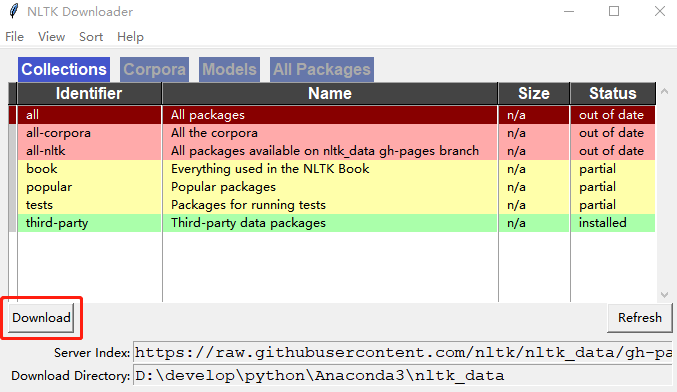
在pycharm中写一个python脚本,如下:
import nltk
nltk.download()
运行脚本,出现如下界面,选择all,设置下载路径,点击下载:
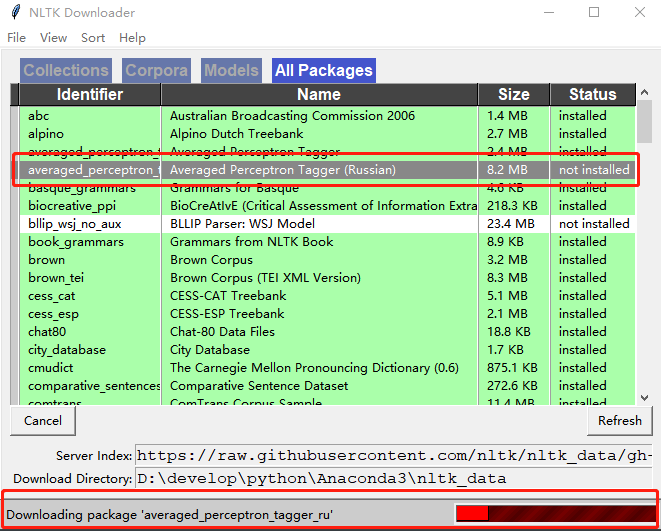
下载时间很长,如果有个别数据包无法下载,可切换到All Packages标签页,双击指定的包来进行下载。
方式二:命令行下载
创建名称为 nltk_data 的文件夹(比如我创建在了anacondas的目录下)
文件夹位置要求,程序会按照如下顺序去找该文件夹,所以,你创建的文件夹在以下目录即可:
Searched in:
- ‘C:\Users\10840/nltk_data’
- ‘D:\develop\python\Anaconda3\nltk_data’
- ‘D:\develop\python\Anaconda3\share\nltk_data’
- ‘D:\develop\python\Anaconda3\lib\nltk_data’
- ‘C:\Users\10840\AppData\Roaming\nltk_data’
- ‘C:\nltk_data’
- ‘D:\nltk_data’
- ‘E:\nltk_data’
- ’ ’
- ‘D:\develop\python\Anaconda3\nltk_data’
cmd 进入 nltk_data 文件夹目录,执行命令 python -m nltk.downloader all
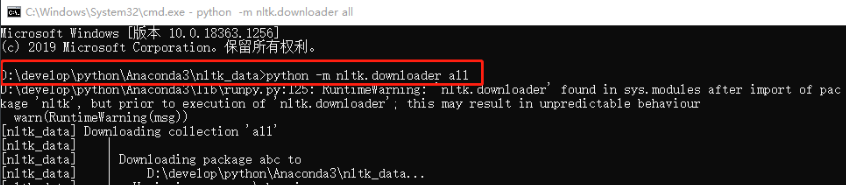
关于下载的问题:[win error 10054] 远程主机强迫关闭了一个现有的连接
解决方法:1.使用梯子 2.从国内别人上传的云盘下载(文末链接中有)3. 直接到官网下载数据包。
只要将下载的数据包复制到你的 Download Directory目录下即可
三、nltk使用
用NLTK来实现文本信息提取的方法,包含4步:分词,词性标注,(分块)命名实体识别,实体关系识别。
分块可以简单的基于经验,使用正则表达式来匹配,也可以使用基于统计的分类算法来实现,NLTK有提供基于正则的分块器。
nltk 不提供中文分词。
1、英文实体命名初体验
import sys
import importlib
importlib.reload(sys)
import nltk
article = "I came to Tsinghua University in Beijing" # 文章
tokens = nltk.word_tokenize(article) # 分词
print("tokens",tokens)
'''
tokens ['I', 'came', 'to', 'Tsinghua', 'University', 'in', 'Beijing']
'''
tagged = nltk.pos_tag(tokens) # 词性标注
print("tagged",tagged)
'''
tagged [('I', 'PRP'), ('came', 'VBD'), ('to', 'TO'), ('Tsinghua', 'NNP'), ('University', 'NNP'), ('in', 'IN'), ('Beijing', 'NNP')]
'''
entities = nltk.chunk.ne_chunk(tagged) # 命名实体识别
print(entities)
# 命名实体:确切的名词短语,指特定类型的个体,如日期、人、组织等
'''
(S
I/PRP
came/VBD
to/TO
(ORGANIZATION Tsinghua/NNP University/NNP)
in/IN
(GPE Beijing/NNP))
'''
NLTK 采用的是宾州中文树库标记:
2、使用nltk来处理中文资料
nltk 目前只能比较好的处理英文和其他的一些拉丁语系。由于中文汉字一个挨一个,nltk不支持。
所以可以采用其他分词工具对中文语料进行处理,再使用nltk对其进行实体识别。
分词工具有很多,这里使用 结巴分词。主页有详细介绍
结巴分词使用
1、安装
pip install jieba
2、使用:中文分词初体验
# encoding=utf-8
import jieba
jieba.enable_paddle() # 启动paddle模式。
strs=["我来到北京清华大学","乒乓球拍卖完了","中国科学技术大学"]
for str in strs:
seg_list = jieba.cut(str,use_paddle=True) # 使用paddle模式
print("Paddle Mode: " + '/'.join(list(seg_list)))
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("【全模式】: " + "/ ".join(seg_list))
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("【精确模式】: " + "/ ".join(seg_list))
seg_list = jieba.cut("他来到了网易杭研大厦")
print("【新词识别】: "+", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造")
print("【搜索引擎模式】: "+", ".join(seg_list))
'''
Paddle Mode: 我/来到/北京清华大学
Paddle Mode: 乒乓球/拍卖/完/了
Paddle Mode: 中国科学技术大学
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】: 他, 来到, 了, 网易, 杭研, 大厦
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, ,, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
'''
这样,把分词的结果输出到文件中,NLTK就可以拿来做实体识别了,比如下面:
# encoding=utf-8
import sys
import importlib
importlib.reload(sys)
import nltk
# 上中文
tokens = nltk.word_tokenize("我 来到 北京 清华大学") # 分词
print("tokens",tokens)
tagged = nltk.pos_tag(tokens) # 词性标注
print("tagged",tagged)
entities = nltk.chunk.ne_chunk(tagged) # 命名实体识别
print(entities)
'''
tokens ['我', '来到', '北京', '清华大学']
tagged [('我', 'JJ'), ('来到', 'NNP'), ('北京', 'NNP'), ('清华大学', 'NN')]
(S 我/JJ 来到/NNP 北京/NNP 清华大学/NN)
'''
参考资料:
python的nltk中文使用和学习资料汇总帮你入门提高
NLTK学习之四:文本信息抽取
foolnltk 命名实体识别
一、简介
foolnltk一个基于深度学习的中文分词工具,具有以下特点:
- 可能不是最快的开源中文分词,但很可能是最准的开源中文分词
- 基于 BiLSTM 模型训练而成
- 包含分词,词性标注,实体识别, 都有比较高的准确率
- 用户自定义词典
- 可以定制自己的模型
有python版本和java版本,详情请见
二、python版本使用
1、 安装
pip install foolnltk
2、 使用
#coding utf-8
import fool
import os
# 分词
text = "我来到北京清华大学"
print(fool.cut(text))
'''
[['我', '来到', '北京', '清华大学']]
'''
# 用户自定义词典
# 词典格式格式如下,词的权重越高,词的长度越长就越越可能出现, 权重值请大于 1
# 难受香菇 10
# 什么鬼 10
# 分词工具 10
# 北京 10
# 北京天安门 10
fool.load_userdict(os.getcwd()+'\\mydictionary')
# 词性标注
print(fool.pos_cut(text))
'''
[[('我', 'r'), ('来到', 'v'), ('北京', 'ns'), ('清华大学', 'nt')]]
'''
# 实体识别
words, ners = fool.analysis(text)
print(ners)
'''
[[(3, 9, 'org', '北京清华大学')]]
'''
Ltp 实体命名识别
一、简介
哈工大的LTP,免费使用但限流量,需要给钱才行
LTP4文档,啊!其实官方文档里面已经写的清清楚楚了!
这个也能支持用户自定义词典
二、使用
1、安装
pip install ltp
2、使用
import os
from ltp import LTP
ltp = LTP() # 默认加载 Small 模型
# user_dict.txt 是词典文件, max_window是最大前向分词窗口
ltp.init_dict(path=os.getcwd()+'\\mydictionary', max_window=4)
seg, hidden = ltp.seg(["马云在1996年11月29日来到杭州的阿里巴巴公司。"]) # 分词
print(seg)
'''
[['马云', '在', '1996年', '11月', '29日', '来到', '杭州', '的', '阿里巴巴', '公司', '。']]
'''
pos = ltp.pos(hidden) # 词性标注
print(pos)
'''
[['nh', 'p', 'nt', 'nt', 'nt', 'v', 'ns', 'u', 'nz', 'n', 'wp']]
'''
ner = ltp.ner(hidden) # 命名实体识别
tag, start, end = ner[0][0]
print(ner)
for tag, start, end in ner[0]:
print(tag, ":", "".join(seg[0][start:end + 1]))
'''
[[('Nh', 0, 0), ('Ns', 6, 6), ('Ni', 8, 9)]]
Nh : 马云
Ns : 杭州
Ni : 阿里巴巴公司
'''
LTP 提供最基本的三种实体类型人名 Nh、地名 Ns、机构名 Ni 的识别。
LAC 实体命名
一、简介
LAC全称Lexical Analysis of Chinese,是百度自然语言处理部研发的一款联合的词法分析工具,实现中文分词、词性标注、专名识别等功能。该工具具有以下特点与优势:
- 效果好:通过深度学习模型联合学习分词、词性标注、专名识别任务,词语重要性,整体效果F1值超过0.91,词性标注F1值超过0.94,专名识别F1值超过0.85,效果业内领先。
- 效率高:精简模型参数,结合Paddle预测库的性能优化,CPU单线程性能达800QPS,效率业内领先。
- 可定制:实现简单可控的干预机制,精准匹配用户词典对模型进行干预。词典支持长片段形式,使得干预更为精准。
- 调用便捷:支持一键安装,同时提供了Python、Java和C++调用接口与调用示例,实现快速调用和集成。
- 支持移动端: 定制超轻量级模型,体积仅为2M,主流千元手机单线程性能达200QPS,满足大多数移动端应用的需求,同等体积量级效果业内领先。
二、python版本使用
1、安装
pip install lac
2、使用
from LAC import LAC
# 装载LAC模型
lac = LAC(mode='lac')
# 单个样本输入,输入为Unicode编码的字符串
text = u"马云来到北京清华大学"
lac_result = lac.run(text)
print(lac_result)
'''
[['马云', '来到', '北京清华', '大学'], ['PER', 'v', 'ORG', 'n']]
'''
# 批量样本输入, 输入为多个句子组成的list,平均速率更快
texts = [u"LAC是个优秀的分词工具", u"百度是一家高科技公司"]
lac_result = lac.run(texts)
print(lac_result)
'''
[[['LAC', '是', '个', '优秀', '的', '分词', '工具'], ['nz', 'v', 'q', 'a', 'u', 'n', 'n']],
[['百度', '是', '一家', '高科技', '公司'], ['ORG', 'v', 'm', 'n', 'n']]]
'''

控制台输出以上内容,这个是初始化异常日志,不碍事,不喜欢的可以通过升级 paddlepaddle 版本到1.8以上 来关闭
pip install paddlepaddle==1.8
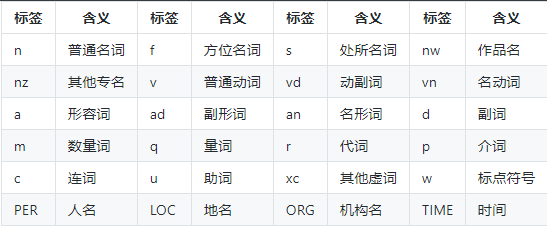
词性和专业名词类别:(专业名词只能识别4种:人物、地名、机构名、时间)
BosonNLP 实体识别
这个现在官方不给 SDK 的 tooken 了,所以不能用了,但是在线演示平台挺绚丽的。
一、简介
BosonNLP实体识别引擎基于自主研发的结构化信息抽取算法,F1分数达到81%,相比于StanfordNER高出7个百分点。通过对行业语料的进一步学习,可以达到更高的准确率。
二、python版本使用
1、安装
pip install bosonnlp
2、使用
from bosonnlp import BosonNLP
import os
nlp = BosonNLP(os.environ['BOSON_API_TOKEN'])
nlp.ner('杨超越在1998年7月31日出生于江苏省盐城市大丰区。', sensitivity=2)
Hanlp 实体识别
一、简介
HanLP是一系列模型与算法组成的NLP工具包,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。内部算法经过工业界和学术界考验。目前,基于深度学习的HanLP 2.0正处于alpha测试阶段,未来将实现知识图谱、问答系统、自动摘要、文本语义相似度、指代消解、三元组抽取、实体链接等功能。
我们介绍的Pyhanlp是HanLP1.x的Python接口,支持自动下载与升级HanLP1.x,兼容py2、py3。
二、python版本使用
1、安装
安装JDK
JDK官方下载地址
JDK的安装与环境变量配置
注意 保证JDK的位数、操作系统位数和Python位数一致。
安装Pyhanlp
pip install pyhanlp
2、使用
# coding utf-8
import pyhanlp
text = '杨超越在1998年7月31日出生于江苏省盐城市大丰区。'
NLPTokenizer = pyhanlp.JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer') # 加载模型
NER = NLPTokenizer.segment(text) # 命名实体识别
print(NER)
'''
[杨超越/nr, 在/p, 1998年7月31日/t, 出生/v, 于/p, 江苏省盐城市/ns, 大丰区/ns, 。/w]
'''
不像前面介绍的几个工具可以直接获得实体,hanlp需要从词性标注里面提取实体,
人名nr、地名ns、机名nt、时间t。
智能推荐
稀疏编码的数学基础与理论分析-程序员宅基地
文章浏览阅读290次,点赞8次,收藏10次。1.背景介绍稀疏编码是一种用于处理稀疏数据的编码技术,其主要应用于信息传输、存储和处理等领域。稀疏数据是指数据中大部分元素为零或近似于零的数据,例如文本、图像、音频、视频等。稀疏编码的核心思想是将稀疏数据表示为非零元素和它们对应的位置信息,从而减少存储空间和计算复杂度。稀疏编码的研究起源于1990年代,随着大数据时代的到来,稀疏编码技术的应用范围和影响力不断扩大。目前,稀疏编码已经成为计算...
EasyGBS国标流媒体服务器GB28181国标方案安装使用文档-程序员宅基地
文章浏览阅读217次。EasyGBS - GB28181 国标方案安装使用文档下载安装包下载,正式使用需商业授权, 功能一致在线演示在线API架构图EasySIPCMSSIP 中心信令服务, 单节点, 自带一个 Redis Server, 随 EasySIPCMS 自启动, 不需要手动运行EasySIPSMSSIP 流媒体服务, 根..._easygbs-windows-2.6.0-23042316使用文档
【Web】记录巅峰极客2023 BabyURL题目复现——Jackson原生链_原生jackson 反序列化链子-程序员宅基地
文章浏览阅读1.2k次,点赞27次,收藏7次。2023巅峰极客 BabyURL之前AliyunCTF Bypassit I这题考查了这样一条链子:其实就是Jackson的原生反序列化利用今天复现的这题也是大同小异,一起来整一下。_原生jackson 反序列化链子
一文搞懂SpringCloud,详解干货,做好笔记_spring cloud-程序员宅基地
文章浏览阅读734次,点赞9次,收藏7次。微服务架构简单的说就是将单体应用进一步拆分,拆分成更小的服务,每个服务都是一个可以独立运行的项目。这么多小服务,如何管理他们?(服务治理 注册中心[服务注册 发现 剔除])这么多小服务,他们之间如何通讯?这么多小服务,客户端怎么访问他们?(网关)这么多小服务,一旦出现问题了,应该如何自处理?(容错)这么多小服务,一旦出现问题了,应该如何排错?(链路追踪)对于上面的问题,是任何一个微服务设计者都不能绕过去的,因此大部分的微服务产品都针对每一个问题提供了相应的组件来解决它们。_spring cloud
Js实现图片点击切换与轮播-程序员宅基地
文章浏览阅读5.9k次,点赞6次,收藏20次。Js实现图片点击切换与轮播图片点击切换<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title></title> <script type="text/ja..._点击图片进行轮播图切换
tensorflow-gpu版本安装教程(过程详细)_tensorflow gpu版本安装-程序员宅基地
文章浏览阅读10w+次,点赞245次,收藏1.5k次。在开始安装前,如果你的电脑装过tensorflow,请先把他们卸载干净,包括依赖的包(tensorflow-estimator、tensorboard、tensorflow、keras-applications、keras-preprocessing),不然后续安装了tensorflow-gpu可能会出现找不到cuda的问题。cuda、cudnn。..._tensorflow gpu版本安装
随便推点
物联网时代 权限滥用漏洞的攻击及防御-程序员宅基地
文章浏览阅读243次。0x00 简介权限滥用漏洞一般归类于逻辑问题,是指服务端功能开放过多或权限限制不严格,导致攻击者可以通过直接或间接调用的方式达到攻击效果。随着物联网时代的到来,这种漏洞已经屡见不鲜,各种漏洞组合利用也是千奇百怪、五花八门,这里总结漏洞是为了更好地应对和预防,如有不妥之处还请业内人士多多指教。0x01 背景2014年4月,在比特币飞涨的时代某网站曾经..._使用物联网漏洞的使用者
Visual Odometry and Depth Calculation--Epipolar Geometry--Direct Method--PnP_normalized plane coordinates-程序员宅基地
文章浏览阅读786次。A. Epipolar geometry and triangulationThe epipolar geometry mainly adopts the feature point method, such as SIFT, SURF and ORB, etc. to obtain the feature points corresponding to two frames of images. As shown in Figure 1, let the first image be and th_normalized plane coordinates
开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先抽取关系)_语义角色增强的关系抽取-程序员宅基地
文章浏览阅读708次,点赞2次,收藏3次。开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先关系再实体)一.第二代开放信息抽取系统背景 第一代开放信息抽取系统(Open Information Extraction, OIE, learning-based, 自学习, 先抽取实体)通常抽取大量冗余信息,为了消除这些冗余信息,诞生了第二代开放信息抽取系统。二.第二代开放信息抽取系统历史第二代开放信息抽取系统着眼于解决第一代系统的三大问题: 大量非信息性提取(即省略关键信息的提取)、_语义角色增强的关系抽取
10个顶尖响应式HTML5网页_html欢迎页面-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏51次。快速完成网页设计,10个顶尖响应式HTML5网页模板助你一臂之力为了寻找一个优质的网页模板,网页设计师和开发者往往可能会花上大半天的时间。不过幸运的是,现在的网页设计师和开发人员已经开始共享HTML5,Bootstrap和CSS3中的免费网页模板资源。鉴于网站模板的灵活性和强大的功能,现在广大设计师和开发者对html5网站的实际需求日益增长。为了造福大众,Mockplus的小伙伴整理了2018年最..._html欢迎页面
计算机二级 考试科目,2018全国计算机等级考试调整,一、二级都增加了考试科目...-程序员宅基地
文章浏览阅读282次。原标题:2018全国计算机等级考试调整,一、二级都增加了考试科目全国计算机等级考试将于9月15-17日举行。在备考的最后冲刺阶段,小编为大家整理了今年新公布的全国计算机等级考试调整方案,希望对备考的小伙伴有所帮助,快随小编往下看吧!从2018年3月开始,全国计算机等级考试实施2018版考试大纲,并按新体系开考各个考试级别。具体调整内容如下:一、考试级别及科目1.一级新增“网络安全素质教育”科目(代..._计算机二级增报科目什么意思
conan简单使用_apt install conan-程序员宅基地
文章浏览阅读240次。conan简单使用。_apt install conan