【2024泰迪杯】C 题:竞赛论文的辅助自动评阅 问题分析及Python 代码实现_2024泰迪杯题目分析-程序员宅基地
技术标签: 2024泰迪杯C题 python 辅助自动评阅 数学建模入门到精通 竞赛论文 2024泰迪杯 AI 自动评阅
更新时间;2024-4-6
【2024泰迪杯】C 题:竞赛论文的辅助自动评阅 Python 代码实现
2024 年(第 12 届)“泰迪杯”数据挖掘挑战赛 C 题:竞赛论文的辅助自动评阅

相关链接
1 题目
一、问题背景
近年来我国各领域各层次学科竞赛百花齐放,层出不穷,学生参与度也越来越高。随着参赛队伍的增加,评阅论文的工作量急剧增加,这对评阅论文的人力要求也越来越大。因此引入机器辅助评阅成为竞赛主办方的现实需求。
在学术界,建立基于 AI 的学术论文自动评审模型已得到了许多研究者的关注。论文的自动评阅涉及多种传统的自然语言处理技术如文本分类、信息抽取、论辩挖掘等。近年来,随着深度学习和自然语言处理技术的不断发展,特别是以 GPT 为代表的大语言模型的出现,进一步促进了论文自动评阅技术的发展,使得利用 AI 进行文本的自动评阅变得越来越可行,逐步从实验室走向学校和更多组织机构,成为当前的技术热点。但是在特定领域实现论文自动评阅仍然存在很多挑战,需要利用预训练的大语言模型适配具体的应用场景来解决问题。
二、解决问题
1、构造论文质量特征
每个指标的分数范围为 0-10 分。
(1) 论文的完整性评价
对照赛题,比对竞赛论文中相关问题的章节或段落,对论文的完整性进行评价。评估竞赛论文是否能完整解答赛题,并给出评价论文完整性的技术手段和评分标准。
(2) 论文有无实质性工作
对照赛题评阅要点,查找竞赛论文中相关问题的章节或段落,考察论文是否就赛题问题做出了相关的研究。需给出相关的技术方法和评价标准。
(3) 摘要质量
摘要与内容的一致性评价。评价摘要是否如实反映正文的中心思想,即衡量内容摘要与正文的相关性、一致性。需给出摘要质量评价指标及其依据。
(4) 写作水平评价
评价文字流畅性、写作规范(图、表、摘要)性和论文逻辑性。在传统论文评分(essay scoring)技术基础上,从文本通顺、立意分析、篇章结构、论证挖掘等维度进行探索,挖掘文本蕴含的论点论据、论证关系、结构信息,结合论证挖掘角度评估论文一致性、逻辑性,综合给出论文写作水平的评分。
2、竞赛论文辅助评分
根据上面构造的各项评分指标建立论文的整体评分模型,根据提供的论文集,按照十分制给出每篇论文的综合评分,将结果保存到 result.xlsx 文件中。综合评分结果要求满足如下限制条件:
8-10 分的不超过 3%;
6-7 分的不少于 10%,6-10 分不超过 15%;
4-5 分不少于 20%,4-10 分不超过 35%;
其他的为 0-3 分。
一般而言,在综合评分中论文的完整性和写作水平的分数占比之和不超过 40%。
注 1 若使用预训练的大语言模型完成赛题任务,需要给出实现过程,如提问时使用的提示词及如何进一步利用提问结果。
注 2 自 2022 年底 ChatGPT 发布以来,大语言模型的能力突飞猛进,可考虑将大语言模型技术应用于本次竞赛。一方面可考虑使用 ChatGPT、讯飞星火、文心一言、智谱清言等国内外大模型接口,基于大语言模型设计算法和构建合适的提示词等,辅助完成本赛题的任务。另一方面也可考虑微调训练开源大语言模型,例如 ChatGLM、Qwen、Baichuan 等系列开源大语言模型,设计训练任务,让知识赋能大语言模型以更好地解决问题。
三、附件说明
附件 1 为竞赛论文集,附件 2 为赛题和参考评阅标准,附件 3 为 result.xlsx 的结果模板。
表 1 result.xlsx 样例
| 论文编号 | 完整性 | 实质性 | 摘要 | 写作水平 | 综合评分 |
|---|---|---|---|---|---|
| C001 | …… | …… | …… | …… | …… |
2 问题分析
2.1 问题一
论文的完整性评价。
- 使用文本分析技术,如 PdfMiner是一个功能强大的PDF处理工具,可以根据实际需要进一步对提取的文本内容进行分析,识别论文结构中与赛题相关的章节或段落,比如问题陈述、模型建立、模型求解、结果分析等。
- 评估论文结构的逻辑完整性和条理性,查看论文是否按照标准的学术论文结构进行组织,并对每个部分的逻辑顺序进行评估。
2.2 问题二
评估论文是否就赛题问题做出了相关的研究,则使用自然语言处理的方法,抽取论文每个段落的关键词,与赛题给出的关键词进行对比评分。
- 首先使用自然语言处理的方法,如分词、词性标注和句法分析,将论文分成段落或句子。
- 然后采用主题建模方法,如Latent Dirichlet Allocation (LDA)或其它话题模型,从文本中识别与赛题相关的主题或话题,以确定哪些部分涉及与赛题相关的内容。
- 结合语义分析技术,如词向量模型或深度学习模型,量化评估问题陈述部分是否包含了关键信息,例如问题的关键词、目标和约束条件。
2.3 问题三
衡量论文摘要与正文的相关性和一致性,并对摘要进行质量评价打分,可以借助文本相似度、主题模型、关键词抽取和语义分析等方法。
(1)文本相似度分析
- 利用词袋模型、TF-IDF、Word2Vec或BERT等方法,计算论文摘要与正文之间的相似度。可以采用余弦相似度或Jaccard相似度等指标。如果摘要与正文内容相关性高,相似度分数会相应增加。
(2)主题模型分析
使用主题模型如Latent Dirichlet Allocation (LDA)或潜在语义分析(LSA),比较摘要中的主题与正文中的主题,以评估摘要是否涵盖了论文的核心主题。。
(3)关键词抽取与比对
使用关键词抽取技术,比较摘要中提取的关键词和正文中的关键词,检查它们的一致性和覆盖度。分析摘要中提取的关键词是否在正文中有对应的论述。
(4)语义分析与信息覆盖度
利用自然语言处理技术,分析摘要中涉及的信息在正文中的覆盖程度,包括实体识别、概念匹配等。分析摘要中涉及的重要信息在正文中的覆盖情况。
2.4 问题四
评价文字流畅性、写作规范和论文逻辑性,涉及到文本通顺、立意分析、篇章结构、论证挖掘等多个维度。传统论文评分技术结合了自然语言处理和机器学习技术进行综合评估,下面是一些技术细节、评价指标及其依据:
(1)文本通顺性评价
使用使用句法分析器,如StanfordNLP、Spacy等,对句子进行语法分析,识别句子中的主语、谓语、宾语等成分,以及句法结构关系。检测句子内部的语法结构是否合理。应用词义消歧、语义角色标注等技术,检测句子之间的逻辑衔接和连贯性;
(2)写作规范性评价:
使用Python的库NLTK或spaCy,来对论文中的图表标注进行文本解析和识别。结合正则表达式和规则匹配,检测图表标题、标签、图表内容等是否符合规范格式。可以使用正则表达式来匹配特定格式的图表标题和标签。
(3)立意分析评价:
应用聚类分析和关键词抽取,分析文本中表达的核心观点和立意。
(4)篇章结构
使用词性标注和文本匹配技术,识别文本中的桥接词或过渡性词语,以评估段落间的连接和衔接情况,来表示篇章之间的逻辑关系。
(5)论证挖掘评价
利用ChatGPT、讯飞星火、文心一言等大模型分析论文中的论点、论据、论证关系,评估其合理性和逻辑性。
3 Python代码实现
3.1 问题一
使用PdfMiner提取PDF文档中的章节和段落信息,并打分
import re
from pdfminer.high_level import extract_text
# 读取PDF文件内容
def extract_pdf_text(pdf_path):
return extract_text(pdf_path)
# 识别标题结构
def recognize_structure(text, titles):
recognized_titles = [title for title in titles if re.search(title, text, re.IGNORECASE)]
return recognized_titles
# 评估结构的逻辑完整性和条理性
def evaluate_structure(recognized_titles, expected_titles):
if recognized_titles == expected_titles:
logic_score = 1
else:
logic_score = round(len(recognized_titles) / len(expected_titles),1)
return logic_score
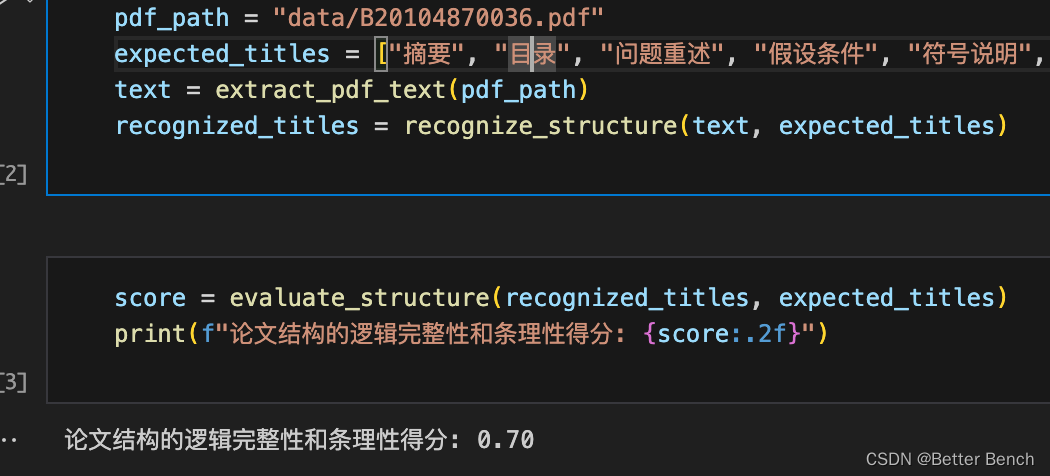
pdf_path = "data/B20104870036.pdf"
expected_titles = ["摘要", "目录", "问题重述", "假设条件", "符号说明", "模型建立", "模型求解", "模型检验", "结果分析", "结论", "参考文献", "附录"]
text = extract_pdf_text(pdf_path)
recognized_titles = recognize_structure(text, expected_titles)
score = evaluate_structure(recognized_titles, expected_titles)
# 0到1之间,如果要十分制,乘以10即可
print(f"论文结构的逻辑完整性和条理性得分: {
score:.2f}")
3.2 问题二
import re
from pdfminer.high_level import extract_text
import spacy
import gensim
import numpy as np
import jieba
from gensim.parsing.preprocessing import STOPWORDS
import os
# 加载中文模块
nlp = spacy.load("zh_core_web_sm")
# 读取PDF文件内容
def extract_pdf_text(pdf_path):
return extract_text(pdf_path)
# 将文本分成段落或句子
def segment_text(text):
...略
return segments
# 从文本中提取赛题相关的关键词
def extract_keywords(segments,stop_keywords):
...略
return keywords
# 从文本中识别与赛题相关的主题或话题
def evaluate_problem_statement(topics, keywords):
# 输出每个主题的关键词
topic_words = []
for topic in topics:
topic_num = topic[0]
topic_keywords = [word[0] for word in topic[1]]
topic_words.extend(topic_keywords)
print(f"主题{
topic_num+1}的关键词:{
topic_keywords}")
topic_coverage = len(set(keywords) & set(topic_words)) / len(keywords)
return round(topic_coverage,2)
problem_pdf_path = "data/2020华为杯B题题目.pdf" # 赛题题目
paper_pdf_path = "data/B20104870036.pdf" # 论文
# 读取文件内容
problem_text = extract_pdf_text(problem_pdf_path)
paper_text = extract_pdf_text(paper_pdf_path)
# 将文本分成段落或句子
problem_segments = segment_text(problem_text)
# 使用哈工大中文停用词库
chinese_stopwords = [line.strip() for line in open('data/hit_stopwords.txt', encoding='utf-8').readlines()]
# 去除中文停用词和符号
filtered_paper_text = [word for word in jieba.cut(paper_text) if word not in chinese_stopwords and word.strip()]
# 从文本中提取赛题相关的关键词
problem_keywords = extract_keywords(problem_segments,chinese_stopwords)
dict_file = 'data/custom_dict.txt'
if not os.path.exists(dict_file):
# 将自定义词典列表写入文件
with open(dict_file, 'w', encoding='utf-8') as f:
for word in problem_keywords:
f.write(word + ' 10 n' + '\n')
# 把题目中的关键词,加入自定义词典
jieba.load_userdict(dict_file)
# 创建并训练LDA主题模型
num_topic = 10
paper_dictionary = gensim.corpora.Dictionary([paper_segment.lower().split() for paper_segment in filtered_paper_text])
paper_bow_corpus = [paper_dictionary.doc2bow(segment.lower().split()) for segment in filtered_paper_text]
lda_model = gensim.models.LdaModel(paper_bow_corpus, id2word=paper_dictionary, num_topics=num_topic, passes=10)
# 获取主题关键词
topics = lda_model.show_topics(num_topics=num_topic, num_words=20, formatted=False)
# 从文本中识别与赛题相关的主题或话题
# 0到1之间,如果要十分制,乘以10即可
problem_statement_score = evaluate_problem_statement(topics, problem_keywords)
print(f"论文相关性得分: {
problem_statement_score}")

3.3 问题三
使用国内GPT的API,kimi是免费且支持200万token的大模型
import requests
import json
import os
# 通过AI API生成文本
def AI_chat(user_message):
MOONSHOT_API_KEY = "自己的API KEY"
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {
MOONSHOT_API_KEY}',
}
data = {
"model": "moonshot-v1-32k",
"messages": [
{
"role": "user", "content": user_message}
],
"temperature": 0.5,
}
response = requests.post('https://api.....', headers=headers, data=json.dumps(data))
response_json = response.json()
assistant_message = response_json['choices'][0]['message']['content']
return assistant_message
读取论文中摘要和正文的内容
from pdfminer.high_level import extract_text
import re
# 读取PDF文件内容
# 使用正则表达式提取摘要部分和正文部分
def extract_abstract_and_body(pdf_path):
full_text = extract_text(pdf_path)
# 去除文本中的空格和空行
full_text = full_text.replace(' ','').replace('\n','')
# 移除掉目录项,假设目录项以数字加页码的形式出现,例如 "1 引言...2"
full_text = re.sub(r'\d+\s+.*\.\.\.\s+\d+','',full_text)
# 修复可能的分页导致关键词被割断的问题
repaired_text = full_text.replace('-\n','').replace('\n',' ')
# 找到‘摘要’和‘关键词’之间的文本
...略
# 找到正文起始关键词后的所有文本作为正文
...略
# 清除摘要与正文之间可能多余的标题等内容
return abstract.strip(),body.strip()
# 计算摘要与正文的相关性和一致性,并进行质量评价打分
def evaluate_summary(summary, content):
# 构建提示词
user_message = f"请计算以下论文摘要与正文的相关性和一致性,并进行质量评价打分(输出1到10分之间),要求只输出最终的评分数字,如9:\n摘要: {
summary}\n正文: {
content}"
# 使用kimi_chat函数获取结果
result = AI_chat(user_message)
# 解析返回的结果以获取分数
try:
number = re.search(r'\d+',result).group(0) # 使用正则表达式提取整数数字
score = int(number) # 将提取的数字转换为整数类型
return score
except ValueError:
return "无法解析分数,请确保返回的内容包含一个整数值。"
paper_file_path = "data/B20100040057.pdf" # 论文
# 读取摘要和正文
summary_paper, content_paper = extract_abstract_and_body(paper_file_path)
# 计算相关性和一致性,并进行质量评价打分
score = evaluate_summary(summary_paper,content_paper)
print(f"论文摘要的质量评价分数是: {
score}")

3.4 问题四
import pdfminer
from pdfminer.high_level import extract_text
import spacy
import re
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from spacy.tokens import Doc
import jieba.analyse
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 载入中文NLP模型
nlp = spacy.load('zh_core_web_sm')
# 使用哈工大中文停用词库
stop_words = [line.strip() for line in open('data/hit_stopwords.txt', encoding='utf-8').readlines()]
# 读取PDF文件函数
def read_pdf(file_path):
text = extract_text(file_path)
# 去除文本中的空格和空行
full_text = text.replace(' ','').replace('\n','')
return full_text
# 评价语法结构
def evaluate_text_flow(text):
...略
# 最后,必须确保分数介于0到10之间
flow_score = min(10, flow_score)
# 标准化分数
if len(sentences) > 1:
norm_score = (flow_score / (len(sentences)-1)) * 10
return norm_score
else:
# 如果只有一句话,则不适用流程评分标准
return 10
# 写作规范性评价函数
def evaluate_writing_standard(text):
...略
return standard_score
# 篇章结构评价函数
def evaluate_structure(text):
...略
# 将分数归一化到0-10分之间
return min((structure_score / len(list(doc.sents))) * 10,10)
# 定义评价论文立意的函数
def evaluate_intention(prob_keywords,paper_keywords):
...略
return score
problem_pdf = "data/2020华为杯B题题目.pdf" # 赛题题目
paper_pdf = "data/B20100040057.pdf" # 论文
# 读取pdf文件
problem_text = read_pdf(problem_pdf)
paper_text = read_pdf(paper_pdf)





4 完整资料
完整代码下载

智能推荐
【史上最易懂】马尔科夫链-蒙特卡洛方法:基于马尔科夫链的采样方法,从概率分布中随机抽取样本,从而得到分布的近似_马尔科夫链期望怎么求-程序员宅基地
文章浏览阅读1.3k次,点赞40次,收藏19次。虽然你不能直接计算每个房间的人数,但通过马尔科夫链的蒙特卡洛方法,你可以从任意状态(房间)开始采样,并最终收敛到目标分布(人数分布)。然后,根据一个规则(假设转移概率是基于房间的人数,人数较多的房间具有较高的转移概率),你随机选择一个相邻的房间作为下一个状态。比如在巨大城堡,里面有很多房间,找到每个房间里的人数分布情况(每个房间被访问的次数),但是你不能一次进入所有的房间并计数。但是,当你重复这个过程很多次时,你会发现你更有可能停留在人数更多的房间,而在人数较少的房间停留的次数较少。_马尔科夫链期望怎么求
linux以root登陆命令,su命令和sudo命令,以及限制root用户登录-程序员宅基地
文章浏览阅读3.9k次。一、su命令su命令用于切换当前用户身份到其他用户身份,变更时须输入所要变更的用户帐号与密码。命令su的格式为:su [-] username1、后面可以跟 ‘-‘ 也可以不跟,普通用户su不加username时就是切换到root用户,当然root用户同样可以su到普通用户。 ‘-‘ 这个字符的作用是,加上后会初始化当前用户的各种环境变量。下面看下加‘-’和不加‘-’的区别:root用户切换到普通..._限制su root登陆
精通VC与Matlab联合编程(六)_精通vc和matlab联合编程 六-程序员宅基地
文章浏览阅读1.2k次。精通VC与Matlab联合编程(六)作者:邓科下载源代码浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程 Matlab C/C++函数库是Matlab扩展功能重要的组成部分,包含了大量的用C/C++语言重新编写的Matlab函数,主要包括初等数学函数、线形代数函数、矩阵操作函数、数值计算函数_精通vc和matlab联合编程 六
Asp.Net MVC2中扩展ModelMetadata的DescriptionAttribute。-程序员宅基地
文章浏览阅读128次。在MVC2中默认并没有实现DescriptionAttribute(虽然可以找到这个属性,通过阅读MVC源码,发现并没有实现方法),这很不方便,特别是我们使用EditorForModel的时候,我们需要对字段进行简要的介绍,下面来扩展这个属性。新建类 DescriptionMetadataProvider然后重写DataAnnotationsModelMetadataPro..._asp.net mvc 模型description
领域模型架构 eShopOnWeb项目分析 上-程序员宅基地
文章浏览阅读1.3k次。一.概述 本篇继续探讨web应用架构,讲基于DDD风格下最初的领域模型架构,不同于DDD风格下CQRS架构,二者架构主要区别是领域层的变化。 架构的演变是从领域模型到C..._eshoponweb
Springboot中使用kafka_springboot kafka-程序员宅基地
文章浏览阅读2.6w次,点赞23次,收藏85次。首先说明,本人之前没用过zookeeper、kafka等,尚硅谷十几个小时的教程实在没有耐心看,现在我也不知道分区、副本之类的概念。用kafka只是听说他比RabbitMQ快,我也是昨天晚上刚使用,下文中若有讲错的地方或者我的理解与它的本质有偏差的地方请包涵。此文背景的环境是windows,linux流程也差不多。 官网下载kafka,选择Binary downloads Apache Kafka 解压在D盘下或者什么地方,注意不要放在桌面等绝对路径太长的地方 打开conf_springboot kafka
随便推点
VS2008+水晶报表 发布后可能无法打印的解决办法_水晶报表 不能打印-程序员宅基地
文章浏览阅读1k次。编好水晶报表代码,用的是ActiveX模式,在本机运行,第一次运行提示安装ActiveX控件,安装后,一切正常,能正常打印,但发布到网站那边运行,可能是一闪而过,连提示安装ActiveX控件也没有,甚至相关的功能图标都不能正常显示,再点"打印图标"也是没反应解决方法是: 1.先下载"PrintControl.cab" http://support.businessobjects.c_水晶报表 不能打印
一. UC/OS-Ⅱ简介_ucos-程序员宅基地
文章浏览阅读1.3k次。绝大部分UC/OS-II的源码是用移植性很强的ANSI C写的。也就是说某产品可以只使用很少几个UC/OS-II调用,而另一个产品则使用了几乎所有UC/OS-II的功能,这样可以减少产品中的UC/OS-II所需的存储器空间(RAM和ROM)。UC/OS-II是为嵌入式应用而设计的,这就意味着,只要用户有固化手段(C编译、连接、下载和固化), UC/OS-II可以嵌入到用户的产品中成为产品的一部分。1998年uC/OS-II,目前的版本uC/OS -II V2.61,2.72。1.UC/OS-Ⅱ简介。_ucos
python自动化运维要学什么,python自动化运维项目_运维学python该学些什么-程序员宅基地
文章浏览阅读614次,点赞22次,收藏11次。大家好,本文将围绕python自动化运维需要掌握的技能展开说明,python自动化运维从入门到精通是一个很多人都想弄明白的事情,想搞清楚python自动化运维快速入门 pdf需要先了解以下几个事情。这篇文章主要介绍了一个有趣的事情,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。_运维学python该学些什么
解决IISASP调用XmlHTTP出现msxml3.dll (0x80070005) 拒绝访问的错误-程序员宅基地
文章浏览阅读524次。2019独角兽企业重金招聘Python工程师标准>>> ..._hotfix for msxml 4.0 service pack 2 - kb832414
python和易语言的脚本哪门更实用?_易语言还是python适合辅助-程序员宅基地
文章浏览阅读546次。python和易语言的脚本哪门更实用?_易语言还是python适合辅助
redis watch使用场景_详解redis中的锁以及使用场景-程序员宅基地
文章浏览阅读134次。详解redis中的锁以及使用场景,指令,事务,分布式,命令,时间详解redis中的锁以及使用场景易采站长站,站长之家为您整理了详解redis中的锁以及使用场景的相关内容。分布式锁什么是分布式锁?分布式锁是控制分布式系统之间同步访问共享资源的一种方式。为什么要使用分布式锁? 为了保证共享资源的数据一致性。什么场景下使用分布式锁? 数据重要且要保证一致性如何实现分布式锁?主要介绍使用redis来实..._redis setnx watch