spark、Scala的安装-程序员宅基地
技术标签: Scala
Spark简介
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
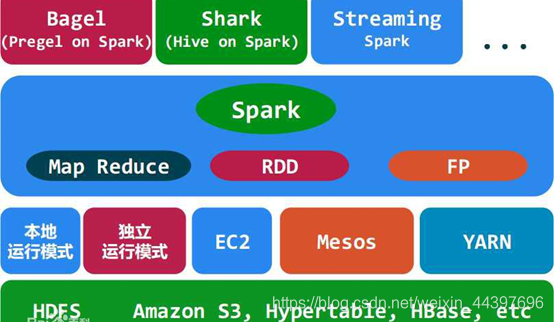
Spark生态圈
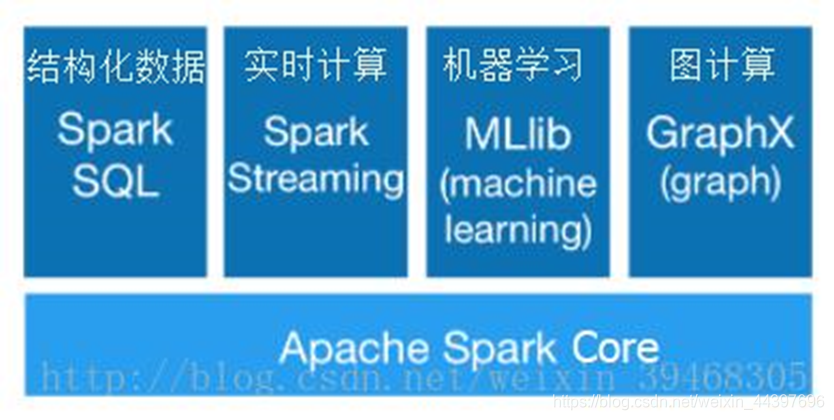
Spark力图整合机器学习(MLib)、图算法(GraphX)、流式计算(Spark Streaming)和数据仓库(Spark SQL)等领域,通过计算引擎Spark,弹性分布式数据集(RDD),架构出一个新的大数据应用平台。
Spark生态圈以HDFS、S3、Techyon为底层存储引擎,以Yarn、Mesos和Standlone作为资源调度引擎;使用Spark,可以实现MapReduce应用;基于Spark,Spark SQL可以实现即席查询,Spark Streaming可以处理实时应用,MLib可以实现机器学习算法,GraphX可以实现图计算,SparkR可以实现复杂数学计算。
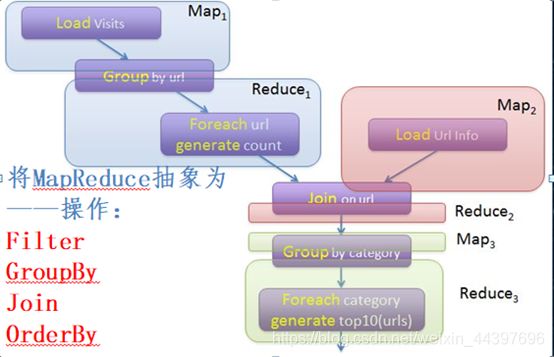
Pig Latin数据流编程语言,将操作组成有向无环图DAG
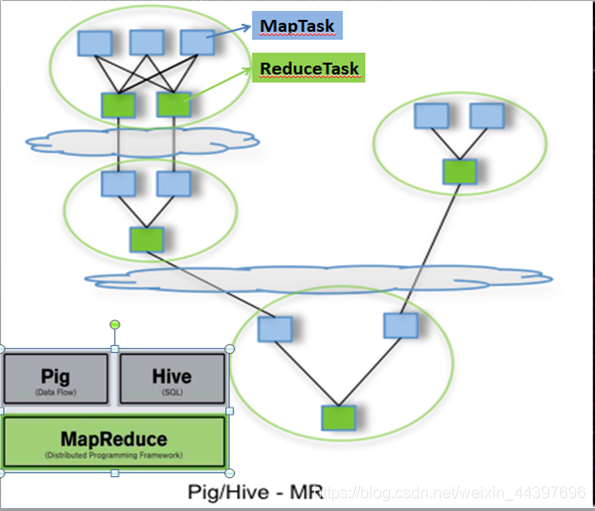
Pig、Hive基于MapReduce
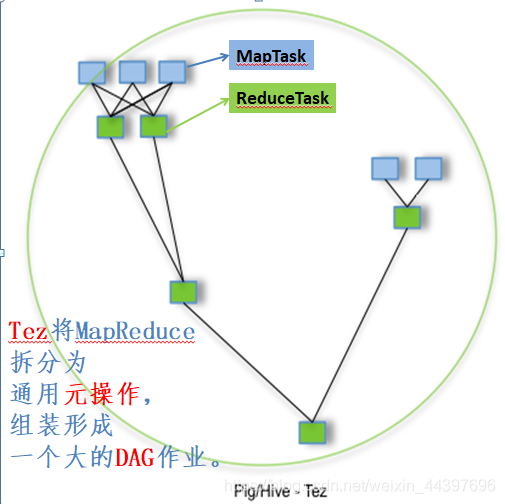
Pig、Hive基于Tez:多个有依赖的作业转换为一个作业,中间节点减少,只需写一次HDFS
spark的优点
Spark的中间数据放到内存中,对于迭代运算效率更高。
Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念。
Spark比Hadoop更通用
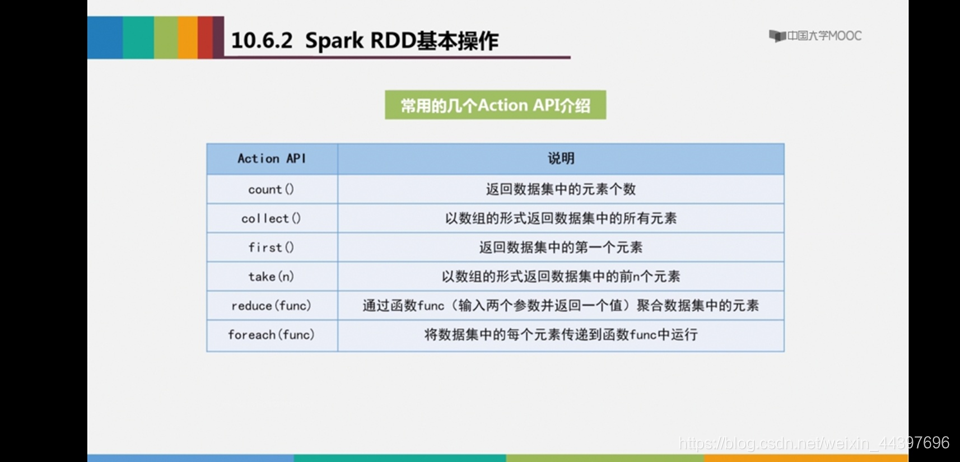
Spark提供的数据集操作类型有很多
①Transformations转换操作:map,filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup,mapValues, sort,partionBy等。
②actions行动操作:Count,collect, reduce, lookup, save等。
一个Spark的“Hello World”程序
读取一个HDFS文件,计算包含字符串“Hello World”行数
val sc= new SparkContext(“spark://localhost:7077”,”Hello World”,
“YOUR_SPARK_HOME”,”YOUR_APP_JAR”)
val fileRDD =sc.textFile(“hdfs://192.168.0.103:9000/examplefile”)
val filterRDD =fileRDD.filter(_.contains(“Hello World”))
filterRDD.cache()
filterRDD.count()
val sc= new SparkContext(“spark://localhost:7077”,”Hello World”,“YOUR_SPARK_HOME”,”YOUR_APP_JAR”) //创建SparkContext对象
在spark程序运行起来后,程序就会创建sparkContext,解析用户的代码,当遇到action算的时候开始执行程序,但是在执行之前还有很多前提工作要在sparkContext中做的。
val fileRDD =sc.textFile(“hdfs://192.168.0.103:9000/examplefile”) //从HDFS文件中读取数据创建一个RDD
RDD是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD提供了一种高度受限的共享内存模型.
val filterRDD =fileRDD.filter(_.contains(“Hello World”)) //对fileRDD进行转换操作得到一个新的RDD,即filterRDD。
filterRDD.cache() //对filterRDD进行持久化
把它保存在内存或磁盘中(这里采用cache接口把数据集保存在内存中),方便后续重复使用,当数据被反复访问时(比如查询一些热点数据,或者运行迭代算法),这是非常有用的,而且通过cache()可以缓存非常大的数据集,支持跨越几十甚至上百个节点。
filterRDD.count() //count()是一个行动操作,用于计算一个RDD集合中包含的元素个数
Spark的编程模型
三种编程语言:Scala、Java、Python
Spark的转换和行动操作:
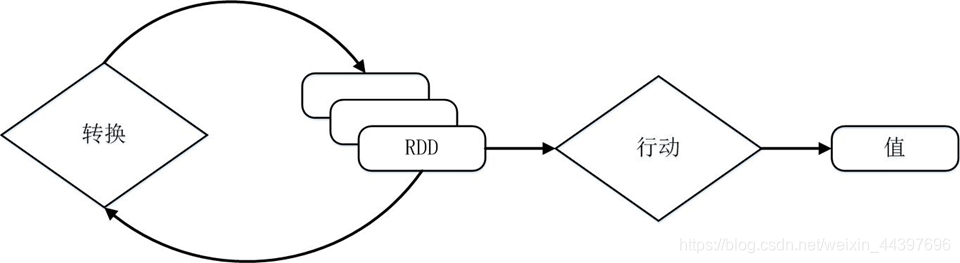
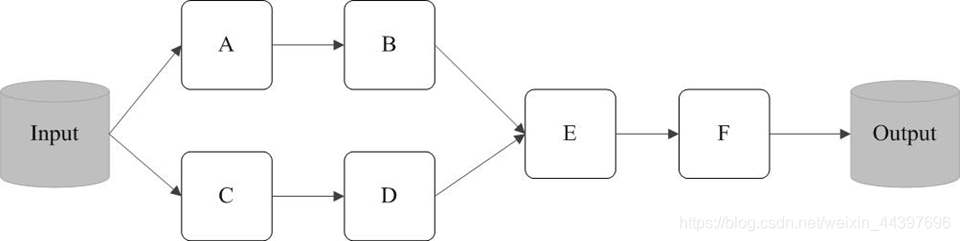
RDD执行过程为DAG
容错性、RDD在内存、数据不需要序列化
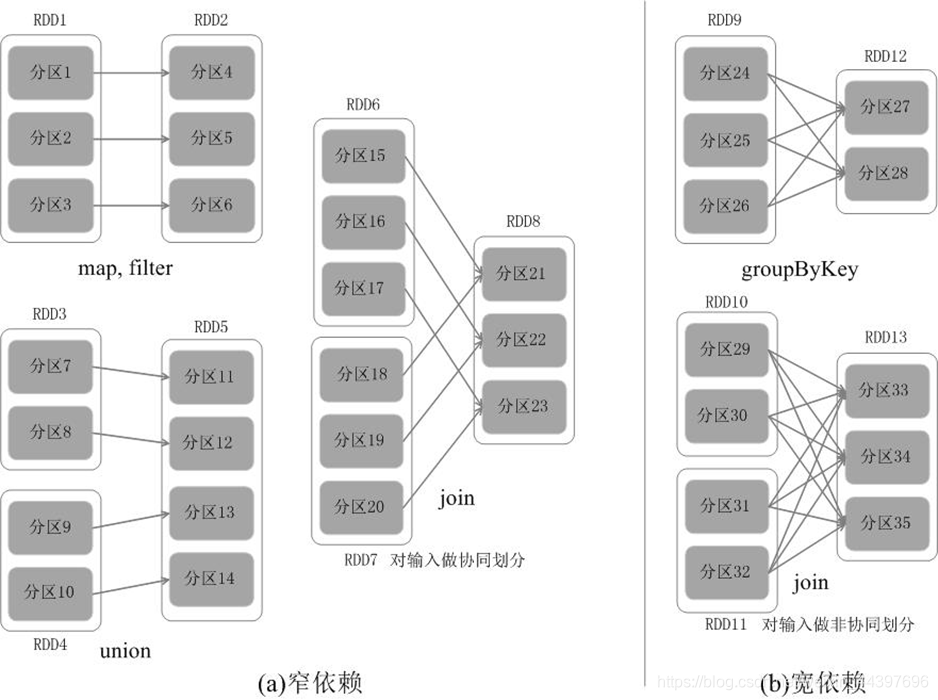
根据RDD分区的依赖关系划分阶段
宽依赖、窄依赖
RDD计算模型
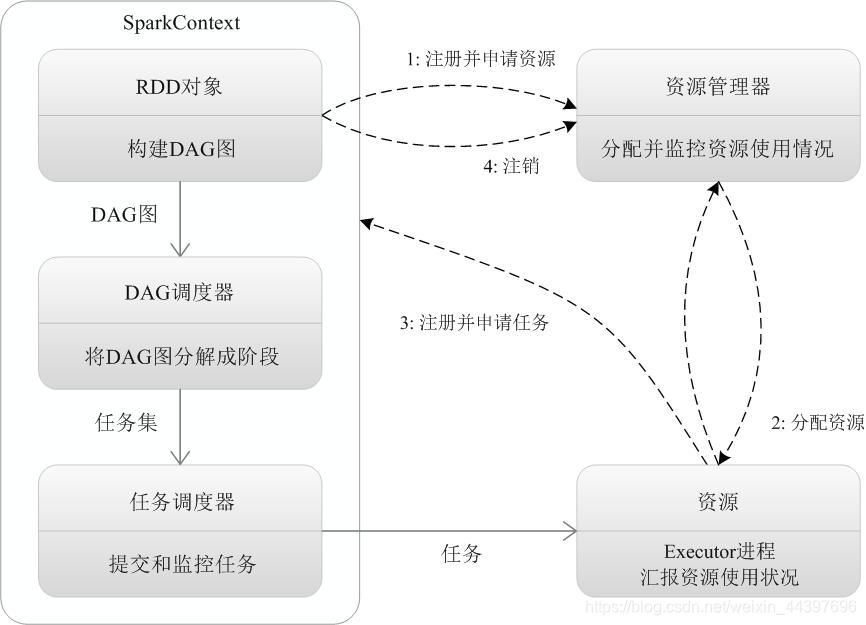
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
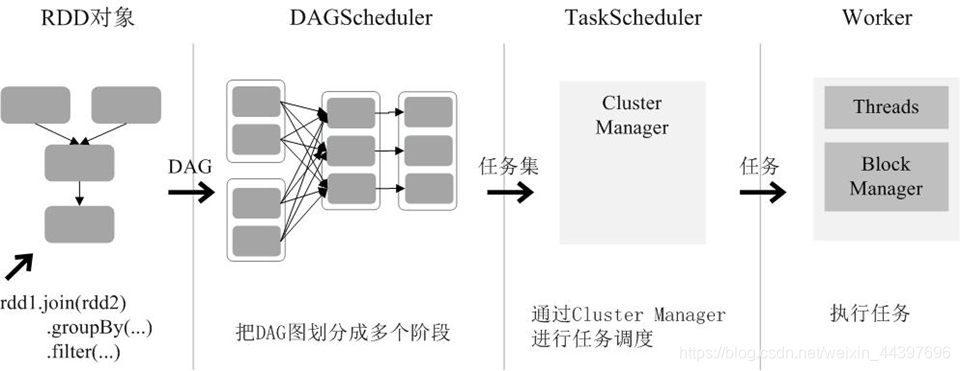
Spark集群架构
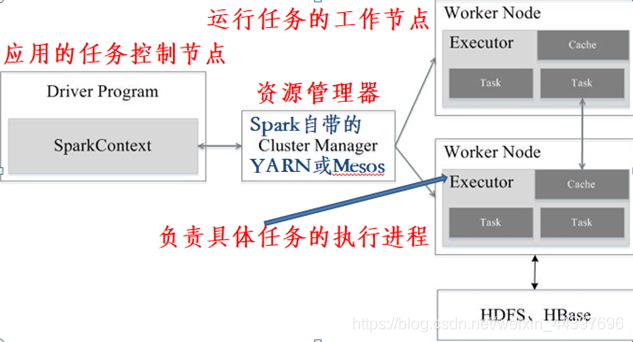
Spark的运行流程
spark三大计算模型
流计算:Spark Streaming、交互式分析:Spark SQL、实时计算
Spark与Scala
一、Spark与Scala版本兼容问题:
Spark运行在Java 8 +,Python 2.7 +/ 3.4 +和R 3.1+上。对于Scala API,Spark 2.4.2使用Scala 2.12。您需要使用兼容的Scala版本(2.12.x)。
请注意,自Spark 2.2.0起,对2.6.5之前的Java 7,Python 2.6和旧Hadoop版本的支持已被删除。自2.3.0起,对Scala 2.10的支持被删除。自Spark 2.4.1起,对Scala 2.11的支持已被弃用,将在Spark 3.0中删除。
https://spark.apache.org/docs/latest/index.html
二、官网下载安装Scala:scala-2.12.8.tgz
https://www.scala-lang.org/download/
tar -zxvf scala-2.12.8.tgz -C /opt/module
mv scala-2.12.8 scala
测试:scala -version
启动:scala
三、官网下载安装Spark:spark-2.4.2-bin-hadoop2.7.tgz
https://www.apache.org/dyn/closer.lua/spark/spark-2.4.2/spark-2.4.2-bin-hadoop2.7.tgz
解压、重命名,启动spark
①先启动hadoop 环境
start-all.sh
②启动spark环境
进入到SPARK_HOME/sbin下运行start-all.sh
/opt/module/spark/sbin/start-all.sh
[注] 如果使用start-all.sh时候会重复启动hadoop配置,需要./在当前工作目录下执行命令
jps 观察进程 多出 worker 和 mater 两个进程。
查看spark的web控制页面:http://bigdata128:8080/
显示spark的端口是7070
③启动Spark Shell
此模式用于interactive programming,先进入bin文件夹后运行:spark-shell
SecureCRT 下 spark-shell 下scala> 命令行无法删除,解决办法:
https://blog.csdn.net/nicolewjt/article/details/87368749
④退出Spark Shell
scala> :quit
四、使用Spark Shell编写代码
读取本地文件

显示第一行内容

读取HDFS文件

对上述hdfs根目录下f1.txt文件进行词频统计
flatMap转换操作、 map转换操作、reduceByKey转换操作

查看结果

五、使用Scala编写Spark程序
val spark =new SparkContext(master, appName, [sparkHome], [jars])
val file =spark.textFile("hdfs://...")
val counts =file.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_+ _)
counts.saveAsTextFile("hdfs://...")
file是根据HDFS上的文件创建的RDD,flatMap、map、reduceByKe都创建出一个新的RDD,一个简短的程序就能够执行很多个转换和动作
总 结
近几年来,大数据机器学习和数据挖掘的并行化算法研究成为大数据领域一个较为重要的研究热点。早几年国内外研究者和业界比较关注的是在 Hadoop 平台上的并行化算法设计。然而, HadoopMapReduce 平台由于网络和磁盘读写开销大,难以高效地实现需要大量迭代计算的机器学习并行化算法。随着 UC Berkeley AMPLab 推出的新一代大数据平台 Spark 系统的出现和逐步发展成熟,近年来国内外开始关注在 Spark 平台上如何实现各种机器学习和数据挖掘并行化算法设计。为了方便一般应用领域的数据分析人员使用所熟悉的 R 语言在 Spark 平台上完成数据分析,Spark 提供了一个称为 SparkR 的编程接口,使得一般应用领域的数据分析人员可以在 R 语言的环境里方便地使用 Spark 的并行化编程接口和强大计算能力。
智能推荐
00000000000000000000000-程序员宅基地
文章浏览阅读819次。111事实生生死死生生死死生生死死_00000000000000000000000
Apollo自动驾驶系统概述(文末参与活动赠送百度周边)_apollo智能驾驶介绍-程序员宅基地
文章浏览阅读560次,点赞5次,收藏2次。参与活动领取奖励_apollo智能驾驶介绍
机器学习实践系列之:OpenCV光流目标跟踪_opencv光流法目标追踪-程序员宅基地
文章浏览阅读136次。我们通过计算连续帧之间的像素变化来估计物体的运动。通过使用OpenCV的光流算法,我们能够实时地跟踪视频序列中的目标。这是一个基本的目标跟踪示例,你可以根据自己的需求进行修改后的标题:机器学习实践系列之:OpenCV光流目标跟踪。在机器学习和计算机视觉的领域中,目标跟踪是一个重要的任务,它涉及到在视频序列中准确地追踪目标的位置和运动。光流是一种常用的技术,它可以通过分析连续帧之间的像素变化来估计物体的运动。我们将使用Python编程语言来编写代码,并使用OpenCV的光流算法来计算物体的运动。_opencv光流法目标追踪
MapReduce程序开发中的FileInputFormat与TextInputFormat_fileinputformat和text-程序员宅基地
文章浏览阅读7k次,点赞7次,收藏11次。2016年4月3日20:17:44 MapReduce程序开发中的FileInputFormat与TextInputFormat 在MapReduce程序的开发过程中,往往需要用到FileInputFormat与TextInputFormat,但是这两个类究竟是用来做什么的,在源代码的追踪过程中,我们会发现TextInputFormat这个类继承自FileIn_fileinputformat和text
Windows远程执行命令-程序员宅基地
文章浏览阅读9.9k次,点赞2次,收藏21次。环境:Win10、Win7虚拟机Windows远程命令执行1、psexec.exe远程执行命令psexec \\192.168.30.128 -u Administrator -p 123456789 cmd.exe这里一开始登陆的是另一个管理员账号,但是一直被拒绝访问,后来把Administrator账号取消隐藏,一下就连接上。之后看到一篇文章也有一样的情况,只有Admin..._windows远程执行命令
Android进程保活黑科技实现原理解密及方法,,2024最新Android面试笔试题目分享-程序员宅基地
文章浏览阅读336次,点赞6次,收藏7次。Android架构学习进阶是一条漫长而艰苦的道路,不能靠一时激情,更不是熬几天几夜就能学好的,必须养成平时努力学习的习惯。所以:贵在坚持!上面分享的字节跳动公司2021年的面试真题解析大全,笔者还把一线互联网企业主流面试技术要点整理成了视频和PDF(实际上比预期多花了不少精力),包含知识脉络 + 诸多细节。【Android高级架构视频学习资源】Android部分精讲视频领取学习后更加是如虎添翼!进军BATJ大厂等(备战)!
随便推点
CentOS系统时区修改(Linux时间同步)解决系统时间与本地时间不同步_centos时间不同步-程序员宅基地
文章浏览阅读937次。CentOS系统时区修改(Linux时间同步)解决系统时间与本地时间不同步。_centos时间不同步
iview导航菜单updateOpened和updateActiveName的使用-程序员宅基地
文章浏览阅读1.7k次。先看官方文档: iview导航菜单这里主要遇到的问题有两个:1. 点击回到首页(B按钮)时需要取消选中当前选中的菜单项(全部不选中),这里用到的是updateActiveName方法2. 点击收起菜单(A按钮)时,关闭所有展开的子菜单(只展示一级菜单),这里要用到的是updateOpened方法截图如下:先看下这两个方法的文档说明,直接看不是很清楚到..._updateactivename
论文解析:区域和强度可控的GAN用于工业图像缺陷生成,数据扩充,分割_区域和强度可控的gan用于工业图像缺陷生成论文下载-程序员宅基地
文章浏览阅读2.8k次,点赞4次,收藏36次。前言论文地址:IEEE TII Region- and Strength-Controllable GAN for Defect Generation and Segmentation in Industrial Images摘要计算机视觉的深度学习 (DL) 基于海量、多样化和注释良好的训练集取得了显着的成果。 然而,很难收集涵盖所有可能特征的缺陷数据集,尤其是对于小而弱的缺陷。 因此,提出了一种缺陷区域和强度可控的缺陷图像生成方法。 被视为使用生成对抗网络 (GAN) 的图像修复,生成的缺陷区域_区域和强度可控的gan用于工业图像缺陷生成论文下载
【附源码】计算机毕业设计SSM享约拍平台_约拍小程序源码-程序员宅基地
文章浏览阅读496次。项目运行环境配置:(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。2.IDE环境:IDEA,Eclipse,Myeclipse都可以。推荐IDEA;3.tomcat环境:Tomcat 7.x,8.x,9.x版本均可4._约拍小程序源码
pytorch Parameter 设置 可学习参数_pytorch学习一个参数-程序员宅基地
文章浏览阅读1.7w次,点赞8次,收藏51次。一般来说,pytorch 的Parameter是一个tensor,但是跟通常意义上的tensor有些不一样1)通常意义上的tensor 仅仅是数据2)而Parameter所对应的tensor 除了包含数据之外,还包含一个属性:requires_grad(=True/False)在Parameter所对应的tensor中获取纯数据,可以通过以下操作:param_d..._pytorch学习一个参数
ListView回收机制相关分析_listview 被回收了-程序员宅基地
文章浏览阅读508次。原文地址:http://www.cnblogs.com/qiengo/p/3628235.htmlListView结构关系首先理清listview的层级关系,使用Google Online Draw 画出继承关系图如下:图中单独画出Scrollview是为了说明该ViewGroup并没有自带回收机制,如果要是Scrollview显示大_listview 被回收了