基于rk3399pro的人工智能模型落地与服务器部署_3399pro 模型-程序员宅基地
技术标签: python 笔记 机器学习 深度学习 人工智能
大致流程:
数据获取–>模型搭建–>CPU训练模型–>模型转换–>嵌入式部署–>完成落地
硬件需求:
- 瑞芯微嵌入式开发板rk3399pro(搭载双核Cortex-A72及四核Cortex-A53组合架构处理器,四核GPU一块,以及最重要的NPU神经计算单元:内置算力3.0T)
- 键盘、鼠标、电源
- USB摄像头一块
- 有条件可以搭载RK1808算力棒
系统需求
- Python3.6以上版本
- 上位机搭建rknn.tooklit环境(用于模型转换)
- 上位机可搭建rknn.api环境(用于仿真嵌入式NPU)
- Tensorflow框架等Python环境
- Linux开发环境:(我使用的是Ubuntu系统,方便)
- 开发板搭建rknn.api环境以及npu驱动
为什么不采用大型服务器部署?:
个人理解:
- 小巧且具系统性能: 这块板子刚到手时就觉得其小巧,不够巴掌大,却如麻雀般内置了五脏六腑,还内置工智能芯片,rk3399pro与寻常电脑无异,可以烧写Linux系统,这就甩开了传统单片机、DSP、树莓派好几个档次。
- 功耗低、运算快: 我尝试过整天整天的运行程序都不发热,说明可以很好的适应产品环境 ,便于部署; 另外,内置NPU神经计算单元是电脑无可比拟的,该单元为神经网络计算而生,相比CPU、GPU运算速度、功耗、承受时长都远远超越。
- 丰富的接口: 具有单片机、DSP一样的管脚以及模拟量输出接口,可以直接完成外接控制器的功能实现。假如你让一台电脑去控制一个开关,一个电机,不可能吧?
[点击进入B站大佬实现导盲小车控制]
模型转换
为什么你训练好的Python模型要转换呢,因为NPU采用指定的rknn模型,因此所有模型都需要转化为rknn模型才能完成部署。
该板子最新SDK已经能够支持tensoflow2、tensoflow lite 、Paddle、caffe、pytorch、Darknet、ONNX等模型,我目前是使用Python语言在tensorflow框架下学习,后续还是学一下百度飞桨Paddle,毕竟支持国产~

首先将写好的tensorflow模型转化为RKNN,具体转化代码如下:
from rknn.api import RKNN
INPUT_SIZE = 64
if __name__ == '__main__':
# 创建RKNN执行对象
rknn = RKNN()
# 配置模型输入,用于NPU对数据输入的预处理
# channel_mean_value='0 0 0 255',那么模型推理时,将会对RGB数据做如下转换
# (R - 0)/255, (G - 0)/255, (B - 0)/255。推理时,RKNN模型会自动做均值和归一化处理
# reorder_channel=’0 1 2’用于指定是否调整图像通道顺序,设置成0 1 2即按输入的图像通道顺序不做调整
# reorder_channel=’2 1 0’表示交换0和2通道,如果输入是RGB,将会被调整为BGR。如果是BGR将会被调整为RGB
#图像通道顺序不做调整
rknn.config(channel_mean_value='0 0 0 255', reorder_channel='0 1 2')
# 加载TensorFlow模型
# tf_pb='digital_gesture.pb'指定待转换的TensorFlow模型
# inputs指定模型中的输入节点
# outputs指定模型中输出节点
# input_size_list指定模型输入的大小
print('--> Loading model')
rknn.load_tensorflow(tf_pb='digital_gesture.pb',
inputs=['input_x'],
outputs=['probability'],
input_size_list=[[INPUT_SIZE, INPUT_SIZE, 3]])
print('done')
# 创建解析pb模型
# do_quantization=False指定不进行量化
# 量化会减小模型的体积和提升运算速度,但是会有精度的丢失
print('--> Building model')
rknn.build(do_quantization=False)
print('done')
# 导出保存rknn模型文件
rknn.export_rknn('./digital_gesture.rknn')
# Release RKNN Context
rknn.release()
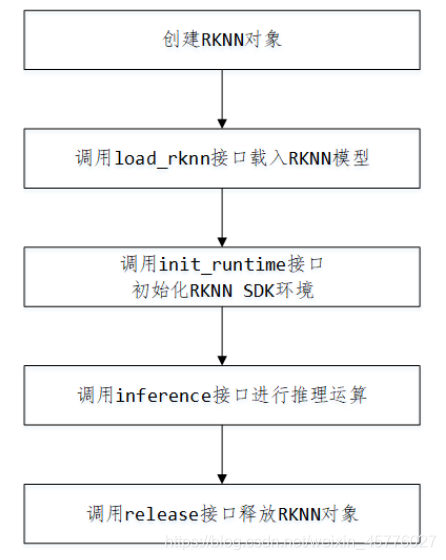
模型推理与部署
模型转换完成后,通过ssh将模型传输至开发板服务器,如下:
sudo su
scp -r model.rknn test.py toybrick@172.22.225.225:/home/test/
ssh toybrick@172.22.225.225
cd /home/test/
python3 test.py
API具体流程如下:
import numpy as np
from PIL import Image
from rknn.api import RKNN
# 解析模型的输出,获得概率最大的手势和对应的概率
def get_predict(probability):
data = probability[0][0]
data = data.tolist()
max_prob = max(data)
return data.index(max_prob), max_prob;
def load_model():
# 创建RKNN对象
rknn = RKNN()
# 载入RKNN模型
print('-->loading model')
rknn.load_rknn('./digital_gesture.rknn')
print('loading model done')
# 初始化RKNN运行环境
print('--> Init runtime environment')
ret = rknn.init_runtime(target='rk3399pro')
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
return rknn
def predict(rknn):
im = Image.open("../picture/6_7.jpg") # 加载图片
im = im.resize((64, 64),Image.ANTIALIAS) # 图像缩放到64x64
mat = np.asarray(im.convert('RGB')) # 转换成RGB格式
outputs = rknn.inference(inputs=[mat]) # 运行推理,得到推理结果
pred, prob = get_predict(outputs) # 将推理结果转化为可视信息
print(prob)
print(pred)
if __name__=="__main__":
rknn = load_model()
predict(rknn)
rknn.release()
采用Demo验证模型效果:
手语数字识别demo效果如下:
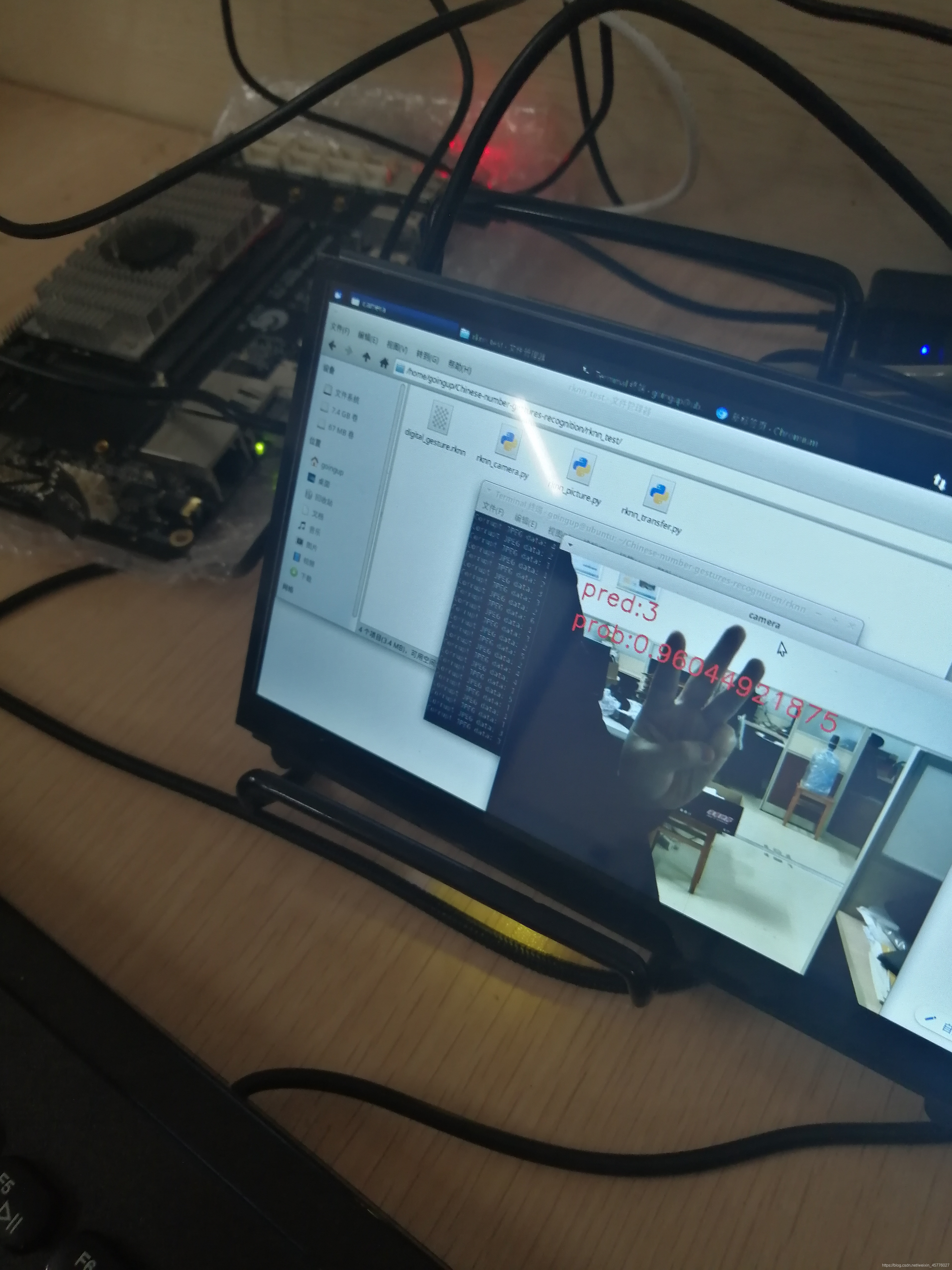
Demo资源如下:
https://download.csdn.net/download/weixin_45776027/13454590
智能推荐
kmeans_kmeans算法相关性分析-程序员宅基地
文章浏览阅读936次。1 kmeansK-means聚类算法也称k均值聚类算法,是集简单和经典于一身的基于距离的聚类算法。它采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为类簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。2.算法核心思想K-means聚类算法是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本_kmeans算法相关性分析
基于springboot的自习室管理系统计算机毕业设计_基于springboot的共享自习室管理系统参考文献-程序员宅基地
文章浏览阅读466次,点赞8次,收藏12次。以上是基于Spring Boot的自习室管理系统的主要功能,通过这些功能可以实现自习室座位的管理、课程的管理、学员信息的管理和行为管理等功能,为自习室提供一个高效、便捷、智能的解决方案。登录后,系统将根据用户的角色显示相应的功能菜单。通过以上各个功能模块的实现,基于Spring Boot的自习室管理系统将提供一套完善的解决方案,帮助自习室提高工作效率和服务质量,为学员提供更加便捷、舒适的学习环境。通过生成相应的报表,管理员可以更好地了解自习室的使用状况和学员的学习情况,从而做出相应的决策和管理调整。_基于springboot的共享自习室管理系统参考文献
Pytroch同一个优化器优化多个模型的参数并且保存优化后的参数_pytorch加载多个模型-程序员宅基地
文章浏览阅读4.5k次,点赞7次,收藏26次。在进行深度学习过程中会遇到几个模型进行串联,这几个模型需要使用同一个优化器,但每个模型的学习率或者动量等其他参数不一样这种情况。一种解决方法是新建一个模型将这几个模型进行串联,另一种解决方法便是往优化器里面传入这几个模型的参数。..._pytorch加载多个模型
计算机软考中级合格标准,中级软考多少分及格-程序员宅基地
文章浏览阅读1.4k次。原标题:中级软考多少分及格盛泰鼎盛 对于第一次报名软考的朋友,可能对于考试合格分数线不太了解,软考分为初、中、高三个级别,那么软考中级多少分及格呢?软考中级合格标准根据往年的软考合格分数线来看,各级别的合格标准基本上统一的。2019年上半年计算机技术与软件专业技术资格(水平)考试各级别各专业各科目合格标准均为45分(总分75分)。而2016下半年计算机技术与软件专业技术资格(水平)考试除了信息系统..._计算机程序设计员中级考试内容及合格标准
爬虫相关-程序员宅基地
文章浏览阅读50次。2019独角兽企业重金招聘Python工程师标准>>> ..._爬虫考虑安全法律因素
ASP.NET Identity 的“多重”身份验证-程序员宅基地
文章浏览阅读263次。本章主要内容有: ● 实现基于微软账户的第三方身份验证 ● 实现双因子身份验证 ● 验证码机制实现基于微软账户的第三方身份验证 在微软提供的ASP.NET MVC模板代码中,默认添加了微软、Google、twitter以及Facebook的账户登录代码(虽然被注释了),另外针对国内的一些社交账户提供了相应的组件,所有组件都可以通过Nuget包管理器安装: 从..._identity 二次登录
随便推点
C++ 敏感词屏蔽-程序员宅基地
文章浏览阅读350次。首先要解决的问题是敏感词的存储形式,这就涉及数据结构,先想想搜索屏蔽要怎么处理,比如我有一个content,我就遍历它每个字符,先看与词典中所有词第一个字符相同的,再看第二个,再看第三个.等等。那么,很明显,这就需要一种以层来存储的数据结构--树来存储敏感词汇。我首先设计了一个Node,它要存储同一级的node指针,下一级的node指针,标识词的结束,数据。最开始本来只想到用树的结构,最后发现, ...
一种隐私保护的BP神经网络的设计-程序员宅基地
文章浏览阅读167次,点赞3次,收藏7次。1. 背景介绍1.1 隐私保护的重要性在当今的数字时代,个人隐私保护已经成为一个越来越受关注的问题。随着大数据和人工智能技术的快速发展,海量的个人数据被收集和利用,这给个人隐私带来了巨大的风险。如何在利用数据的同时保护个人隐私,已经成为了一个亟待解决的挑战。
Java常用异常包_object常用方法,java常见包;常见异常-程序员宅基地
文章浏览阅读177次。1.clone方法保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。2.getClass方法final方法,获得运行时类型。3.toString方法该方法用得比较多,一般子类都有覆盖。4.finalize方法该方法用于释放资源。因为无法确定该方法什么时候被调用,很少使用。5.equals方法该方法是非常重..._一般情况下,异常类存放在什么包中
队列的定义_队列又可以简称为-程序员宅基地
文章浏览阅读1.1k次。队列的定义队列简称为“对”,英文名为“Queue”。队列和堆栈一样都是特殊的线性表。和堆栈不一样的是,队列这种线性表的特殊是它限定只能在表的一端作插入运算,然后只能在表的另一端作删除运算,作插入元素的这一端为“队首”,作删除运算的这一端称为“队尾”。队列的这一特征我们又可以称它为“先进先出”。队列的这个“先进先出”就如同我们平时排队一样,讲究一个先来后到,先来的排在前面,后到的排在后面,排前面的先走,排后面的后走。队列有两种存储结构,一种是顺序排列,另一种是链式排列。如下面图的采用顺序存储结构_队列又可以简称为
数据驱动的产品研发:如何利用数据驱动提高产品安全性-程序员宅基地
文章浏览阅读867次,点赞11次,收藏20次。1.背景介绍在当今的数字时代,数据已经成为企业和组织中最宝贵的资产之一。随着数据的增长和复杂性,数据驱动的决策变得越来越重要。数据驱动的产品研发是一种新兴的方法,它利用数据来优化产品的设计、开发和运营。这种方法可以帮助企业更有效地利用数据,提高产品的安全性和质量。在这篇文章中,我们将探讨数据驱动的产品研发的核心概念、算法原理、实例和未来发展趋势。我们将涉及到以下几个方面:背景介绍核...
基础类的DSP/BIOS API调用_clk_gethtime 返回值-程序员宅基地
文章浏览阅读1.3k次。转载自:http://blog.sina.com.cn/s/blog_48b82df90100bpfj.html基础类的DSP/BIOS API调用一、时钟管理CLK(1)Uns ncounts = CLK_countspms(void) 返回每毫秒的定时器高分辨率时钟的计数值(2)LgUns currtime = CLK_gethtime(void) _clk_gethtime 返回值