在Java中操作Redis-程序员宅基地
Redis中如何的去存放一个Java对象?
- 直接存放Json类型即可,因为我们Json类型最终就是一个String类型。
- 直接存二进制。。。。
在Redis中存放对象可以使用JSON和二进制有哪些区别吗?
- 二进制它本质上来说也是一个String类型的,只不过它转换成了0101,但是0101它也可以转换成String类型。
- 你如果存Java语言的二进制对象那你只能在Java里面用,不能跨平台,因此对于需要跨语言频繁查询的对象,建议使用JSON格式;
- 对于不需要跨语言频繁查看的对象,直接在Redis当中存放二进制对象即可。
Redis的Java客户端
Redis的常用命令是我们操作Redis的基础,那么我们在Java程序当中如何来操作Redis呢?
- 要想基于Java语言来操作Redis数据库,这就需要使用到Redis的Java客户端,就如同我们使用JDBC操作MySQL数据库一样。
Redis的Java客户端很多,常用的几种:
- Jedis
- Lettuce
- Spring Data Redis
像Jedis和Lettuce其实相对来说是比较底层的或者说比较原始的方式来操作,而Spring Data Redis它是Spirng家族的一个框架,对Redis底层的这两个开发包进行了高度的封装,在Spring项目当中,可以使用Spring Data Redis来简化操作。
Spring对Redis客户端进行了整合,提供了Spring Data Redis,在Spring Boot项目当中还提供了对应的 Starter,即spring-boot-starter-data-redis。
Spring Data框架:
- Spring Data框架它里面就封装了操作各种各样数据库的技术!

Spring Data Redis环境准备及介绍
网址:https://spring.io/projects/spring-data-redis
介绍
- Spring Data Redis是Spring的一部分,提供了在Spring应用中通过简单的配置就可以访问Redis服务,对Redis底层开发包进行了高度封装,在Spring项目中,可以使用Spring Data Redis来简化Redis操作。
Spring Data Redis的使用方式:Spring Boot整合Redis
操作步骤:
- 创建SpringBoot工程,勾选起步依赖:Lombok + Spring Web(Web开发的起步依赖) + Spring Data Redis(Acess+Driver) => 在NoSQL里面勾选
- 在application.yml中配置Redis的连接信息
- 在单元测试中,直接注入RedisTemplate对象
- 通过RedisTemplate对象操作Redis
- 因为在Spring Data Redis当中,它就给我们提供了一个操作Redis的一个模版对象:RedisTemplate,RedisTemplate为执行各种Redis操作、异常转换和序列化支持提供了高级抽象!Template - 模版
1. Spring Boot提供了对应的Starter,Maven坐标:引入spring-boot-starter-data-redis依赖
<!-- Redis的起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2. 在application.yml中配置Redis的连接信息:配置Redis数据源
# 配置Redis的连接信息
spring:
data:
redis:
host: 127.0.0.1
port: 6379
password: 123456
database: 0- database:指定使用Redis的哪个数据库,Redis服务启动后默认有16个数据库,编号分别是从0到15,可以通过修改Redis的配置文件来指定数据库的数量。
lettuce是Java用来操作Redis的一个Jar包!
 3. 在单元测试类当中注入RedisTemplate
3. 在单元测试类当中注入RedisTemplate
为什么可以直接注入呢?
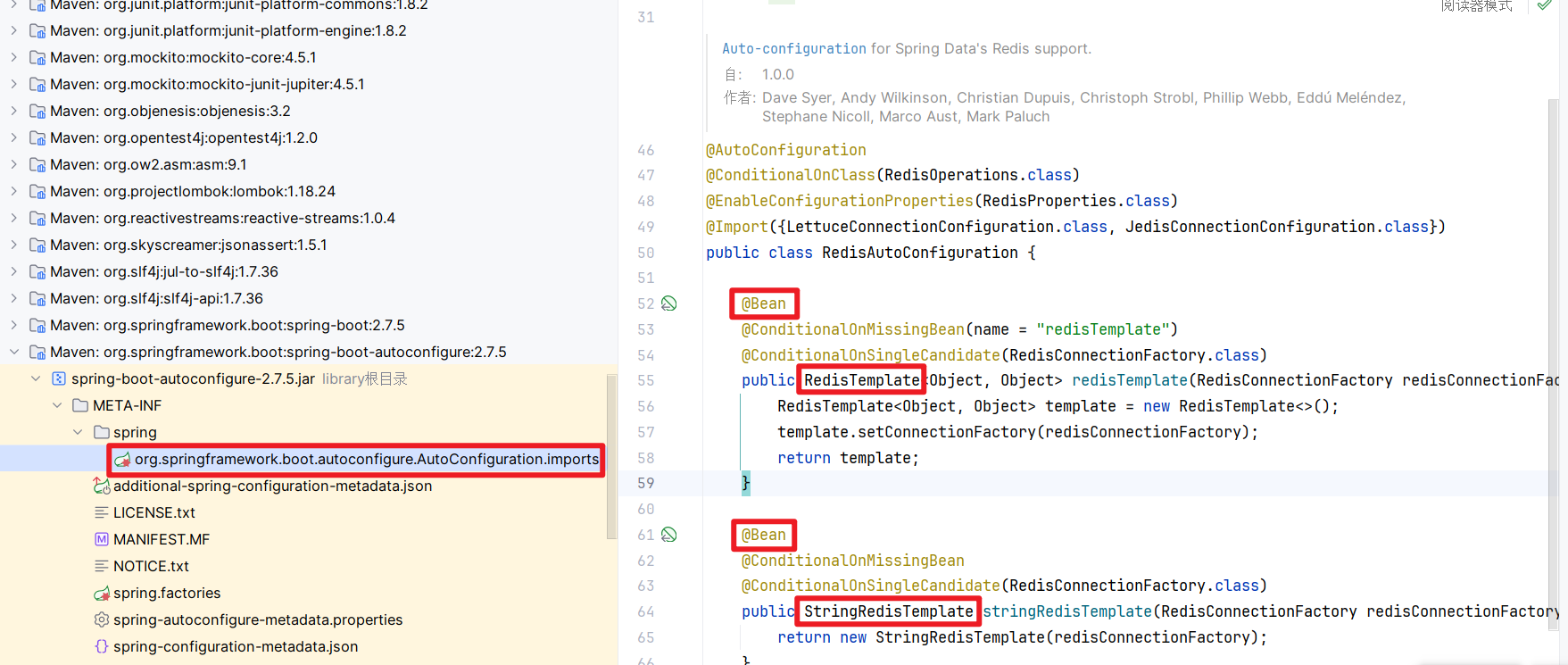
- 因为引入了Redis的起步依赖,所以Spring Boot框架会自动装配RedisTemplate对象!
- RedisAutoConfiguration:RedisTemplate的自动配置类 => SpringBoot自动装配的原理
- 底层还会再声明一个Bean:StringRedisTemplate,它继承了RedisTemplate,并且限制了泛型为<String,String>!
Spring Data Redis中提供了一个高度封装的类:RedisTemplate,RedisTemplate针对大量相关的API进行了归类封装,将同一数据类型的操作封装为对应的Operation接口,具体分类如下:
-
ValueOperations:String数据操作
-
SetOperations:Set类型数据操作
-
ZSetOperations:ZSet类型数据操作
-
HashOperations:Hash类型的数据操作
-
ListOperations:List类型的数据操作

package com.gch;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import java.util.concurrent.TimeUnit;
@SpringBootTest
class SpringDataRedisQuickStartApplicationTests {
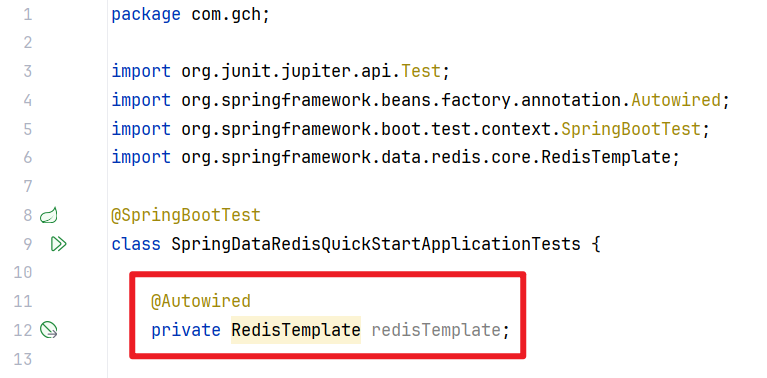
// 注入RedisTemplate对象
@Autowired
private RedisTemplate redisTemplate;
/**
* 往Redis当中写入String类型的数据并设置过期时间
* @param key
* @param value
* @param timeout Key的过期时间
* @return 返回写入的Value
*/
public Object setString(String key, Object value, Long timeout) {
// 往Redis当中写入String类型的数据
redisTemplate.opsForValue().set(key, value);
// 如果时限不为null
if (timeout != null) {
/**
* 则对该Key设置有效期 / 过期时间
* 补充:在Redis里面默认是会开启这个持久化机制的,相当于每个数据都会持久化到硬盘里面去的
* 每次把Redis当成数据库用:对Key不设置有效期,每次查询都会把它放在Redis里面(内存)
* 如果对Key不设置有效期,它就会一直存储在内存里面,而内存又是非常有限的,最终有一天会把内存撑爆
* 直接就导致Redis服务崩了,所以,注意事项:对我们的Redis的Key一定要去设置一个有效期
*/
redisTemplate.expire(key, timeout, TimeUnit.SECONDS);
}
// 获取写入的Value并返回
return redisTemplate.opsForValue().get(key);
}
@Test
public void testRedis() {
// 查找返回所有的Key,返回值是一个Set集合
System.out.println(redisTemplate.keys("*"));
// 往Redis当中写入String类型的数据
System.out.println("name = " + setString("name", "Redis", 1000L));
}
}
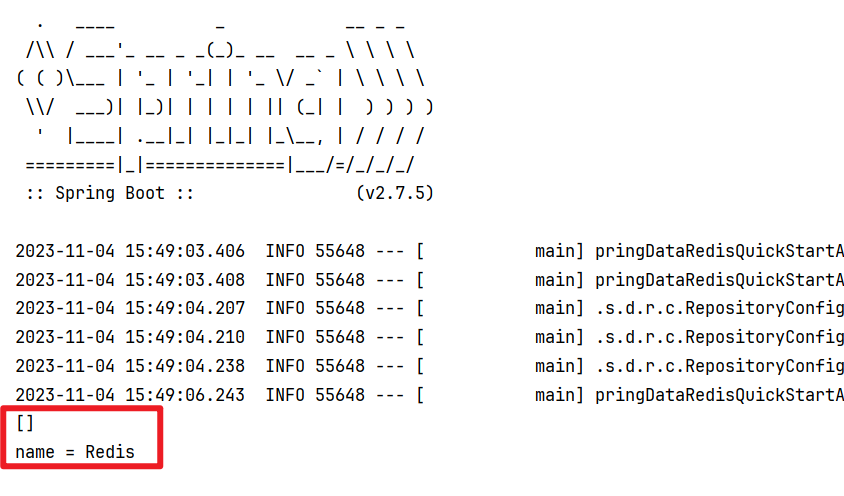
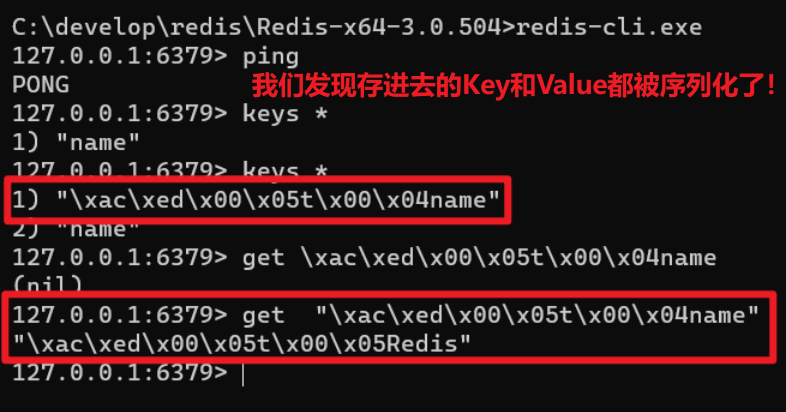
- 我们会发现我们存到Redis中的数据和原始数据有差别,这是为什么呢?
我们来看以下RedisTemplate的源码:


- 通过上面源码我们发现,Spring Boot框架会自动装配RedisTemplate对象,但是默认的Key和Value的序列化器为JdkSerializationRedisSerializer,默认是采用JDK序列化器,虽然说RedisTemplate可以接收任意Object作为值写入到Redis,但是写入前会把Object序列化为字节形式,从而导致我们存到Redis中的数据和原始数据有差别,因为我们要进行设置,我们可以自己定义声明了一个名为redisTemplate的Bean,自己来手动定义序列化方式,从而让源码中的RedisTemplate不声明,以此来覆盖掉源码当中的Bean。
JDK序列化器的缺点:
- 可读性差
- 内存占用较大,但是JDK的序列化方式效率要高一些
SpringDataRedis - 序列化方式配置
package com.gch.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
/**
* 声明当前类是一个配置类
* @Configuration里面封装了@Component,@Service里面封装的也是@Component
*/
@Slf4j
@Configuration
public class RedisConfig {
/**
* 自定义RedisTemplate
* @param redisConnectionFactory
* @return
*/
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
log.info("开始创建Redis模板对象....");
RedisTemplate<Object, Object> template = new RedisTemplate<>();
// 设置redis的连接工厂对象
template.setConnectionFactory(redisConnectionFactory);
/**
* 设置redis key的序列化器
* 指定大Key以及Hash中的小Key的序列化方式
* 建议只去设置Key的序列化范式,因为Value的形式多种多样,因为不同类型的数据它的序列化方式是不一样的
* 等价于template.setKeySerializer(RedisSerializer.string()); => 按照字符串的方式来序列化
*/
template.setKeySerializer(new StringRedisSerializer()); // 设置Key的序列化方式
template.setHashKeySerializer(new StringRedisSerializer()); // 设置Hash Key的序列化方式
return template;
}
}
 操作常见类型数据
操作常见类型数据
1. 操作String字符串类型数据
/**
* 操作String字符串类型的数据
*/
@Test
void testString() {
// 存数据,并设置过期时间
redisTemplate.opsForValue().set("name","Jerry",300L,TimeUnit.SECONDS);
// 取数据,并打印输出
Object name = redisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
// 当该数据不存在时才写入/存数据(setnx),Absent:不存在,该方法返回值类型为Boolean,返回true代表执行成功(成功写入)
Boolean result = redisTemplate.opsForValue().setIfAbsent("count","528",528L,TimeUnit.SECONDS);
System.out.println(result == true ? "写入成功,count = " + redisTemplate.opsForValue().get("count") : "该数据存在,无法写入");
}
2. 操作List列表类型数据
/**
* 操作List列表类型的数据:lpush,lpop,rpush,rpop
*/
@Test
void testList() {
// lpush
redisTemplate.opsForList().leftPushAll("list01","A","B","C","D","E","F");
// 获取List列表中元素的个数
Long list01Size = redisTemplate.opsForList().size("list01");
System.out.println("list01列表中元素的个数为:" + list01Size);
// range-获取
List list01 = redisTemplate.opsForList().range("list01",0L,-1L);
System.out.println("lpush后list01列表中出元素的顺序为:" + list01);
// lpop-leftPop(K key):删除并返回存储在Key列表中的第一个元素
Object firstObj = redisTemplate.opsForList().leftPop("list01");
System.out.println("存储在list01列表中的第一个元素为:" + firstObj);
System.out.println("-------------------分割线条--------------------");
// rpush
redisTemplate.opsForList().rightPushAll("list02","A","B","C","D","E","F");
// 获取List列表中元素的个数
Long list02Size = redisTemplate.opsForList().size("list02");
System.out.println("list02列表中元素的个数为:" + list02Size);
// range-获取
List list02 = redisTemplate.opsForList().range("list02",0L,-1L);
System.out.println("rpush后list02列表中取出元素的顺序为:" + list02);
// rpop-rightPop(K key):删除并返回存储在Key列表中的最后一个元素
Object lastObj = redisTemplate.opsForList().rightPop("list02");
System.out.println("存储在list02列表中的最后一个元素为:" + lastObj);
}
3. 操作Set集合类型数据
/**
* 操作Set集合类型的元素:sadd,smembers,scard
*/
@Test
void testSet() {
// sadd
redisTemplate.opsForSet().add("set01","A","B","C","D","E","F","A","B","C");
// size
Long set01Size = redisTemplate.opsForSet().size("set01");
System.out.println("set01集合中元素的个数为:" + set01Size);
// smembers
Set<Object> set01 = redisTemplate.opsForSet().members("set01");
System.out.println("set01集合中元素的顺序为:" + set01);
System.out.println("-----------分割线-----------");
// sadd
redisTemplate.opsForSet().add("set02","C","D","E","G","H","I");
// size
Long set02Size = redisTemplate.opsForSet().size("set02");
System.out.println("set02集合中元素的个数为:" + set02Size);
// smembers
Set<Object> set02 = redisTemplate.opsForSet().members("set02");
System.out.println("set02集合中元素的顺序为:" + set02);
// sinter:获取两个集合的交集 union:求并集 diff:求差集
Set<Object> sinterSet = redisTemplate.opsForSet().intersect("set01","set02");
System.out.println("set01集合与set02集合的交集为:" + sinterSet);
}
4. 操作Hash哈希类型数据
/**
* 操作Hash类型的数据:hset,hget,hmset,hmget,hkeys,hvals
*/
@Test
void testHash() {
// hset = put()
redisTemplate.opsForHash().put("tb_user","name","Rose");
// hmset:批量操作 - putAll()
Map<String,Object> map = new HashMap<>();
map.put("age","6");
map.put("year","2008");
redisTemplate.opsForHash().putAll("tb_user",map);
// hget
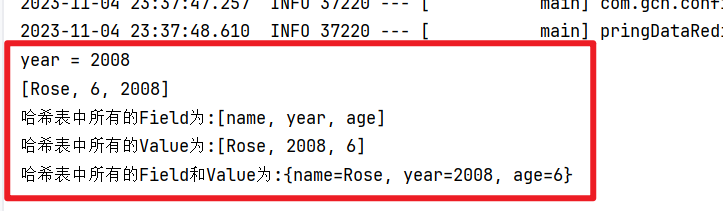
Object value = redisTemplate.opsForHash().get("tb_user","year");
System.out.println("year = " + value);
// hmget:取多个Field的值
List<Object> valueList = redisTemplate.opsForHash().multiGet("tb_user", Arrays.asList("name","age","year"));
System.out.println(valueList);
// hkeys Key:获取指定哈希键所有的Field
Set<Object> allField = redisTemplate.opsForHash().keys("tb_user");
System.out.println("哈希表中所有的Field为:" + allField);
// hvals Key:获取哈希表中所有的Value
List allValue = redisTemplate.opsForHash().values("tb_user");
System.out.println("哈希表中所有的Value为:" + allValue);
// hgetall key:获取所有的Field和Value entries()
Map<String,Object> all = redisTemplate.opsForHash().entries("tb_user");
System.out.println("哈希表中所有的Field和Value为:" + all);
} 5. 操作ZSet有序集合类型数据
5. 操作ZSet有序集合类型数据
/**
* ZSet有序集合类型数据的操作
*/
@Test
void testZSet() {
// zadd
redisTemplate.opsForZSet().add("ZSetType","Java",80);
redisTemplate.opsForZSet().add("ZSetType","Web",75);
redisTemplate.opsForZSet().add("ZSetType","Go",90);
redisTemplate.opsForZSet().add("ZSetType","Python",85);
redisTemplate.opsForZSet().add("ZSetType","Rust",98);
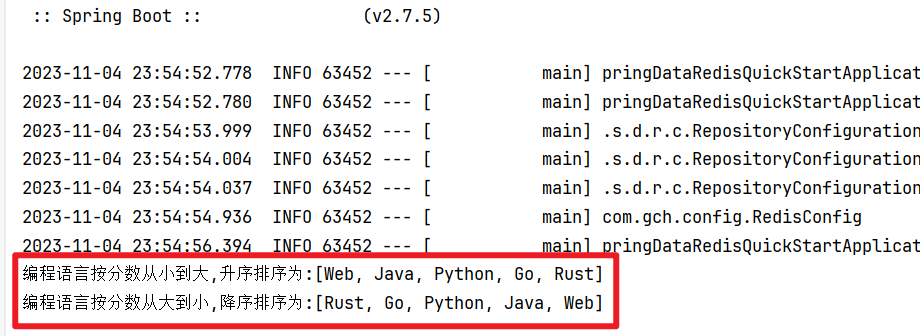
// 按分数从小到大,升序排序 => zrange
Set<Object> range = redisTemplate.opsForZSet().range("ZSetType",0,-1);
System.out.println("编程语言按分数从小到大,升序排序为:" + range);
// 按分数从大到小,降序排序 => zreverange
Set<Object> reverseRange = redisTemplate.opsForZSet().reverseRange("ZSetType",0,-1);
System.out.println("编程语言按分数从大到小,降序排序为:" + reverseRange);
// rangeByScore(key,min,max) 获取按照指定分数区间的Value并按照从小到大,升序排序,返回值类型为Set
// reverseRangeByScore(key,min,max) 获取指定分数区间的Value并按照从大到小,降序顺序,返回值类型为Set
} 通用命令操作
通用命令操作
/**
* 通用命令的操作
* 补充:要使用同一格式来进行序列化与反序列化
*/
@Test
void testCommon() {
// 1. 获取所有的Key
Set<Object> allKeys = redisTemplate.keys("*");
System.out.println("所有的Key为:" + allKeys);
// 2. 删除Key
Boolean result = redisTemplate.delete("key");
System.out.println(result == true ? "删除成功" : "删除失败");
}
在项目当中的真实应用是要保存对象:使用Redis的二进制形式存放对象(序列化)
方案1:在Redis当中存放一个对象,使用JSON序列化与反序列化(太Low了~!)

方案2:直接使用Redis自带的序列化方式存储对象~!
- 注意:保存在Redis当中的数据是要被序列化的(存放二进制的时候必须要把对象序列化的),因此一个对象要想能够成功的保存到Redis当中,那么该对象所归属的类就必须要实现一个接口:Serializable序列化接口,否则直接存放运行后程序会报错!
- 因此,在后续的项目当中,所有的实体类都要实现Serializable序列化接口!
- 注意:需要序列化的对象一定要实现Serializable序列化接口!
package com.gch.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
/**
* 该实体类想要存放到Redis当中,就必须被序列化,因此要实现Serializable接口
*/
public class User implements Serializable {
private String name;
private Integer age;
}
/**
* 保存对象:保存在Redis当中的数据是要被序列化的
*/
@Test
void testObject() {
// 保存对象
redisTemplate.opsForValue().set("tb_user",new User("Jerry",6));
// 获取对象
Object obj = redisTemplate.opsForValue().get("tb_user");
System.out.println("保存的对象数据为:" + obj.toString());
}

智能推荐
表格内容的展开和折叠效果《超实用的JavaScript代码段》笔记_html设置table展开怎么设置-程序员宅基地
文章浏览阅读902次。<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>表格内容的展开和折._html设置table展开怎么设置
PTA 6-2 顺序表操作集 (20 分)-容易做错-程序员宅基地
文章浏览阅读1.6k次,点赞9次,收藏33次。综述: 该题为数据结构顺序表基本操作相关的题目,其中包括插入、寻找、删除以及创建线性表共4个要求,题目给了函数接口的定义,要求你写相关函数,我开始在做这个题的时候对这个题的意思有了点误解,题目说Last保存最后一个元素的位置,然后它要开MAXSIZE个int大小的空间,因为这个Last的描述我开始忽略了顺序表的特性,让我难受了好久。本篇博客大致讲解一下该题目的做法。题目:本题要求实现顺序表的操作集。函数接口定义:List MakeEmpty();..._6-2 顺序表操作集
ABBYY2024免费永久版OCR图片文字识别软件_orc识别软件-程序员宅基地
文章浏览阅读316次,点赞3次,收藏10次。总体来说,ABBYY FineReader 15是一款功能强大、易于使用的OCR图片文字识别软件,适合个人和企业用户在多种场景下使用。然而,用户也需要考虑其价格和资源消耗等因素是否适合自己的需求。_orc识别软件
使用SBM-DEA模型优化绩效评估:理论、案例与MATLAB实践-程序员宅基地
文章浏览阅读1.9k次。数据包络分析是一种非参数方法,用于评估各种类型的决策单元,如企业、医院、学校等。其核心思想是将各个决策单元的输入和输出转化为一个效率评分,以比较它们的相对绩效。DEA的主要应用领域包括绩效评估、资源分配、效率改进等。_sbm-dea
计算机应用模块数量如何填写,职称计算机考试科目、模块数量介绍-程序员宅基地
文章浏览阅读1.7k次。原标题:职称计算机考试科目、模块数量介绍全国计算机应用能力考试坚持"实事求是,区别对待,逐步提高"的原则,不同地区、不同部门根据本地区、本部门的实际情况,确定适合本地区、本部门的考试范围要求。1、不同地区和部门自主确定应考科目数量在对专业技术人员计算机应用能力的具体要求上,各省、自治区、直辖市人事厅(局)和国务院有关部门干部(人事)部门应结合本地区、本部门的实际情况,确定本地区、本部门在评聘专业技..._模块数
设计一个 shell 程序,添加一个新组为 class1,然后添加属于这个组的 30 个用户,用户名的形式为 stdxx ,其中 xx 从 01 到 30_设计一个shell程序,添加一个新组为class1,然后添加属于这个组的30个用户,用户名的-程序员宅基地
文章浏览阅读5.5k次,点赞3次,收藏49次。Linux例题:设计一个 shell 程序,添加一个新组为 class1,然后添加属于这个组的 30 个用户,用户名的形式为 stdxx ,其中 xx 从 01 到 30_设计一个shell程序,添加一个新组为class1,然后添加属于这个组的30个用户,用户名的
随便推点
Windows下安装Hive(包安装成功)_windows安装hive-程序员宅基地
文章浏览阅读5.1k次,点赞12次,收藏28次。Hive 的Hive_x.x.x_bin.tar.gz 高版本在windows 环境中缺少 Hive的执行文件和运行程序。配置文件目录(%HIVE_HOME%\conf)有4个默认的配置文件模板拷贝成新的文件名。可以发现,自动连接MySQL去创建schema hive,并执行脚本。可以通过访问namenode和HDFS的Web UI界面(以及resourcemanager的页面(先在Hive安装目录下建立。根据自己的Hive安装路径(根据自己的Hive安装路径(请严格按照版本来安装。在Hadoop管理台(_windows安装hive
无偏估计+求样本的方差为何除n-1_设总体x~n(θ,1),gθ=θ2,试求gθ的无偏估计的方差下界-程序员宅基地
文章浏览阅读464次。$$f(x)={xˉ=∑1nxin均值S2=∑1n(x−xi)2n−1方差f(x)=\begin{cases} \bar{x}=\frac{ \sum_{1}^{n} x_{i} }{n}& \text{均值}\\S^2= \frac{ \sum_{1}^{n} (x- x_{i} )^2 }{n-1} & \text{方差}\end{cases}f(x)={xˉ=n∑1nxiS2=n−1∑1n(x−xi)2均值方差求样本方差为什么除n−1?求样本方差_设总体x~n(θ,1),gθ=θ2,试求gθ的无偏估计的方差下界
Linux学习教程,Linux入门教程(超详细)| 网址推荐_linux中大量使用脚本语言,而不是c语言!-程序员宅基地
文章浏览阅读1.3k次,点赞2次,收藏51次。1Linux简介2Linux安装3Linux文件和目录管理4Linux打包(归档)和压缩5Vim文本编辑器6Linux文本处理(Linux三剑客)7Linux软件安装8Linux用户和用户组管理9Linux权限管理10Linux文件系统管理11Linux高级文件系统管理12Linux系统管理13Linux备份与恢复14Linux系统服务管理15Linux系统日志管理16Linux启动管理17LAMP环境搭建和LNMP环境搭建18SEL..._linux中大量使用脚本语言,而不是c语言!
c语言函数base,c中base的用法-程序员宅基地
文章浏览阅读1.7k次。c中base的用法的用法你知道吗?下面小编就跟你们详细介绍下c中base的用法的用法,希望对你们有用。c中base的用法的用法如下:1、调用基类中的重名方法[csharp]public class Person{protected string ssn = "444-55-6666";protected string name = "John L. Malgraine";public virtua..._c语言中base=16是什么意思
为什么接口中变量要用final修饰_接口参数都定义为final的作用-程序员宅基地
文章浏览阅读6.7k次,点赞3次,收藏7次。今天碰到这个问题时候,还真不好理解,只知道interface中的变量默认是被public static final 修饰的,接口中的方法是被public和abstrct修饰的。查阅了很多资料,做了些例子,得出以下结论,不足的地方希望大家指出。 Java代码 /* * 关于抽象类和接口 * * 1_接口参数都定义为final的作用
【R语言学习笔记】6、List列表详解_r语言怎么查看list有几个项目-程序员宅基地
文章浏览阅读4.4k次,点赞3次,收藏25次。创建一个list列表> mylist <- list(stud.id = 1234,+ stud.name = "Tom",+ stud.marks = c(12, 3, 14, 25, 19))> mylist$stud.id[1] 1234$stud.name[1] "Tom"$stud.marks[1] 12 3 14 25 19取列表的值注..._r语言怎么查看list有几个项目