历史遗留问题1-Oracle Mysql如何存储数据、索引-程序员宅基地
在学习到Oracle redo和undo时,涉及到很多存储结构的知识,但是网上的教程都不是很详细,就去复习了一下mysql,感觉是不是开源的问题,Mysql的社区和知识沉淀远高于Oracle, 对于初学者很友好,我想请问深入学习这些知识学要怎么去了解,不会和win一样要打入内部吧!!!(本篇文章都是主观理解,作者自己知识的梳理,错误可能有点多)
数据库数据存储是一种逻辑结构,就像链表、树、堆一样,链表使用数组开辟一块内存放指向下一个数组的指针,堆是一种完全二叉树在底层其实维护的是一个数组,数据库索引的B-树、B+树,是一种多路平衡树,降低树的高度减少OS的IO操作,加入平衡算法防止线性化,3-4的高度就能满足大部分场景。其实学的数据结构数组、链表、堆、树、图都是逻辑上的,包括做开发用到的数据结构,做一些格式处理、格式转换,现在越来越方便,除了刷算法需要自己处理,平常都是用hutool等工具包,掉包,Python更甚,没有了解过底层是怎么存放的。Linux系统万物皆文件,在文件和文件管理这方面,是如何从内存写到寄存器、磁盘上的,存储格式是怎样的,一点都不懂。todo
为什么OS块4K、Oracle块8K、Mysql页16K,兼容有什么问题吗?
OS多开辟两个内存块存呗?
这种逻辑存储结构是如何存储到操作系统的?
我们看Mysql的
Mysql存储到操作系统上面,不同的引擎略有些差异,常用的InnoDB会有三个文件存放到操作系统,分别是.frm文件、.ibd文件、ibdata 文件
.frm文件存储表的定义,即表结构,包含表名、列定义、索引定义等元数据,每个InnoDB表都有一个对应的.frm文件
.ibd文件存储表的数据和索引(如果启用了innodb_file_per_table配置选项)包括表的数据行、主键索引、辅助索引以及MVCC(多版本并发控制)数据等
ibdata 文件存储InnoDB的系统表空间数据,包括数据字典、更改缓冲、撤销日志、锁信息等是一个共享的系统表空间文件,可能包含多个InnoDB表的数据(如果innodb_file_per_table未启用),以及其他InnoDB内部使用的信息。通常至少有一个ibdata文件(ibdata1),但可以通过配置增加更多的ibdata文件,并设置它们的自动扩展属性。
.ibd 文件的其他辅助文件: 除了 .ibd 文件本身外,InnoDB 存储引擎还会生成一些其他辅助文件,用于支持事务、恢复和性能优化等功能。这些辅助文件包括重做日志文件(redo log)、undo 日志文件、共享表空间文件等。这些文件通常不是直接用户可见的,而是由 MySQL 引擎管理的。
参考:Chat GPT:当使用 InnoDB 存储引擎存储数据时,每个表会对应一个 .frm 文件和一个 .ibd 文件(如果启用了单独表空间模式)。除此之外,InnoDB 还会生成一些其他辅助文件,用于支持数据库的事务和恢复功能。
MySql数据在磁盘上到底是怎么存储的?被存储的数据怎么查找? - 知乎 (zhihu.com)
MySQL数据文件介绍及存放位置 - jianhong - 博客园 (cnblogs.com)
B树这种逻辑结构存储到OS上是怎么存放的?
了解一下Mysql数据页的格式从 MySQL 数据页的角度看 B+ 树_b+数 调取某页数据到内存中,是什么形式-程序员宅基地,大概有7个部分:
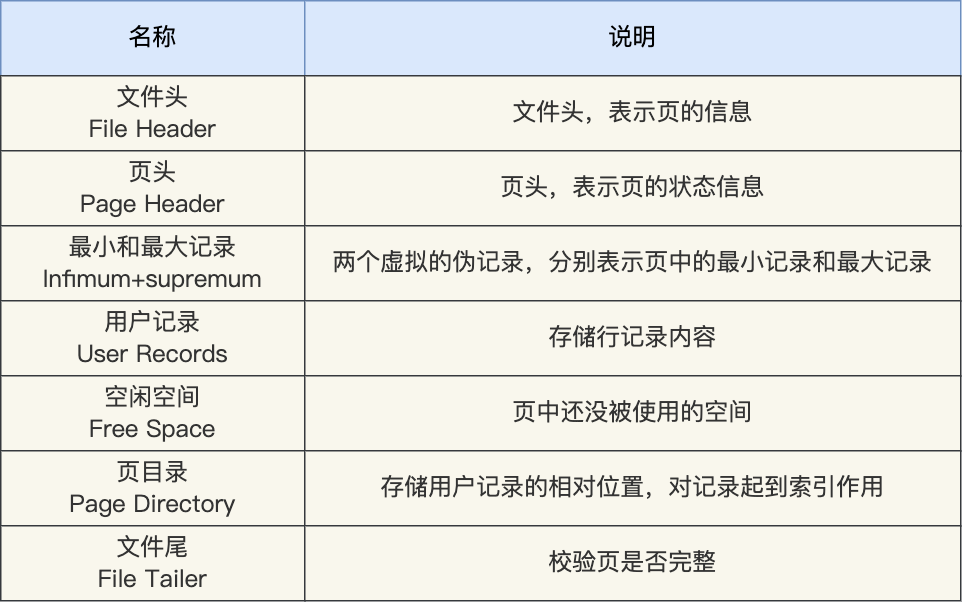
Mysql数据行格式:

Oracle的数据行格式,在往底层了解一下就找不到资料了
MySQL创建的表查看表结构信息中,有一栏 columns,在其中我们会看到处理我们建表时指定的字段以外,还有额外的三个字段 分别是:DB_TRX_ID 、 DB_ROLL_PTR 、DB_ROW_ID
DB_ROW_ID: 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。
DB_TRX_ID :最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID。
DB_ROLL_PTR:回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版本。’
有了这些知识再去学Mysql的备份恢复就会清晰很多,而且Mysql在做数据迁移时关注SQLthread两个IOthread线程和binlog日志就行,Mysql的存储结构和InnoDB结构很好理解,七个日志不需要全部了解。在学备份恢复就很简单,但是Oracle就学不明白他的某些方面的原理,学习曲线上比mysql高太多了。
其实怎么把数据存储到操作系统上,目前阶段还不需要太关心,可以把这个任务放到后面甚至时几年之后,但是今天在学习Oracle redo undo原理时,涉及到了存储结构,主要表达还是mysql和Oracle学习同样的内容,Oracle学习曲线上比mysql高太多了。排除Oracle和Mysql两者的复杂程度,客观上来讲Oracle对国内的学习支者持不是很友好,包括学习资料、知识沉淀、社区等,比如想搞懂一下页分裂、页合并阈值参数、数据行的存储格式、redo、undo的底层原理等,Oracle学起来都难太多了
索引相关
后面我又想到索引,主要是增加查询效率吗,对于OLTP系统来说是必要的,Oracle、MySQL都是在页目录里存放了索引信息,接着疑惑又来了,int自增主键的索引还比较好理解,那如果是非int型,我的理解是索引标识其实是一种类似二分查找的算法,需要自增,
如果不是自增的,会有什么影响?
首先我们知道,两者在建表时都会建立该系统默认的索引(B-树、B+树),默认是主键,没有主键会有一个隐藏字段Row_id,当作索引,这样一个B树的逻辑结构就有了,主键字段是数字类型 自增的,这里涉及到了主键优化的问题,如果主键不是自增的比如分布式系统中生成的UUID,64位的雪花算法虽然保证了大数据下的唯一性,但是在插入过程中或产生空间碎片,数据分布不均匀。主要是因为在看出过程中数据页会产生大量的页合并和页分裂。
为什么不用字符类型char、varchar、string当作索引?有没有一种算法是字符串生成自增唯一,那用什么算法实现呢?hash生成唯一标识符+时间戳?todo参考文献
还有就是在Mysql索引是由页目录维护的,页目录就是由多个槽组成的,槽相当于分组记录的索引。然后,因为记录是按照「主键值」从小到大排序的,所以通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,
如果我们增加一个索引,这个过程是什么样的?
主观猜想:首先把该字段通过算法(hash)生成一组多少位的二进制转成十进制进行排序,逻辑上建立B树,存储上在操作系统里告诉页目录,该索引字段的子节点内存地址只是多少,由页目录维护起来。那如果是联合索引呢?把三个字段放进算法(hash)生生唯一标识?为什么where后面不规范会造成索引失效?
太多问题了,午休时间到了,作为历史遗留问题,虽然可能工作中用不到这些,但是有精力和资料的话,还是学通透一些,可能在后面1年?3年?10年?搞明白了,去开国产发数据库
参考:
ChatGPT
在 Linux 操作系统上,当进行数据库数据的增删改查操作时,具体的数据存储方式取决于所使用的数据库管理系统(DBMS)和存储引擎。以下是常见的数据库系统在 Linux 上的数据存储方式:
-
MySQL/Oracle 数据库:
-
MySQL 和 Oracle 数据库通常使用类似的数据存储方式。数据存储在数据库文件中,这些文件通常以特定的扩展名(例如 .ibd 或 .dbf)存储在操作系统的文件系统中。
-
对于 InnoDB 存储引擎,数据和索引分别存储在 .ibd 文件中。当执行增删改查操作时,数据会被写入到对应的数据文件中,然后由数据库引擎负责管理和维护。
-
对于 Oracle 数据库,数据存储在表空间中的数据文件(.dbf 文件)中,而表空间由数据文件组成。当执行增删改查操作时,数据会被写入到对应的数据文件中,然后由 Oracle 数据库引擎管理。
-
-
PostgreSQL 数据库:
-
PostgreSQL 数据库使用 WAL(Write-Ahead Logging)机制,将数据和日志分开存储。数据存储在表空间中的数据文件中,而 WAL 日志存储在专门的日志文件中。
-
当执行增删改查操作时,数据会被写入到对应的数据文件中,同时相应的 WAL 日志也会被写入到日志文件中,以确保数据的一致性和持久性。
-
-
MongoDB 数据库:
-
MongoDB 数据库使用 BSON(Binary JSON)格式存储数据。数据存储在数据文件中,每个数据文件包含了一个或多个数据集(Collection)的数据。
-
当执行增删改查操作时,数据会被写入到对应的数据文件中,然后由 MongoDB 数据库引擎管理和维护。
-
总的来说,无论使用哪种数据库管理系统,数据存储在操作系统的文件系统中,具体的存储方式和文件结构取决于数据库管理系统和存储引擎的设计和实现。在执行增删改查操作时,数据会被写入到对应的数据文件中,并由数据库引擎负责管理和维护。
智能推荐
稀疏编码的数学基础与理论分析-程序员宅基地
文章浏览阅读290次,点赞8次,收藏10次。1.背景介绍稀疏编码是一种用于处理稀疏数据的编码技术,其主要应用于信息传输、存储和处理等领域。稀疏数据是指数据中大部分元素为零或近似于零的数据,例如文本、图像、音频、视频等。稀疏编码的核心思想是将稀疏数据表示为非零元素和它们对应的位置信息,从而减少存储空间和计算复杂度。稀疏编码的研究起源于1990年代,随着大数据时代的到来,稀疏编码技术的应用范围和影响力不断扩大。目前,稀疏编码已经成为计算...
EasyGBS国标流媒体服务器GB28181国标方案安装使用文档-程序员宅基地
文章浏览阅读217次。EasyGBS - GB28181 国标方案安装使用文档下载安装包下载,正式使用需商业授权, 功能一致在线演示在线API架构图EasySIPCMSSIP 中心信令服务, 单节点, 自带一个 Redis Server, 随 EasySIPCMS 自启动, 不需要手动运行EasySIPSMSSIP 流媒体服务, 根..._easygbs-windows-2.6.0-23042316使用文档
【Web】记录巅峰极客2023 BabyURL题目复现——Jackson原生链_原生jackson 反序列化链子-程序员宅基地
文章浏览阅读1.2k次,点赞27次,收藏7次。2023巅峰极客 BabyURL之前AliyunCTF Bypassit I这题考查了这样一条链子:其实就是Jackson的原生反序列化利用今天复现的这题也是大同小异,一起来整一下。_原生jackson 反序列化链子
一文搞懂SpringCloud,详解干货,做好笔记_spring cloud-程序员宅基地
文章浏览阅读734次,点赞9次,收藏7次。微服务架构简单的说就是将单体应用进一步拆分,拆分成更小的服务,每个服务都是一个可以独立运行的项目。这么多小服务,如何管理他们?(服务治理 注册中心[服务注册 发现 剔除])这么多小服务,他们之间如何通讯?这么多小服务,客户端怎么访问他们?(网关)这么多小服务,一旦出现问题了,应该如何自处理?(容错)这么多小服务,一旦出现问题了,应该如何排错?(链路追踪)对于上面的问题,是任何一个微服务设计者都不能绕过去的,因此大部分的微服务产品都针对每一个问题提供了相应的组件来解决它们。_spring cloud
Js实现图片点击切换与轮播-程序员宅基地
文章浏览阅读5.9k次,点赞6次,收藏20次。Js实现图片点击切换与轮播图片点击切换<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title></title> <script type="text/ja..._点击图片进行轮播图切换
tensorflow-gpu版本安装教程(过程详细)_tensorflow gpu版本安装-程序员宅基地
文章浏览阅读10w+次,点赞245次,收藏1.5k次。在开始安装前,如果你的电脑装过tensorflow,请先把他们卸载干净,包括依赖的包(tensorflow-estimator、tensorboard、tensorflow、keras-applications、keras-preprocessing),不然后续安装了tensorflow-gpu可能会出现找不到cuda的问题。cuda、cudnn。..._tensorflow gpu版本安装
随便推点
物联网时代 权限滥用漏洞的攻击及防御-程序员宅基地
文章浏览阅读243次。0x00 简介权限滥用漏洞一般归类于逻辑问题,是指服务端功能开放过多或权限限制不严格,导致攻击者可以通过直接或间接调用的方式达到攻击效果。随着物联网时代的到来,这种漏洞已经屡见不鲜,各种漏洞组合利用也是千奇百怪、五花八门,这里总结漏洞是为了更好地应对和预防,如有不妥之处还请业内人士多多指教。0x01 背景2014年4月,在比特币飞涨的时代某网站曾经..._使用物联网漏洞的使用者
Visual Odometry and Depth Calculation--Epipolar Geometry--Direct Method--PnP_normalized plane coordinates-程序员宅基地
文章浏览阅读786次。A. Epipolar geometry and triangulationThe epipolar geometry mainly adopts the feature point method, such as SIFT, SURF and ORB, etc. to obtain the feature points corresponding to two frames of images. As shown in Figure 1, let the first image be and th_normalized plane coordinates
开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先抽取关系)_语义角色增强的关系抽取-程序员宅基地
文章浏览阅读708次,点赞2次,收藏3次。开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先关系再实体)一.第二代开放信息抽取系统背景 第一代开放信息抽取系统(Open Information Extraction, OIE, learning-based, 自学习, 先抽取实体)通常抽取大量冗余信息,为了消除这些冗余信息,诞生了第二代开放信息抽取系统。二.第二代开放信息抽取系统历史第二代开放信息抽取系统着眼于解决第一代系统的三大问题: 大量非信息性提取(即省略关键信息的提取)、_语义角色增强的关系抽取
10个顶尖响应式HTML5网页_html欢迎页面-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏51次。快速完成网页设计,10个顶尖响应式HTML5网页模板助你一臂之力为了寻找一个优质的网页模板,网页设计师和开发者往往可能会花上大半天的时间。不过幸运的是,现在的网页设计师和开发人员已经开始共享HTML5,Bootstrap和CSS3中的免费网页模板资源。鉴于网站模板的灵活性和强大的功能,现在广大设计师和开发者对html5网站的实际需求日益增长。为了造福大众,Mockplus的小伙伴整理了2018年最..._html欢迎页面
计算机二级 考试科目,2018全国计算机等级考试调整,一、二级都增加了考试科目...-程序员宅基地
文章浏览阅读282次。原标题:2018全国计算机等级考试调整,一、二级都增加了考试科目全国计算机等级考试将于9月15-17日举行。在备考的最后冲刺阶段,小编为大家整理了今年新公布的全国计算机等级考试调整方案,希望对备考的小伙伴有所帮助,快随小编往下看吧!从2018年3月开始,全国计算机等级考试实施2018版考试大纲,并按新体系开考各个考试级别。具体调整内容如下:一、考试级别及科目1.一级新增“网络安全素质教育”科目(代..._计算机二级增报科目什么意思
conan简单使用_apt install conan-程序员宅基地
文章浏览阅读240次。conan简单使用。_apt install conan