hadoop mapreduce java 单词统计三个实现方法_hadoop数据分块单词被分开怎么统计-程序员宅基地
技术标签: mapreduce hadoop mapreduce 单词统计 大数据
hadoop MapReduce框架可以让你的应用在集群中:可靠地、容错地、并行、处理TB级别的数据。
本实例通过idea运行java本地代码,实现统计单词计数。
hadoop集群搭建见 hadoop基于zookeper自动高可用搭建。这里就不在重复赘述。
1 统计文件准备
1.1 创建需要统计单词的文件
任意选择一条服务器,创建包含hello world number hello.txt文件
for i in `seq 100000`;do echo hello world $i >hello.txt ;done;

1.2 上传到hdfs文件系统上
创建目录 /home/root
hdfs dfs -mkdir /home
hdfs dfs -mkdir /home/root
查看是否创建成功
hdfs dfs -ls /home

上传文件到hdfs服务器上
设置块大小为1MB
hdfs dfs -D dfs.blocksize=1048576 -put hello.txt /home/root
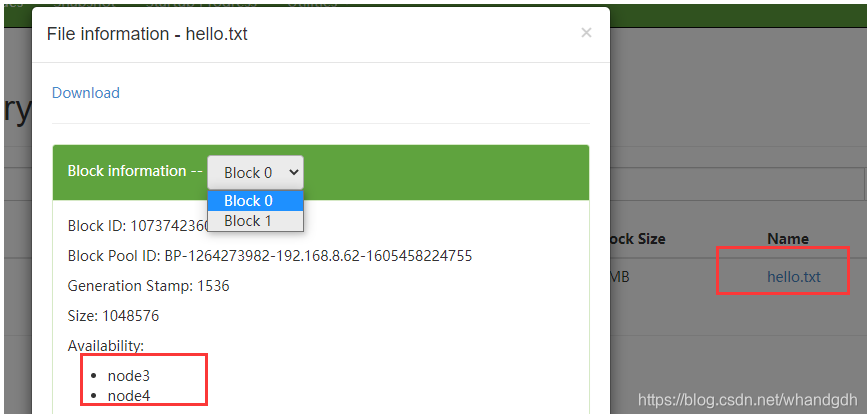
通过前台页面:node2:50070 可以看到上传文件被分为2个块 ,存放在node3和node4上
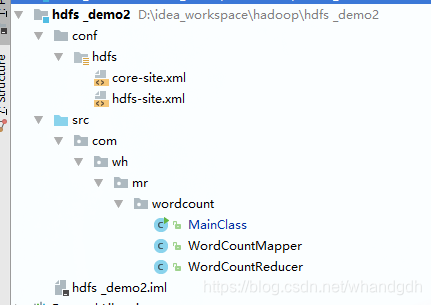
2 创建java项目
结构如下:
2.1 配置文件
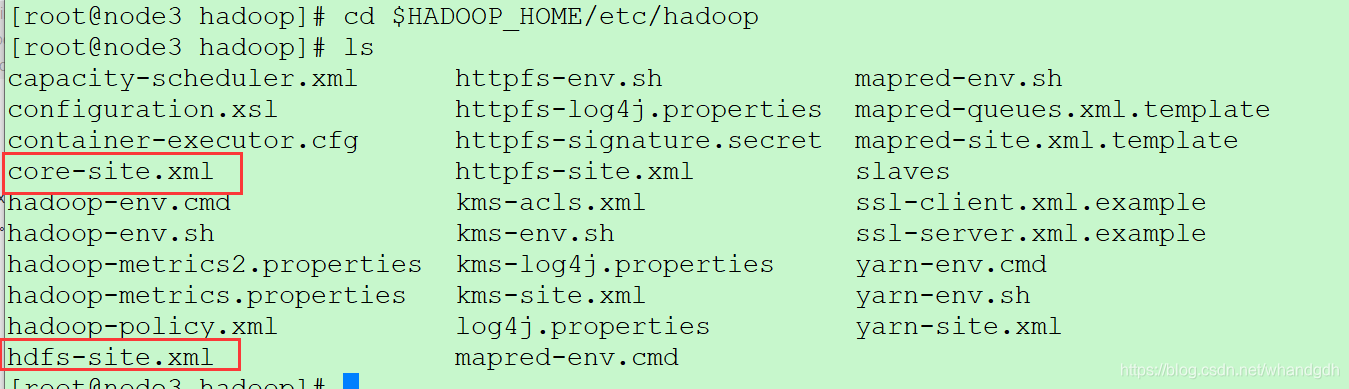
conf目录下配置文件core-site.xml和hdfs-site.xml文件来在hadoop集群服务器上,路径为HADOOP_HOME/etc/hadoop。将此文件拷贝到本地java工程即可
cd $HADOOP_HOME/etc/hadoop
2.2 java代码
2.2.1 WordCountMapper 类
WordCountMapper 类需要重写map方法,代码如下:
ublic class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// key value
// <0, "hello world 1">
// "hello bjsxt 1" 输出到reduce
String line=value.toString();
String [] words=line.split(" ");
for (int i = 0; i < words.length-1; i++) {
//排除最后一位数字
context.write(new Text(words[i]),new IntWritable(1));
}
}
}
2.2.2WordCountReducer 类
WordCountReducer 类需要重写reduce方法。代码如下
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
// <"hello", 1>
// <"hello", 1>
// key "hello", {
1,1,1,1,1,1,1,1,1,1,1,1} reducer 处理前结果
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
// 输出结果为 <hello ,120>
context.write(key,new IntWritable(sum));
}
}
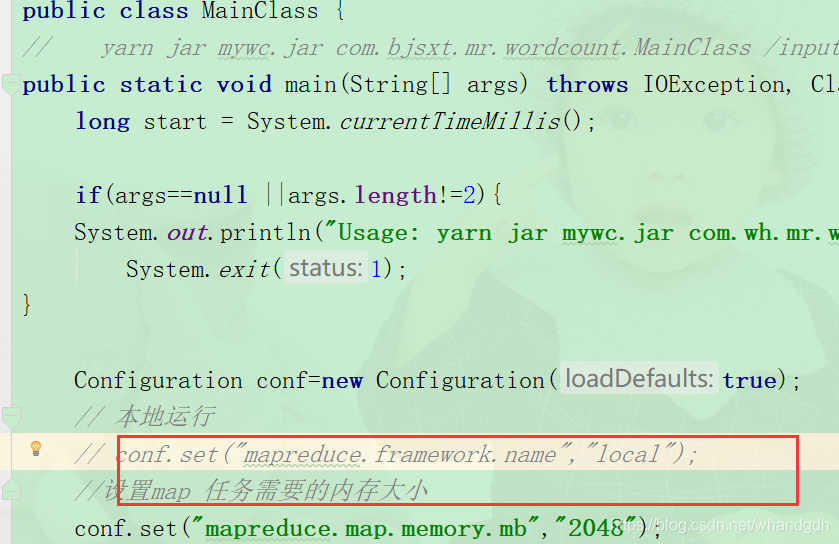
2.2.3 MainClass 类
MainClass类为本地运行类,代码如下:
//客户端运行
public class MainClass {
// yarn jar mywc.jar com.bjsxt.mr.wordcount.MainClass /input /output
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
long start = System.currentTimeMillis();
if(args==null ||args.length!=2){
System.out.println("Usage: yarn jar mywc.jar com.wh.mr.wordcount.MainClass <inpath> <outpath>");
System.exit(1);
}
Configuration conf=new Configuration(true);
// 本地运行
conf.set("mapreduce.framework.name","local");
// 创建mapreduce作业Job对象
Job job=Job.getInstance(conf);
// 设置作业的名称
job.setJobName("单次计数");
// 设置作业的主入口类
job.setJarByClass(MainClass.class);
// 设置输入文件路径,该方法可以调用多次,用于设置多个输入文件路径
FileInputFormat.addInputPath(job,new Path(args[0]));
// 设置输出文件路径
FileOutputFormat.setOutputPath(job,new Path(args[1]));
// 设置mapper类
job.setMapperClass(WordCountMapper.class);
// 设置reducer类
job.setReducerClass(WordCountReducer.class);
// 设置mapper输出key的类型,用于排序
job.setMapOutputKeyClass(Text.class);
// 设置mapper输出value的类型
job.setMapOutputValueClass(IntWritable.class);
// 提交作业到集群运行,并等待程序在集群中运行结束
job.waitForCompletion(true);
long end = System.currentTimeMillis();
long cost = end - start;
System.out.println("耗时:"+cost);
}
}
3 参数设置
需要从main方法传入需要处理的文件以及输出结果目录,设置如下图所示
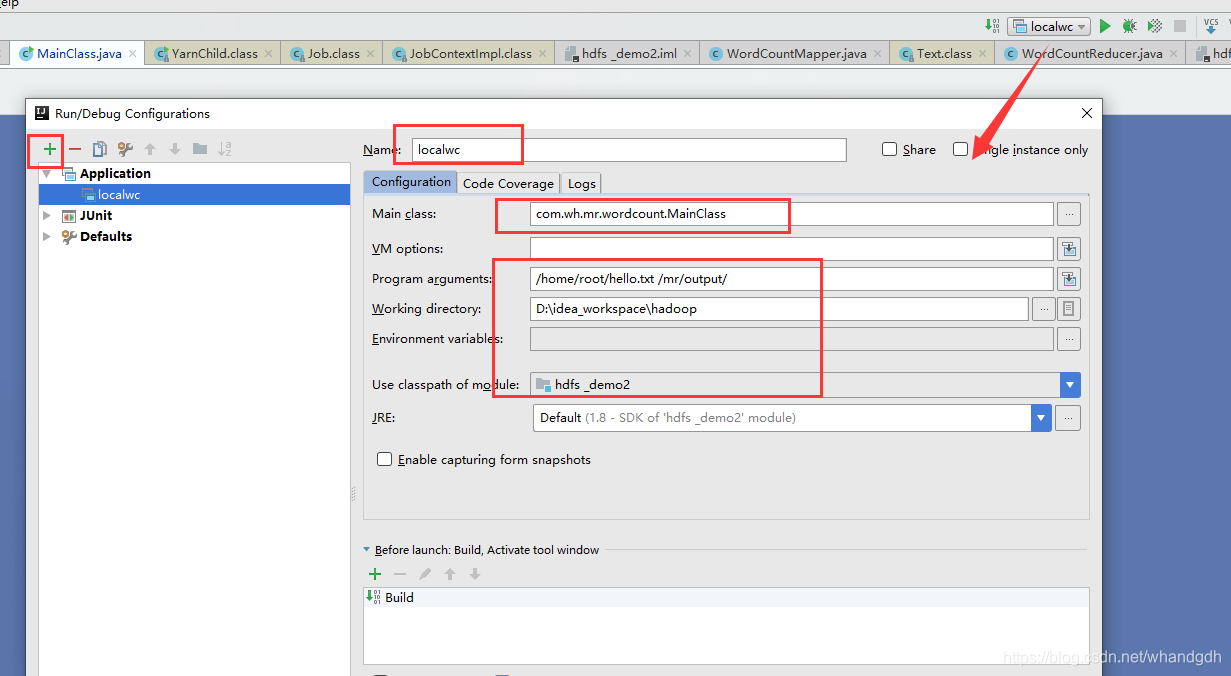
需要注意的是 program arguments参数设置需要处理的文件以及处理结果路径。结果处理存放路径不能是存在的,不然程序会抛异常
4 运行结果
运行程序以后,通过页面node2:50070进入文件管理可以看到执行结果
存放到/mr/output目录下
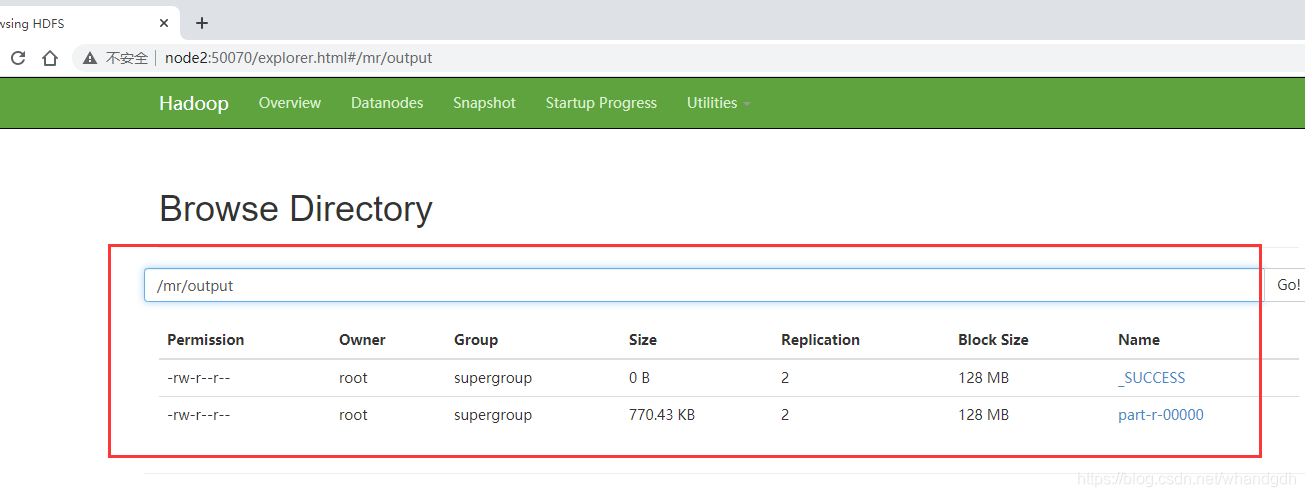
执行结果写入到 part-r-00000文件中,该文件块id为1073742362。
写入到node3和node5上
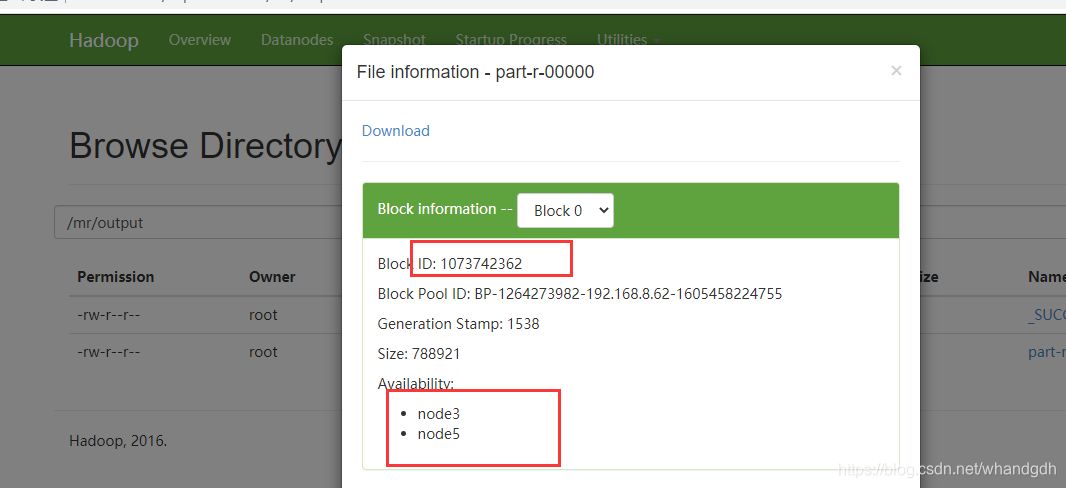
node3和node5任意选一台,本实例选择node5.
进入数据存放目录。
core-site.xml(cd $HADOOP_HOME/etc/hadoop)这个配置文件
/var/wh/hadoop/ha

进入如下路径
var/wh/hadoop/ha/dfs/data/current/BP-1264273982-192.168.8.62-1605458224755/current/finalized/subdir0
进入后有三个文件
查找执行结果文件存放目录
find . -name '*1073742362*'
看到 文件存放在 subdir2下
vim blk_1073742362
看到 统计hello 和world 个数都为10w个 
5 服务器运行本地单词计数程序
hadoop自带有单词统计程序,在 $HADOOP_HOME/share/hadoop/mapreduce目录下
cd $HADOOP_HOME/share/hadoop/mapreduce
ls
在这里插入图片描述
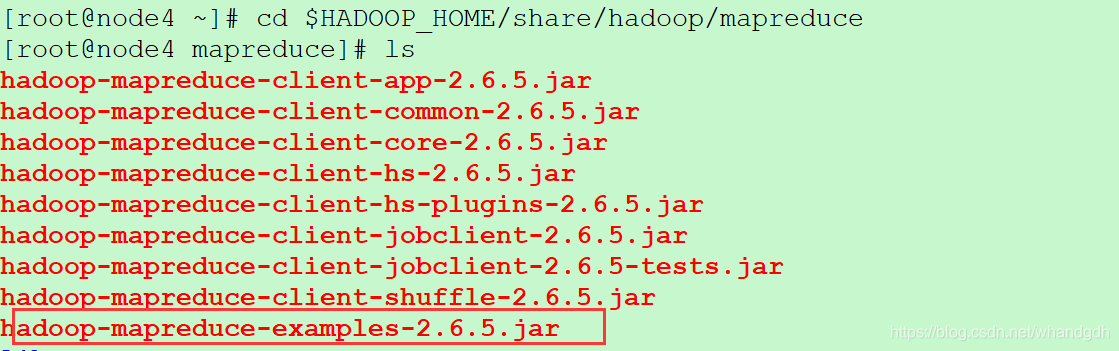
然后执行
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /home/root/hello.txt /mr/wordcount/output
*ouput:是hdfs中不存在的目录,mr程序运行的结果会输出到该目录
执行结果
hdfs dfs -ls /mr/wordcount/output
结果存放在part-r-00000文件上
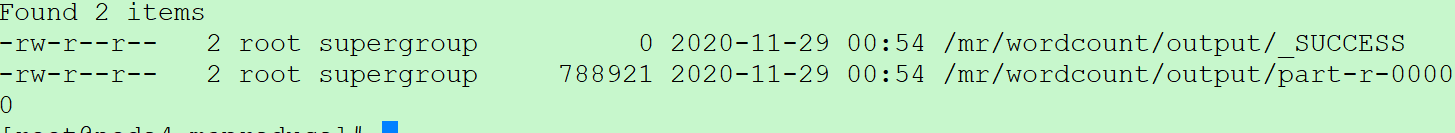
再通过如下命令查看结果
hdfs dfs -cat /mr/wordcount/output/part-r-00000
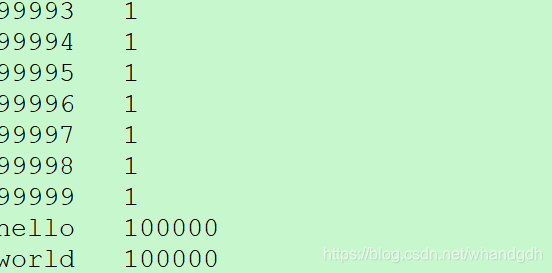
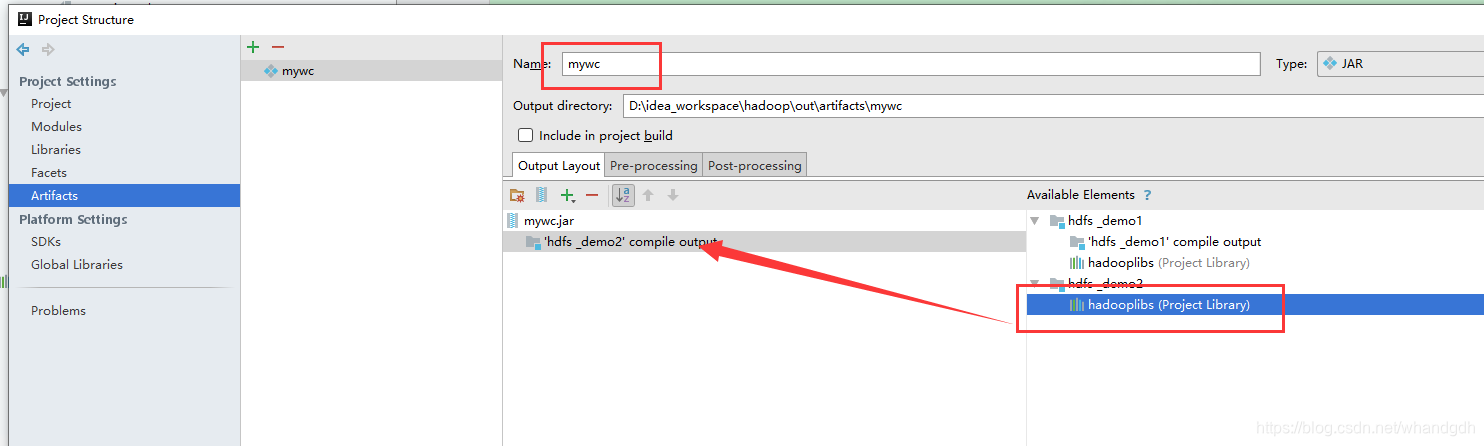
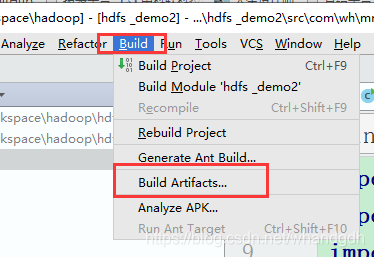
6 打包本地java代码到服务器执行
还可以将本地的java代码打包到服务器执行,只是需要将mainclass文件中设置本地运行代码注释掉
conf.set("mapreduce.framework.name","local");
打包页面如下
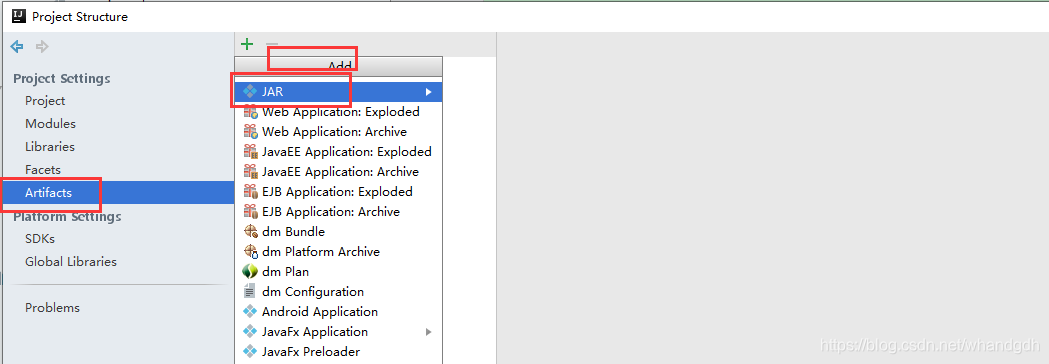
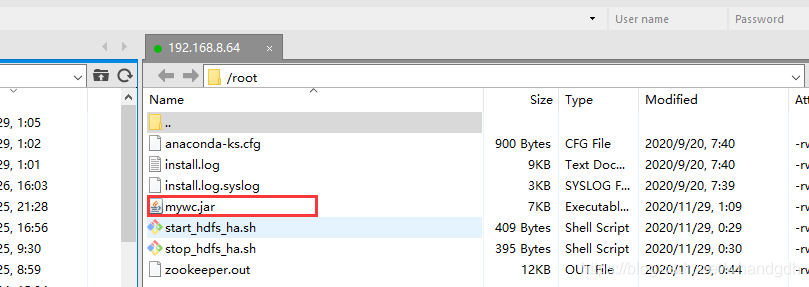
进入到打包目录找到包文件
D:\idea_workspace\hadoop\out\artifacts\mywc

上传代码到服务器上,
如果没有传参数运行
yarn jar mywc.jar com.wh.mr.wordcount.MainClass
可以看到这里运行结果按照java代码中进行退出。


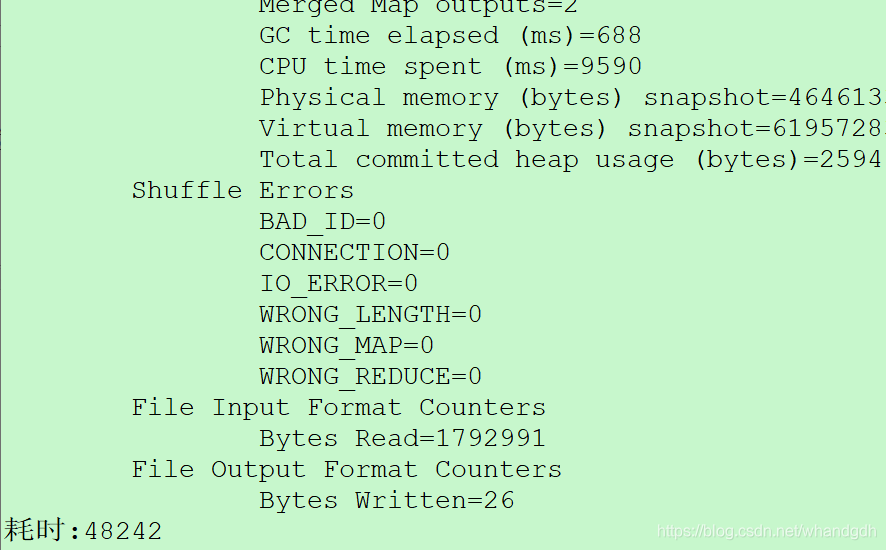
yarn jar mywc.jar com.wh.mr.wordcount.MainClass /home/root/hello.txt /mr/wordcount/output2
运行结果
智能推荐
两端固定弦的自由振动 | 分离变量法(一)| 偏微分方程(十三)_两端固定振动定解问题分离变量-程序员宅基地
文章浏览阅读6.2k次,点赞5次,收藏25次。分离变量法是一种可用来求某些典型区域上定解问题精确解的经典方法,本章将通过典型例子,介绍分离变量法的基本思想和具体步骤,并提出方法的理论核心——固有值问题,进而从Fourier展开角度来认识和应用分离变量法。两端固定弦的自由振动作为乐器上弦的发声模型,讨论两端固定的弦在初始扰动影响下产生的运动。选弦在张力作用下的平衡位置为x轴,线上各质点的横向位移u(t,x)u(t,x)u(t,x)满足弦振动方程的混合问题{∂2u∂t2=a2∂2u∂x2,t>0,0<x<l,(1a)u∣x=0=u∣_两端固定振动定解问题分离变量
python+selenium 捕捉不到弹出的div类型的提示解决方法_selenium div弹出层-程序员宅基地
文章浏览阅读1w次。我在用python+selenium,进行某一网址,登录口的测试时,对错误处理进行处理用户名 错误用户名 密码 正确密码格式 然后,如果是上面这种情况,系统会从右上角弹出一个类似于文本框的提示:不存在该用户名或用户被禁用!但是这个框,我尝试捕获<p>,<div>,它是div类型的,但是无法捕获,如下:b.find_element_b..._selenium div弹出层
第01章 Java语言概述-程序员宅基地
文章浏览阅读521次。软件,即一系列按照特定顺序组织的计算机数据和指令的集合。有系统软件和应用软件之分。Pascal之父Nicklaus Wirth: “Programs = Data Structures + Algorithms”系统软件:是SUN(Stanford University Network,斯坦福大学网络公司 )1995年推出的一门高级编程语言。是一种面向Internet的编程语言。Java一开始富有吸引力是因为Java程序可以在Web浏览器中运行。这些Java程序被称为Java小程序。
加油站抽烟烟火智能识别算法_烟火识别算法培训内容-程序员宅基地
文章浏览阅读377次。加油站抽烟烟火智能识别系统通过yolo+opencv网络模型图像识别分析技术,加油站抽烟烟火智能识别算法识别出抽烟和燃放烟火的情况,并发出预警信号以提醒相关人员,减少火灾风险。OpenCV基于C++实现,同时提供python, Ruby, Matlab等语言的接口。OpenCV-Python是OpenCV的Python API,结合了OpenCV C++API和Python语言的最佳特性。OpenCV-Python使用Numpy,这是一个高度优化的数据库操作库,具有MATLAB风格的语法。所有OpenCV数_烟火识别算法培训内容
用逻辑门制作出加法器_逻辑门电路怎么算加法-程序员宅基地
文章浏览阅读4.2k次,点赞8次,收藏26次。文章目录1 用逻辑门制作出加法器1.1 半加器1.2 全加器1.3 8位加法器1 用逻辑门制作出加法器1.1 半加器我们首先看下二进制加法的运算规则:我们将加法值、进位值的真值表和异或运算、与运算的真值表进行对比:我们可以使用异或门、与门电路搭建不带进位的加法器:我们将内部逻辑门进行封装,只留出输入输出引脚:1.2 全加器我们可以在半加器的基础上制造全加器:我们加全加器..._逻辑门电路怎么算加法
python——爬虫与脚本_python爬虫脚本-程序员宅基地
文章浏览阅读1.7k次,点赞2次,收藏4次。关于py在其他方面的脚本或爬虫应用_python爬虫脚本
随便推点
Linux——通过OTG方式烧写镜像文件步骤详解_怎么用otg烧写img-程序员宅基地
文章浏览阅读217次,点赞2次,收藏2次。其中,/path/to/image.img是你要烧写的镜像文件路径,/dev/sdX是你的设备名称。确保设备已连接并挂载后,使用dd命令将镜像文件写入设备,最后同步缓存并卸载设备即可。在本文中,我们将介绍如何通过OTG方式在Linux系统下进行镜像文件的烧写,并提供相应的源代码。请注意,使用dd命令时需要谨慎,确保指定正确的设备名称,以免误写入其他设备导致数据丢失。在完成烧写后,我们需要同步缓存并从系统中卸载设备。接下来,我们需要将设备挂载到文件系统中。其中,/dev/sdX是你的设备名称,可以通过执行。_怎么用otg烧写img
Android listview viewpager解决冲突 滑动,android开发需要什么基础-程序员宅基地
文章浏览阅读275次,点赞4次,收藏10次。这个方法只是改变flag*/@Overrideif (parent!= null) {
聊聊运营商对UDP的QoS限制和应对_udp qos-程序员宅基地
文章浏览阅读3.5w次,点赞41次,收藏80次。UDP和运营商有什么关系?这个问题有点大且突兀。只要不是在三大运营商上班的,其实我们都是端到端用户,而端到端用户对于网络的认知必然是盲目的,我们不知道路由器对我们的流量做了什么,我们更没有能力去控制它们,我们只能猜测。本来一个技术范畴的讨论一旦涉及到了猜测,就不是技术讨论了,而是社会学讨论,这往往会带来无休止的辩论,争吵,在此其中,独占鳌头的往往不是靠技术实力,而是靠口才和措辞,或者还有夹杂着各种手势的抑扬顿挫。我是极其讨厌充斥着此类调调的场合的,我在这种场合往往会选择闭嘴,然后离开。人们无休止地讨_udp qos
数据库查询 数据库笔记_数据库笔记查-程序员宅基地
文章浏览阅读89次。单表查询简单查询在编辑器里面查询特定的数据对数据进行处理 use xscj;select * ,cj*1.5 as'折算成150分的成绩'from cj;求平均分创建一个新的字段 模糊查询通配符 :% :代表0个或多个字符 _ :1个字符查找中间字符..._数据库笔记查
线性方程组的解-Gauss列主元削去法和Gauss-Seidel迭代法-程序员宅基地
文章浏览阅读362次,点赞10次,收藏6次。用随机函数随机产生一个n阶线性方程组,用Gauss列主元削去法和Gauss-Seidel迭代法求解线性方程组,并且对该解进行验算及误差验证。
【微信小程序】JS文件内数组循环(批量)更新方法 图片批量增删_微信小程序js循环-程序员宅基地
文章浏览阅读1.3k次。学习笔记,一个小小的总结_微信小程序js循环