Tensorflow for Java + Spark-Scala分布式机器学习计算框架的应用实践(1)-程序员宅基地
技术标签: 2024年程序员学习 tensorflow 机器学习 分布式
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
上面我们说了选择Tensorflow for Java & Spark-Scala的目的是满足高性能的场景需求。下面分析下两种方案性能上的差异。
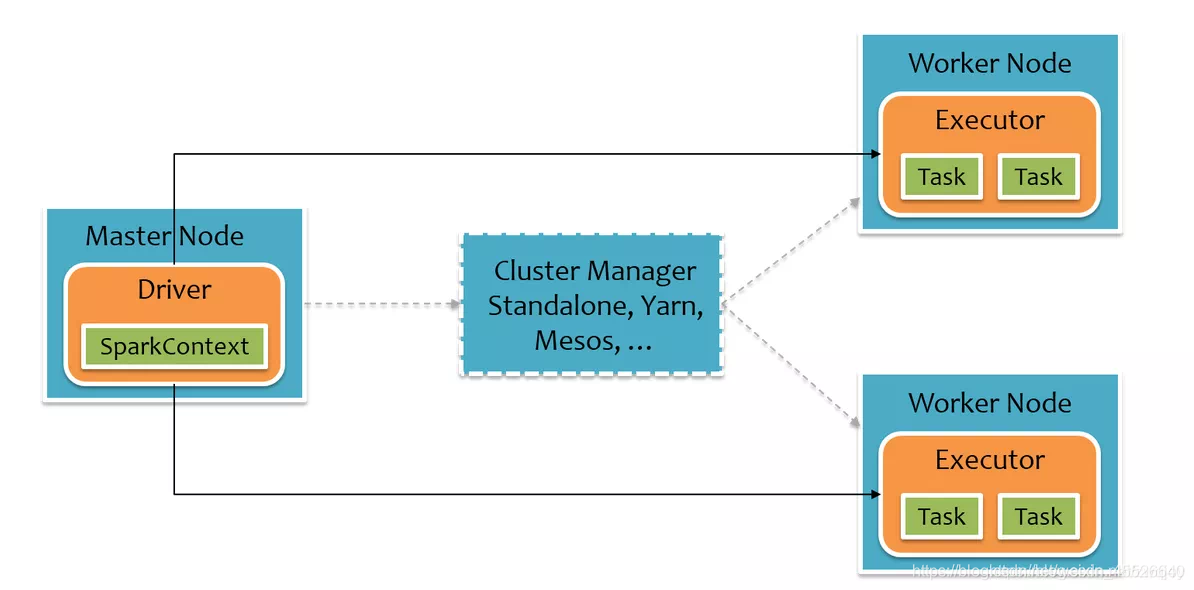
Spark 的运行时架构如下。用户的Spark应用程序运行在 Driver 上,经过 Spark 调度封装成一个个 Task ,再将这些 Task 信息发给 Executor 执行。Scala 版本的 Spark 运行在这种原生架构下。
PySpark 的运行时结构如下。为了不破坏 Spark 已有的运行时架构,Spark 在外围包装一层 Python API ,借助 Py4j 实现 Python 和 Java 的交互,进而实现通过 Python 编写 Spark 应用程序。
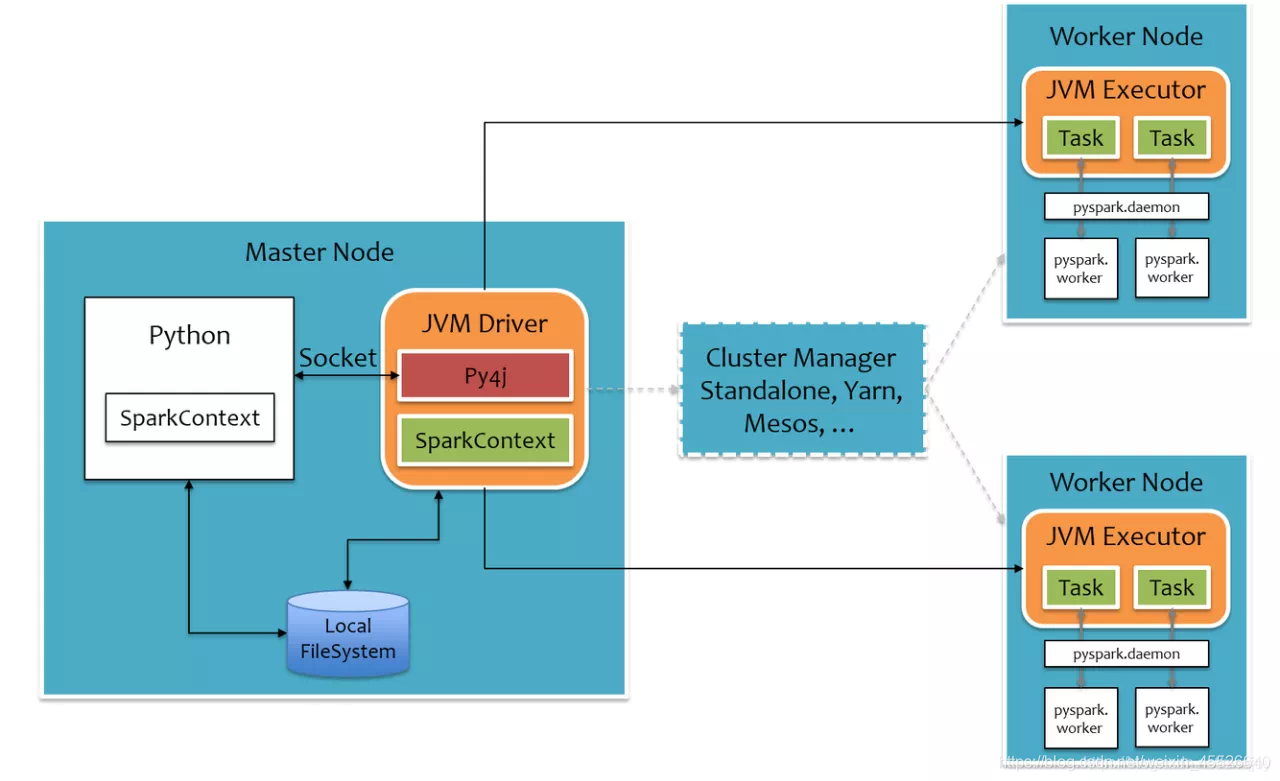
由此可以得知, PySpark 在性能上弱于 Spark-Scala ,主要原因有两点:
-
第一点, Driver 端多了一层 Python 到 Java 的转换;
-
第二点, Executor 端为了运行用户定义的 Python 函数或 Lambda 表达式,为每个 Task 单独启一个 Python 进程,通过 socket 通信方式将 Python 函数或 Lambda 表达式发给 Python 进程执行。
再对比下 Tensorflow for Python 和 Tensorflow for Java 的差异。两者底层都是 Tensorflow 的 C++ 函数库,性能上差异不大。上层来说 Java 语言会比 Python 更快些,对于调用 Tensorflow API 之前需要做许多预处理操作的场景会体现出差异。
综上得出结论,方案二在性能上优于方案一。
当然,方案一在其他方面也有着其优势,比如开发效率高、集成难度低(无需跨平台)、 API 支持度高等等。
2.4 小节
本节内容总结:
-
基于 Spark 大数据框架和 Tensorflow 机器学习框架结合,实现分布式机器学习预测,是一种相对可行、有效的方案。
-
基于 Tensorflow for Java 和 Spark-Scala 实现 Spark和Tensorflow 集成,能带来更高的性能。
-
当前方案适用于大数据下高性能分布式机器学习模型离线预测场景。
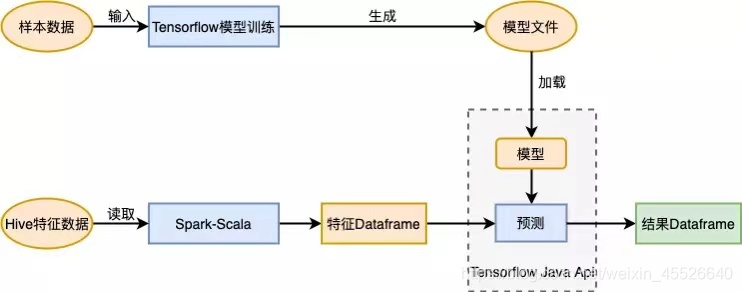
实践中项目应用流程:首先基于样本数据训练好模型,生成模型文件。之后在 Spark 中读取特征数据,调用 Tensorflow Java API 加载模型,进行预测,得到结果集。
3.1 训练模型
3.1.1 训练模型文件
在我们的项目中模型训练基于 Python+Tensorflow+Keras 实现。这里以 MNIST 数据集 CNN 分类为例演示模型训练代码。经过训练后得到了保存为 protobuf 格式的模型文件, protobuf 格式文件可以跨平台加载出模型。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Dropout,Convolution2D,MaxPooling2D,Flatten
from tensorflow.keras.optimizers import Adam
def train_model():
载入训练集和测试集数据,进行独热编码
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
y_train = tf.keras.utils.to_categorical(y_train,num_classes=10)
y_test = tf.keras.utils.to_categorical(y_test,num_classes=10)
定义顺序模型
model = Sequential()
卷积层、池化层、扁平化、全连接
model.add(Convolution2D(input_shape=(28, 28, 1), filters=32, kernel_size=5, strides=1, padding=‘same’, activation=‘relu’))
model.add(MaxPooling2D(pool_size=2, strides=2, padding = ‘same’))
model.add(Convolution2D(64, 5, strides=1, padding=‘same’, activation=‘relu’))
model.add(MaxPooling2D(2,2,‘same’))
model.add(Flatten())
model.add(Dense(1024,activation = ‘relu’))
model.add(Dropout(0.5))
model.add(Dense(10,activation=‘softmax’))
定义优化器,loss function,训练过程中计算准确率
adam = Adam(lr=1e-4)
model.compile(optimizer=adam,loss=‘categorical_crossentropy’,metrics=[‘accuracy’])
训练模型
model.fit(x_train,y_train,batch_size=64,epochs=10,validation_data=(x_test, y_test))
保存模型
model.save(‘./model/model_v1’, save_format=“tf”)
3.1.2 查看模型文件
进入模型文件目录,执行以下命令,可以展示模型文件信息。圈红的信息由上到下依次为模型的标签,签名,输入张量,输出张量,预测方法名。在之后加载模型预测时会用到这些信息。
saved_model_cli show --dir ./model_v1/ --all

3.2 模型预测
3.2.1 工程搭建&框架引入
新建 Scala 工程,引入 Spark 和 Tensorflow 依赖
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_${spark.scala.version}
${spark.version}
org.apache.spark
spark-hive_${spark.scala.version}
${spark.version}
org.apache.spark
spark-sql_${spark.scala.version}
${spark.version}
org.tensorflow
tensorflow
1.15.0
3.2.2 模型文件加载
调用 Tensorflow API 加载预训练好的 protobuff 格式模型文件,得到 SavedModelBundle 类型模型对象。模型文件我们可以保存在工程 resource 目录下,再从 resource 目录加载( Tensorflow 不支持直接从 HDFS 记载模型,后文会介绍如何实现)。
package com.tfspark
import org.apache.spark.sql.SparkSession
import org.tensorflow.SavedModelBundle
import org.{tensorflow => tf}
object ModelLoader {
//modelPath是模型在resource下路径,modelTag从模型文件信息中获取
def loadModelFromLocal(spark: SparkSession, modelPath: String, modelTag: String): SavedModelBundle = {
val bundle = tf.SavedModelBundle.load(modelPath, modelTag)
}
}
3.2.3 调用Tensorflow API 预测
在 Java 版本的 Tensorflow 中还是类似 Tensorflow1.0 中静态计算图的模式,需要建立 session ,指定 feed 的特征数据和 fetch 的预测结果,然后执行 run 方法。
查看模型文件获取的信息将在这里作为参数传入。
package com.tfspark.tensorflow
import com.qunar.rdc.util.TfUtil
import org.tensorflow.SavedModelBundle
import scala.collection.mutable.WrappedArray
import org.{tensorflow => tf}
object TensorFlowCnnProcessor {
def predict(broads: SavedModelBundle, features: WrappedArray[WrappedArray[WrappedArray[Float]]]): Int = {
val sess = bundle.session()
// 特征数据格式化
val x = tf.Tensor.create(Array(features.map(a => a.map(b => b.toArray).toArray).toArray))
// 执行预测 需要传入模型信息里的输入张量名和输出张量名,以及格式化后的特征数据
val y = sess.runner().feed(“serving_default_hmc_input:0”, x).fetch(“StatefulPartitionedCall:0”).run().get(0)
// 结果是1x2的二维数组
val result = Array.ofDimFloat
y.copyTo(result)
// 返回最大值坐标,即为分类结果,对应的是one-hot编码
TfUtil.argMaxOneDim(result(0))
}
}
3.2.4 Spark 结合 Tensorflow 预测
Spark 从 Hive 读取预测数据,经过预处理转换成特征数据,调用 Tensorflow API 预测。通过 Tensorflow API 与 Spark 分布式数据集结合使用,实现分布式批处理框架和机器学习的集成。
// 将封装Tensorflow API的预测方法注册为udf函数
val sensorPredict = udf((features: WrappedArray[WrappedArray[WrappedArray[Float]]]) => {predict(bundle, features)})
// Dataframe调udf函数
val resultDf = featureDf.withColumn(“predict_result”, sensorPredict(col(“feature”))
3.3 服务部署
3.3.1 环境依赖
将 Spark-Scala 和 Tensorflow for Java 集成后的工程,通过 maven 打出依赖包:tfspark-1.0.0-jar-with-dependencies.jar 。
在部署了 spark 运行环境的 hadoop 集群上运行 jar 包。依赖的集群环境需提前安装 spark、hadoop、hive 等大数据组件。
3.3.2 执行脚本
spark-submit 执行 jar 包,指定执行的 main 函数类 com.tfspark.PredictMain ,指定 jar 包路径,设置执行任务的 executor 数和核心数以及内存参数,传入模型文件版本参数。
sudo -u root /usr/local/Cellar/apache-spark/2.4.3/bin/spark-submit --class com.tfspark.PredictMain --master yarn --deploy-mode client --driver-memory 6g --executor-memory 6g --num-executors 5 --executor-cores 4 /tmp/tfspark-1.0.0-jar-with-dependencies.jar model_v1
最后如何让自己一步步成为技术专家
说句实话,如果一个打工人不想提升自己,那便没有工作的意义,毕竟大家也没有到养老的年龄。
当你的技术在一步步贴近阿里p7水平的时候,毫无疑问你的薪资肯定会涨,同时你能学到更多更深的技术,交结到更厉害的大牛。
推荐一份Java架构之路必备的学习笔记,内容相当全面!!!

成年人的世界没有容易二字,前段时间刷抖音看到一个程序员连着加班两星期到半夜2点的视频。在这个行业若想要拿高薪除了提高硬实力别无他法。
你知道吗?现在有的应届生实习薪资都已经赶超开发5年的程序员了,实习薪资26K,30K,你没有紧迫感吗?做了这么多年还不如一个应届生,真的非常尴尬!
进了这个行业就不要把没时间学习当借口,这个行业就是要不断学习,不然就只能被裁员。所以,抓紧时间投资自己,多学点技术,眼前困难,往后轻松!
【关注】+【转发】+【点赞】支持我!创作不易!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
的应届生实习薪资都已经赶超开发5年的程序员了,实习薪资26K,30K,你没有紧迫感吗?做了这么多年还不如一个应届生,真的非常尴尬!
进了这个行业就不要把没时间学习当借口,这个行业就是要不断学习,不然就只能被裁员。所以,抓紧时间投资自己,多学点技术,眼前困难,往后轻松!
【关注】+【转发】+【点赞】支持我!创作不易!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-86OWsBoC-1713655685888)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf