unordered_map, hash_map, map 区别_hashmap和unorderedmap区别-程序员宅基地
技术标签: 数据结构
1. unordered_map, hash_map, map 概述
C++中,map(来自于 STL) ,底层实现采用红黑树。
hash_map(有很多种实现,底层实现均采用hashtable。目前普遍使用的来自 SGI 的 STL),还未成为C++标准,不过,在可预见的将来,会成为C++标准。
unordered_map 实现来自于 boost 库,底层实现也是hashtable。
2. hash_map的实现
map的实现我们在此不表,谈谈hash_map的实现,本文中以SGI的hash_map为例子进行说明
(1)hash_map原理
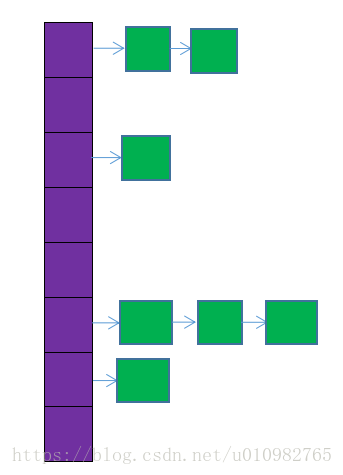
hash_map使用hash table来实现,首先分配内存,形成许多bucket用来存放元素,然后利用hash函数,对元素的key进行映射,存放到对应的bucket内。这其中hash函数用于定址,额外的比较函数用于解决冲突。该过程可以描述为:
a.计算元素的key
b.通过hash函数对key进行映射(常见的为取模),得到hash值,即为对应的bucket索引
c.存放元素的key和data在bucket内。
对应的查询过程是:
a.计算元素的key
b.通过hash函数对key进行映射(常见的为取模),得到hash值,即为对应的bucket索引
c.比较bucket内元素的key’与该key相等,若不相等则没有找到。
d.若相等则取出该元素的data。
所以实现hash_map最重要的两个东西就是hash函数和比较函数。以下以SGI的hash_map为例子进行说明。
(2)hash_map类定义
map构造时只需要比较函数(小于函数),hash_map构造时需要定义hash函数和比较函数(等于函数)。SGI中hash_map定义于stl_hash_map.h,定义为:
// Forward declaration of equality operator; needed for friend declaration.
template <class _Key, class _Tp,
class _HashFcn __STL_DEPENDENT_DEFAULT_TMPL(hash<_Key>),
class _EqualKey __STL_DEPENDENT_DEFAULT_TMPL(equal_to<_Key>),
class _Alloc = __STL_DEFAULT_ALLOCATOR(_Tp) >
class hash_map;
......
template <class _Key, class _Tp, class _HashFcn, class _EqualKey,
class _Alloc>
class hash_map
{
......
} 其中,参数1和参数2分别为键和值,参数3和参数4分别为hash函数和比较函数,实际上STL中使用结构体来封装这两个函数,用户可以自定义这两个结构体,也可以采用提供的默认值。参数5是hash_map的allocator,用于内部内存管理。
3. 三者区别杂记
为啥hash_map如此消耗我们的内存
使用过hash_map,hash_set的都知道,他们耗内存很严重,比如1个1亿{key(8B),value(8B)}的hash_map,理论计算内存为0.1G*(8+8)=1.6G,但实际内存却要4G(64位机),1.6G vs 4G,坑爹啊!!!hash_set内存消耗也一样需要4G,而理论上只需要0.1G*8=800M。它都拿去干嘛了?
[Node*(8B)] -> [Node(nB)] -> [Node(nB)] ......
......
......
[Node*(8B)] -> [Node(nB)] -> [Node(nB)] ......
hash_map实现简图如上。它使用hash_table实现,需要维护一个hash桶 ,桶里面存一个Node*指针(8B),为了性能考虑,这个桶的size被限定在>=节点数。也就是说1个1亿key的hash_map,桶就要大于1亿。Node*指向一个节点链表,hash到同一key的节点都挂载这个链表后面。每来一个新的key就new一个Node。Node里面存的是{key(8B), value(8B), Node*(8B)}。这样算下来内存应该是0.1G*(8B+8B+8B+8B)=3.2G。那么为啥还不到4G呢?
很不幸,linux每new一块内存,都要在头部用8B来记录后面new的buffer长度。而且,new的buffer最少要大于等于32B,且为16B的整数倍!也就是说如果你new一个1B的char,那么内存也得要32B(实际测试是33B)!于是内存就应该是0.1G*(8B+32B)=4.0G。
对于hash_set,Node是{key(8B), Node*(8B)},这同样要耗32B。因而内存消耗同样是0.1G*(8B+32B)=4.0G。这就是为啥hash_set居然跟hash_map耗内存一样的原因(前提是key,value加在一起小于16B)。
unordered_map的初始化比较耗时,我们都知道map是红黑树,unordered_map是哈希表,造成性能差异的原因在于,红黑树初始化时,节点只需要一个,后续的插入只是插入新的节点,但是哈希表初始化时就不是那么简单了,哈希表初始化时需要申请一个数组,数组的每个元素都指向一条链表,所以初始化时需要申请很多内存,相比于map,的确更耗时。
相对于平衡树,hashtable的优点:
插入,查找,删除复杂度为常数时间,大规模查询时,性能差距更为明显。
其实相比于hash,平衡树也是有优点的:
1. 尽管我们都说hash查找插入删除复杂度是常数时间,但这仅仅是个统计上的概念,最差情况下,也是会达到O(n),而红黑树,最差的情况下也是O(logn)
2.hash实际上是空间换时间的做法,空间越小,操作的时间复杂度越大,操作时间越不稳定,而平衡树则稳定很多
3.还有一个就是序,红黑树是查找树,因此中序遍历的结果就是排好序的。这就使得其在范围查找方面性能优秀,而hash却需要遍历全部数据,之后统计才能得出范围查找的结果。另外,如果你知道一个元素在树中的位置,和它大小相近的元素也在它周围,这就使得获取相近元素的时间很少。另外,我们知道,中序遍历的时间复杂度也只是O(n),这个性质非常有用。
至于unordered_map,原理和hash_map类似,但其在某些方面做了优化,性能好于hash_map,所以,业界有一个建议,如果不是为了有序,尽量使用unordered_map。
智能推荐
解决electron+vue项目起始加载慢的问题_electron vue项目打开慢-程序员宅基地
文章浏览阅读461次。_electron vue项目打开慢
linux下编译GDAL外加扩展格式支持(五)--完-程序员宅基地
文章浏览阅读229次。接1、2、3、4篇。10、安装mysql支持安装fedora15或者16系统时若选择安装mysql数据库,则必须自行安装mysql开发包。因为自带默认数据库不会安装这个包。否则会遇到mysql错误:ogr_mysql.h:34:23: fatal error: my_global.h: No such file or directory#问题原因:找不到mysql头文件..._linux gdal netcdf5
Linux tc qdisc 模拟网络丢包延时-程序员宅基地
文章浏览阅读1.2k次。Linux tc qdisc 模拟网络丢包延时_tc qdisc
linux64bit 安装 jdk 1.7-程序员宅基地
文章浏览阅读336次。linux64bit 安装 jdk 1.7下载地址 : https://edelivery.oracle.com/otn-pub/java/jdk/7u21-b11/jdk-7u21-linux-x64.rpm0. 卸载rpm版的jdk: #rpm -qa|grep jdk 显示:jdk-1.6.0_10-fcs 卸载:#rpm -e --nodep..._liunx64位得jdk1.7
【Linux笔记】-----Nginx/LVS/HAProxy负载均衡的优缺点_中间件应用场景nginx lvs proxy-程序员宅基地
文章浏览阅读552次。开始听到负载均衡的时候,我第一反应想到的是链路负载均衡,在此之前主要是在学习网络方面知识,像在NA、NP阶段实验做链路负载均衡时常会遇到,后来还接触到SLB负载分担技术,这都是在链路基础上实现的。 其实负载均衡可以分为硬件实现负载均衡和软件实现负载均衡。 硬件实现负载均衡:常见F5和Array负载均衡器,配套专业维护服务,但是成本昂贵。 软件实现负载均衡:常见开源免费的负载均衡软件有Ngin..._中间件应用场景nginx lvs proxy
多维时序 | MATLAB实现CNN-LSTM多变量时序预测_cnn可以进行多步预测-程序员宅基地
文章浏览阅读4.7k次。多维时序 | MATLAB实现CNN-LSTM多变量时序预测目录多维时序 | MATLAB实现CNN-LSTM多变量多步预测基本介绍模型特点程序设计学习总结参考资料基本介绍本次运行测试环境MATLAB2020b,MATLAB实现CNN-LSTM多变量多步预测。模型特点深度学习使用分布式的分层特征表示方法自动提取数据中的从最低层到最高层固有的抽象特征和隐藏不变结构. 为了充分利用单个模型的优点并提高预测性能, 现已提出了许多组合模型。CNN 是多层前馈神经网络, 已被证明在提取隐藏_cnn可以进行多步预测
随便推点
【9.3】用户和组的管理、密码_polkitd:input 用户和组-程序员宅基地
文章浏览阅读219次。3.1 用户配置文件和密码配置文件3.2 用户组管理3.3 用户管理3.4 usermod命令3.5 用户密码管理3.6 mkpasswd命令_polkitd:input 用户和组
pca算法python代码_三种方法实现PCA算法(Python)-程序员宅基地
文章浏览阅读670次。主成分分析,即Principal Component Analysis(PCA),是多元统计中的重要内容,也广泛应用于机器学习和其它领域。它的主要作用是对高维数据进行降维。PCA把原先的n个特征用数目更少的k个特征取代,新特征是旧特征的线性组合,这些线性组合最大化样本方差,尽量使新的k个特征互不相关。关于PCA的更多介绍,请参考:https://en.wikipedia.org/wiki/Prin..._inprementation python code of pca
内存地址Linux下内存分配与映射之一-程序员宅基地
文章浏览阅读35次。发一下牢骚和主题无关:地址类型:32位的cpu,共4G间空,其中0-3G属于用户间空地址,3G-4G是内核间空地址。用户虚拟地址:用户间空程序的地址物理地址:cpu与内存之间的用使地址总线地址:外围总线和内存之间的用使地址内核逻辑地址:内存的分部或全体射映,大多数情况下,它与物理地址仅差一个偏移量。如Kmalloc分..._linux 内存条与内存地址
自动化测试介绍_自动化测试中baw库指的什么-程序员宅基地
文章浏览阅读1.3k次,点赞2次,收藏16次。什么是自动化测试? 做测试好几年了,真正学习和实践自动化测试一年,自我感觉这一个年中收获许多。一直想动笔写一篇文章分享自动化测试实践中的一些经验。终于决定花点时间来做这件事儿。 首先理清自动化测试的概念,广义上来讲,自动化包括一切通过工具(程序)的方式来代替或辅助手工测试的行为都可以看做自动化,包括性能测试工具(loadrunner、jmeter),或自己所写的一段程序,用于_自动化测试中baw库指的什么
a0图框标题栏尺寸_a0图纸尺寸(a0图纸标题栏尺寸标准国标)-程序员宅基地
文章浏览阅读1.6w次。A0纸指的是一平方米大小的白银比例长方形纸(长为1189mm宽为841mm)。A0=1189mm*841mm A1=841mm*594mm 相当于1/2张A0纸 A2=594mm*420mm 相当于1/4.A1图纸大小尺寸:841mm*594mm 即长为841mm,宽为594mm 过去是以多少"开"(例如8开或16开等)来表示纸张的大小,我国采用国际标准,规定以 A0、A1、A2、.GB/T 14..._a0图纸尺寸
TreeTable的简单实现_treetable canvas-程序员宅基地
文章浏览阅读966次。最终效果图:UI说明:针对table本身进行增强的tree table组件。 tree的数据来源是单元格内a元素的自定义属性:level和type。具体代码如下:Java代码 DepartmentEmployeeIDposi_treetable canvas