Android Studio 混淆_android studio 开启混淆-程序员宅基地
本文介绍了Android中开启混淆的好处,混淆的工作原理及如何解决开启混淆后遇到的问题。
原文链接:Troubleshooting ProGuard issues on Android
《行路难》
金樽清酒斗十千,玉盘珍馐直万钱。
停杯投箸不能食,拔剑四顾心茫然。
欲渡黄河冰塞川,将登太行雪满山。
闲来垂钓坐溪上,忽复乘舟梦日边。
行路难,行路难,多歧路,今安在。
长风破浪会有时,直挂云帆济沧海。
—唐,李白
为什么混淆
混淆器(ProGuard)是一个压缩、优化和混淆代码的工具。当然开发者也可以使用其它工具,混淆器作为 Android Gradle 构建处理的一部分并且附带在SDK中可以很方便使用。
你开发的应用想要开启混淆的原因可能有多种。有些开发者可能关心混淆了多少代码,但对我来说最大的好处是可以删除所有未使用的代码,否则会作为 classes.dex 文件的一部分打包到 APK 中。

图 Android 应用大小分布饼图的示例。数据来源:Topeka sample app。
让你的代码大小更小可以带来很多实际好处,例如,提高用户留存率和满意度,更快的下载和安装时间,安装在用户的低端设备上,尤其是新兴市场。还有一些情况,当你需要限制应用的大小,例如 4MB limit for Instant Apps,这种情况下混淆肯定是必不可少的。
如果这对你还不够方便,考虑移除未使用的代码并且混淆所有的名称会有不错的效果,还可以开启更多优化:
- 在一些 Android 版本上,DEX 代码会在安装时或运行时编译成机器码。原始的 DEX 和优化后的代码会一直保留在设备上,因此这是个很简单的数学问题,更少的代码代表在设备上更短的编译时间和更少的存储使用。
- 混淆可以做的另一个事情是,在代码大小上有很大的影响,它会修改所有的标识符(包名,类名和成员变量)为短名称,例如 a.A 和 a.a.B。这个处理是众所周知的混淆。混淆通过两种方式减少代码大小:代表实际字符串的这些名称更短,此外如果它们共享了相同的签名,它们有更高的可能性被不同的方法和域重用,这会减少字符串池中 item 的总数量。
- 使用混淆器需要开启资源压缩。资源压缩会移除在你的工程中没有使用代码引用的资源(例如图片,通常是APK中占比最大的一部分)。
- 移除代码也可以帮你避免 dex 64k 方法数限制问题。通过只打包代码中实际使用的方法到APK中,尤其是当你考虑做第三方类库时,你可以在应用中减少使用 Multidex 的需要。
你觉得每个应用都应该开启代码压缩么?是的!
开始使用之前,先学习下开启混淆后可能遇到的一些问题。构建应用时可能会出现一些错误,还有只能在运行时才能捕获到的错误,因此需要彻底测试你的应用。
怎样混淆
在应用 module 的 build.gradle 文件中添加如下代码:
buildTypes {
/* you will normally want to enable ProGuard only for your release builds, as it’s an additional step that makes the build slower and can make debugging more difficult */
release {
minifyEnabled true
proguardFiles getDefaultProguardFile(‘proguard-android.txt’), ‘proguard-rules.pro’
}
}
通过分别指定配置文件完成混淆配置。通过上面的代码可以看到我添加了 android gradle 插件提供的默认配置,并且在 proguard-rules.pro 文件中添加了一些工程相关的配置。在官网上你可以找到可手动配置的所有选项。在你深入研究配置选项之前,最好先理解混淆是怎样工作的以及我们为什么需要指定额外的选项。

图 你也可以观看 Google I/O 大会上 Shai Barack’s 解释。
简而言之,混淆器会将工程中的类文件作为输入,搜索应用入口点的所有可能性并且从这些入口点计算出所有代码可达性的地图,然后移除剩下的代码(无用代码,或永远不会运行的代码,因为它从未被调用)。
阅读混淆手册的时候,应当跳过输入/输出部分,Android gradle 插件会为你指定输入(你的类文件)和类库 jar 包。
正确的配置混淆的部分是让它知道哪一部分代码是在运行时访问并且不应该被移除(当混淆打开后它们的名字会保持原样)。当类或方法是通过动态访问(使用反射),混淆器在构建被使用的代码的地图时有时并不知道这些代码是否被使用并且会错误地将这些类移除。这也会发生在只从xml资源中引用代码时(通常在底层使用反射的方式)。
在 android 构建期间,AAPT(处理资源的工具)会生成一个额外的混淆规则文件。它为 android 应用的入口点添加显式 keep 规则,因此清单文件中所有的 Activities,Services,BroadcastReceivers 和 ContentProviders 会保持原样。这就是上面的动画中 MyActivity 类没有被移除或重命名的原因。
AAPT 也会 keep 所有在 xml 布局中使用的 Views(以及它们的构造方法)和一些其它类,例如在动画过渡资源中引用的过渡类。你可以在执行构建之后检查 AAPT 生成的配置文件,通过打开 <your_project>/<app_module>/build/intermediates/proguard-rules/<variant>/aapt_rules.txt 文件:

图 构建期间 AAPT 创建的混淆配置示例
在后面的部分我们会讲到 keep 规则,在此之前我们最好先学习下它做了些什么。
当开启混淆后导致构建失败
测试应用开启混淆后是否可以正常工作之前,应该先构建应用。当混淆检查出你的代码有问题,它会在编译时发出警告并导致构建失败,例如引用不存在的类。
解决构建失败的关键在于查看构建输出的日志,理解警告是关于什么的及它们的地址,通常通过修复依赖或在混淆配置中添加 -dontwarn 规则解决。
警告出现的其中一个原因是利用 JARs 包编译的依赖但没有添加到编译路径,例如,当使用 provided(只在编译时使用)依赖。有时候,使用这些依赖的代码路径在 Android 上运行类库代码时不是实际被调用的。我们来看一个真实的例子。
关于构建依赖的详细说明请查看 Gradle 构建依赖配置说明。
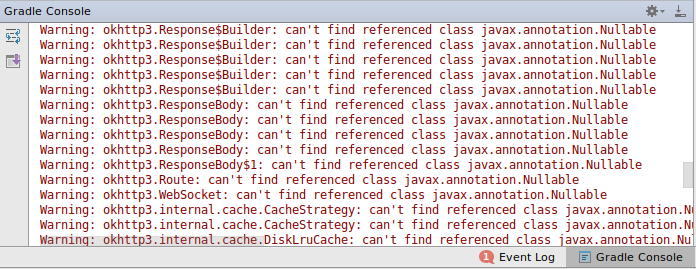
图 构建依赖 OkHttp 3.8.0 工程的警告输出
OkHttp 类库的3.8.0版本在类上添加了新的注解 (javax.annotation.Nullable),因为它们使用了编译时依赖,注解本身不会打包到依赖 OkHttp 的应用(除非应用显式地添加了com.google.code.findbugs:jsr305)并且混淆器会输出找不到的类信息。
因为我们知道这些注解类在运行时不会被使用,我们可以在混淆配置中添加 -dontwarn 规则安全地忽略警告,正如 OkHttp 所建议的那样:
-dontwarn javax.annotation.Nullable
-dontwarn javax.annotation.ParametersAreNonnullByDefault
你应该对所有的警告做同样的处理,然后重新构建直到构建成功。重要的是应该理解为什么会出现这些警告,忽略它可能是安全的,也有可能在构建时真的丢失了一些类。
现在你可能会尝试使用 ignorewarnings 选项忽略所有的警告,但这并不是一个好主意。在某些情况下,混淆警告会让你了解让应用无法正常工作的错误,和你配置的其它问题。
你也有可能会想要查看混淆日志,可以突出显示通过反射访问的类的问题。如果没有导致构建失败,这些会导致令人讨厌的运行时漰溃。
当混淆移除了有用的代码
在某些情况下,混淆不知道一个类或方法是否被使用,例如它只被反射或从 XML 中引用。为了不让类被混淆或被移除,需要在混淆配置中指定额外 keep 规则。这需要你处理有问题的代码并添加必要的规则。
在运行时得到 ClassNotFoundException 或 MethodNotFoundException 错误表示丢失了类或方法,可能由于混淆移除了类或由于错误的依赖配置导致。测试应用的 release 构建(开启混淆)并处理这些错误是很重要的。
这有几个不同的 keep 选项,你可以用于配置混淆:
- keep——保留所有匹配类规范的类和方法
- keepclassmembers——指定被保留的成员,但前提是它们的父类由于某些原因(从入口点是可达的或被别的规则保留)被保留
- keepclasseswithmembers——会保留类及它的成员,但前提是在类规范列出的所有成员
我建议你好好看看类规范语法,用于上面提到的所有 keep 规则以及前面部分提到的 -dontwarn 选项。这三条 keep 规则只会阻止混淆(重命名),不会阻止压缩。你可以在混淆网站上找到在一个表格中所有 keep 选项的概览。
另一个代替编写复杂混淆规则的方法,只需要在不想要被混淆器移除或重命名的类/方法/域上添加 @Keep 注解。使用这个方法需要添加默认的Android混淆配置文件。
APK分析器和混淆
Android Studio 中的 APK 分析器可以帮助你看到被混淆器移除的类以及为它们生成 keep 规则。当你开启混淆构建 APK,会生成一个额外的输出文件 <app_module>/build/outputs/mapping/,包含移除代码的信息及混淆后的名称和原始名称之间的映射。
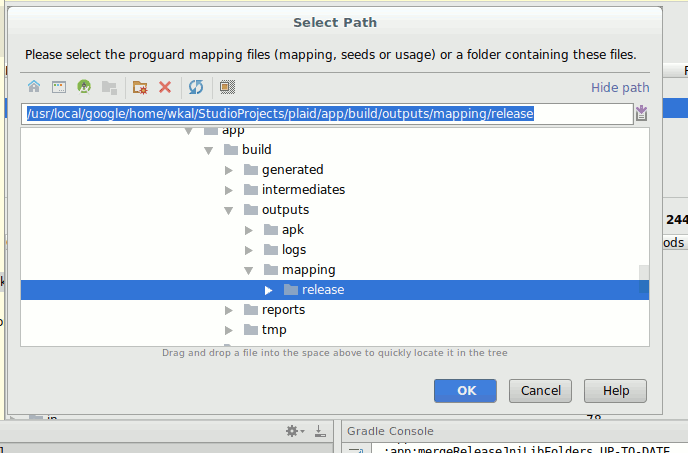
图 在 DEX 查看器中解锁更多信息通过在 APK 分析器中加载混淆映射文件
注:此功能在Android Studio 3.0版本可用。
当你加载映射文件到 APK 分析器中(使用 “Load Proguard mappings… ” 按钮),会在 DEX 树视图中得到一些额外功能:
- 所有的名称被反混淆(你可以看到原始名称)
- 被混淆配置规则保留的包、类、方法和域被加粗显示
- 你可以使用 “Show removed nodes” 选项看到被混淆移除的类(加删除线显示)。在树的节点上右击可以生成 keep 规则,你可以粘贴到混淆配置文件中。
当混淆移除的太少
Android 混淆规则对每个 Android 应用包含了一些安全的默认值,例如确保 View 的 getters 和 setters——可以通过反射正常访问,以及更多常见方法和类不会被移除。这会保证你的应用在很多情况下不会漰溃,这个配置对你的应用来说可能不是最理想的。你可以移除默认的混淆文件使用你自己的。
如果你想使用混淆移除所有未使用的代码,你应该避免 keep 规则太广泛,例如使用通配符匹配整个包。应该选择类规范规则或者使用之前提到的 @Keep 注解。

图 使用 -whyareyoukeeping 选项查看为什么类没有被移除
如果你不确定混淆为什么没有移除你期望移除的代码部分,你可以在混淆配置文件中添加 -whyareyoukeeping 选项,然后再次构建 APK。在构建输出中,你可以看到让混淆器决定保留代码的引用链。
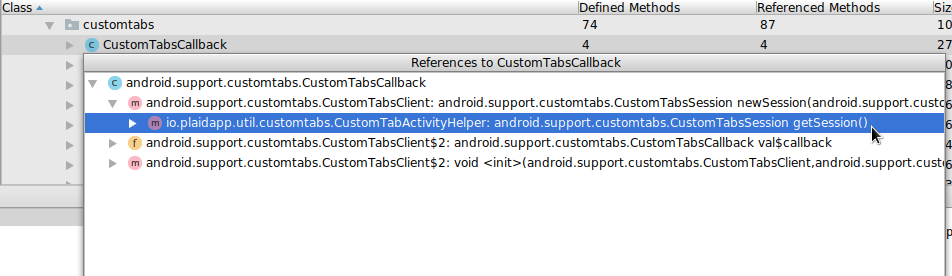
图 在 APK 分析器中查看类和方法的引用追踪代码被 keep 的原因
还有一种不精确的方法,但不需要重新构建可以应用在任何 APK 上,在 APK 分析器中打开 DEX 文件,在你感兴趣的类或方法上右击。选择 “Find usages” 查看引用链,可以看到哪一部分代码使用了给定的类或方法,因此它没有被移除。
混淆器和混淆堆栈跟踪
之前提到混淆器会在构建期间处理类文件时输出 mappings 和 logs。当你存储构建结果时应该和 APK 一起保存这些文件。映射文件不能用于不同构建之间并且和产生的 APK 一起才能正常工作。mappings 文件可以帮助你调试用户设备上的漰溃,否则由于被混淆的名称很难解决漰溃。
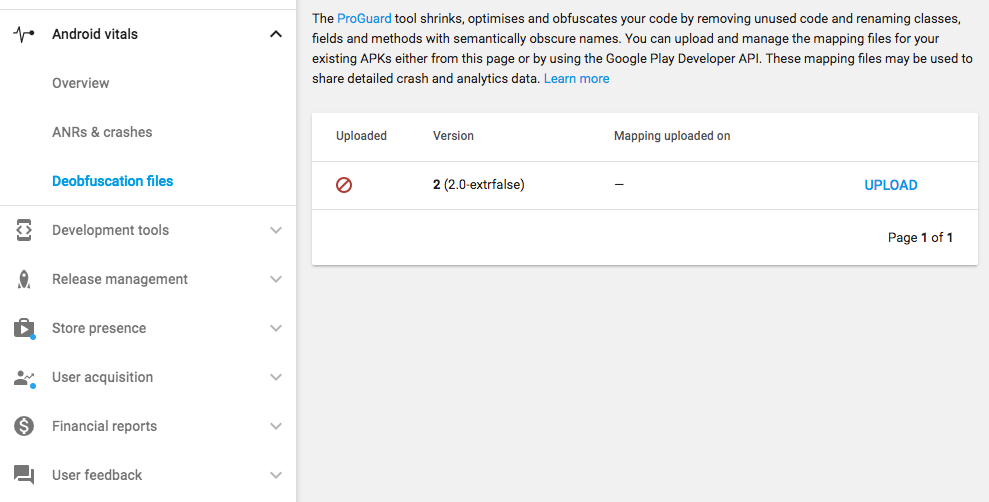
图 上传混淆 mapping 文件和 APK 到 Google Play 控制台得到反混淆堆栈跟踪
当你在 Play 控制台发布混淆后的 APK 记得为每个版本上传 mapping 文件。这样的话当你查看 ANRs & crashes 页面,报告的堆栈跟踪会显示真实的类和方法名和行号,而不是被混淆后的名称。
混淆和第三方类库
为你自己的代码提供 keep 规则是你的职责所在,第三方类库的创建者的职责是为你提供必须的配置,因此当你开启混淆后构建不会失败或应用不会漰溃。
一些工程在手册或 README 文件中简单地提到必须的规则,因此你可以复制和粘贴到你的混淆文件中。但这有一个更好的方法。对于类库 modules 和类库发布的 AARs,类库的维护者可以为 AAR 提供指定的规则并自动暴露给类库使用者的构建系统,通过在 build.gradle 文件中添加下面的代码:
release { //or your own build type
consumerProguardFiles ‘consumer-proguard.txt’
}
在 consumer-proguard.txt 文件中添加的规则会被追加到主混淆配置并且在应用构建时被使用。
关于代码和资源压缩的详细信息请参考我们的文档。
起初开启混淆可能会让人觉得有点可怕,但我个人认为它的好处是有价值的,并且只需要花一点点时间,就可以得到更小更优化的应用。更重要的是,现在花时间配置你的应用意味着已经做好了引入叫做 R8 的混淆替换实验的准备,它将会和现有混淆规则文件一起工作。
除了让你的代码更少,混淆和 R8 可以优化代码让它运行的更快,但这是另一篇文章的主题。
注:ProGuard-android.txt 文件之前可以从 Sdk 文件夹中找到(Sdk/tools/ProGuard/ProGuard-android.txt),但在SDK的新版本和 Android Gradle plugin 2.2.0+,它会在构建期间从 Android 插件 jar 包中解压。你可以在构建之后在 <your_project>/build/intermediates/ProGuard-files/ 找到配置文件。
智能推荐
FX3/CX3 JLINK 调试_ezusbsuite_qsg.pdf-程序员宅基地
文章浏览阅读2.1k次。FX3 JLINK调试是一个有些麻烦的事情,经常有些莫名其妙的问题。 设置参见 c:\Program Files (x86)\Cypress\EZ-USB FX3 SDK\1.3\doc\firmware 下的 EzUsbSuite_UG.pdf 文档。 常见问题: 1.装了多个版本的jlink,使用了未注册或不适当的版本 选择一个正确的版本。JLinkARM_V408l,JLinkA_ezusbsuite_qsg.pdf
用openGL+QT简单实现二进制stl文件读取显示并通过鼠标旋转缩放_qopengl如何鼠标控制旋转-程序员宅基地
文章浏览阅读2.6k次。** 本文仅通过用openGL+QT简单实现二进制stl文件读取显示并通过鼠标旋转缩放, 是比较入门的级别,由于个人能力有限,新手级别,所以未能施加光影灯光等操作, 未能让显示的stl文件更加真实。****效果图:**1. main.cpp```cpp#include "widget.h"#include <QApplication>int main(int argc, char *argv[]){ QApplication a(argc, argv); _qopengl如何鼠标控制旋转
刘焕勇&王昊奋|ChatGPT对知识图谱的影响讨论实录-程序员宅基地
文章浏览阅读943次,点赞22次,收藏19次。以大规模预训练语言模型为基础的chatgpt成功出圈,在近几日已经给人工智能板块带来了多次涨停,这足够说明这一风口的到来。而作为曾经的风口“知识图谱”而言,如何找到其与chatgpt之间的区别,找好自身的定位显得尤为重要。形式化知识和参数化知识在表现形式上一直都是大家考虑的问题,两种技术都应该有自己的定位与价值所在。知识图谱构建往往是抽取式的,而且往往包含一系列知识冲突检测、消解过程,整个过程都能溯源。以这样的知识作为输入,能在相当程度上解决当前ChatGPT的事实谬误问题,并具有可解释性。
如何实现tomcat的热部署_tomcat热部署-程序员宅基地
文章浏览阅读1.3k次。最重要的一点,一定是degbug的方式启动,不然热部署不会生效,注意,注意!_tomcat热部署
用HTML5做一个个人网站,此文仅展示个人主页界面。内附源代码下载地址_个人主页源码-程序员宅基地
文章浏览阅读10w+次,点赞56次,收藏482次。html5 ,用css去修饰自己的个人主页代码如下:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xh..._个人主页源码
程序员公开上班摸鱼神器!有了它,老板都不好意思打扰你!-程序员宅基地
文章浏览阅读201次。开发者(KaiFaX)面向全栈工程师的开发者专注于前端、Java/Python/Go/PHP的技术社区来源:开源最前线链接:https://github.com/svenstaro/gen..._程序员怎么上班摸鱼
随便推点
UG\NX二次开发 改变Block UI界面的尺寸_ug二次开发 调整 对话框大小-程序员宅基地
文章浏览阅读1.3k次。改变Block UI界面的尺寸_ug二次开发 调整 对话框大小
基于深度学习的股票预测(完整版,有代码)_基于深度学习的股票操纵识别研究python代码-程序员宅基地
文章浏览阅读1.3w次,点赞18次,收藏291次。基于深度学习的股票预测数据获取数据转换LSTM模型搭建训练模型预测结果数据获取采用tushare的数据接口(不知道tushare的筒子们自行百度一下,简而言之其免费提供各类金融数据 , 助力智能投资与创新型投资。)python可以直接使用pip安装tushare!pip install tushareCollecting tushare Downloading https://files.pythonhosted.org/packages/17/76/dc6784a1c07ec040e74_基于深度学习的股票操纵识别研究python代码
中科网威工业级防火墙通过电力行业测评_电力行业防火墙有哪些-程序员宅基地
文章浏览阅读2k次。【IT168 厂商动态】 近日,北京中科网威(NETPOWER)工业级防火墙通过了中国电力工业电力设备及仪表质量检验测试中心(厂站自动化及远动)测试,并成为中国首家通过电力协议访问控制专业测评的工业级防火墙生产厂商。 北京中科网威(NETPOWER)工业级防火墙专为工业及恶劣环境下的网络安全需求而设计,它采用了非X86的高可靠嵌入式处理器并采用无风扇设计,整机功耗不到22W,具备极_电力行业防火墙有哪些
第十三周 ——项目二 “二叉树排序树中查找的路径”-程序员宅基地
文章浏览阅读206次。/*烟台大学计算机学院 作者:董玉祥 完成日期: 2017 12 3 问题描述:二叉树排序树中查找的路径 */#include #include #define MaxSize 100typedef int KeyType; //定义关键字类型typedef char InfoType;typedef struct node
C语言基础 -- scanf函数的返回值及其应用_c语言ignoring return value-程序员宅基地
文章浏览阅读775次。当时老师一定会告诉你,这个一个"warning"的报警,可以不用管它,也确实如此。不过,这条报警信息我们至少可以知道一点,就是scanf函数调用完之后是有一个返回值的,下面我们就要对scanf返回值进行详细的讨论。并给出在编程时利用scanf的返回值可以实现的一些功能。_c语言ignoring return value
数字医疗时代的数据安全如何保障?_数字医疗服务保障方案-程序员宅基地
文章浏览阅读9.6k次。十四五规划下,数据安全成为国家、社会发展面临的重要议题,《数据安全法》《个人信息保护法》《关键信息基础设施安全保护条例》已陆续施行。如何做好“数据安全建设”是数字时代的必答题。_数字医疗服务保障方案