”hive“ 的搜索结果
Apache Hive(TM)数据仓库软件有助于查询和管理驻留在分布式存储中的大型数据集。 它建立在Apache Hadoop(TM)之上,提供*工具,使数据提取/转换/加载(ETL)变得容易*一种将结构强加于各种数据格式的机制*访问...
文章目录Hive安装配置一、Hive安装地址二、Hive安装部署1. 把 `apache-hive-3.1.2-bin.tar.gz`上传到Linux的/export/software目录下2. 解压`apache-hive-3.1.2-bin.tar.gz`到/export/servers/目录下面3. 修改`apache...
Hive基本概念 是一个基于hadoop的数据仓库工具,可以将结构化数据映射成一张数据表,并提供类SQL的查询功能。 Hive的意义是什么 背景:hadoop是个好东西,但是学习难度大,成本高,坡度陡。 意义(目的)...
如果创建表的注释有乱码问题,修改mysql元数据表中COLUMN_V2、TABLE_PARAMS表中对应...在hive313/conf下新建hive-site.xml文件。下载一个mysql的驱动放入hive313/lib下。停止的脚本为stop-hive.sh。访问http://:10002。
总的来说,Hive 通过将数据存储在 HDFS 中,并通过表来组织和管理数据,实现了对大规模数据的高效读写和查询。同时,Hive 还提供了丰富的数据导入导出功能,支持多种文件格式和数据源,满足了不同场景下的数据处理...

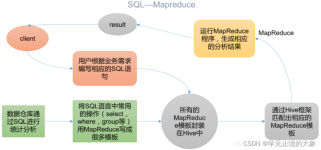
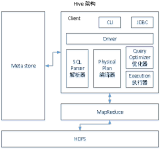
hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为...
TEXTFILE 支持使用Gzip 压缩,但Gzip压缩后的文件将不再支持MapReduce分割机制,这意味着压缩后的文件不论有多少个HDFS块都只能被一个Map任务处理,即失去了使用集群并行处理的优势。SEQUENCEFILE 是Hadoop 提供的一...
Hive安装部署
最详细的Hive讲解,一篇既可以学会hive的相关知识。
hive基础介绍
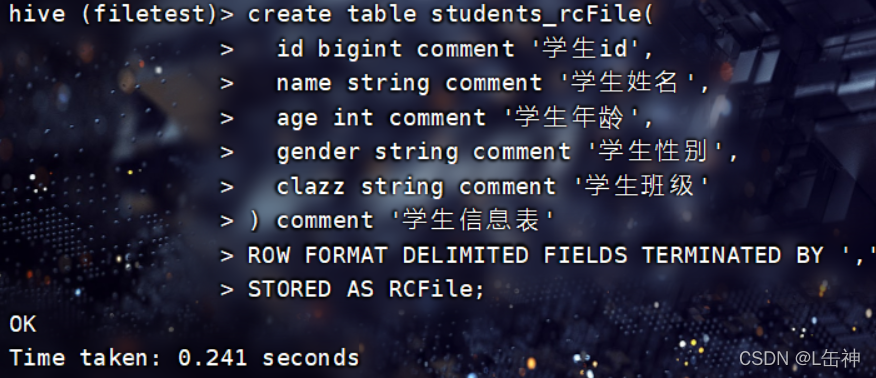
今天写的比较急,先凑活看,有空的话再完善一下
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的...
Hive是一个基于Apache Hadoop的数据仓库。对于数据存储与处理,Hadoop提供了主要的扩展和容错能力。 Hive设计的初衷是:对于大量的数据,使得数据汇总,查询和分析更加简单。它提供了SQL,允许用户更加简单地进行...
Hive 的Hive_x.x.x_bin.tar.gz 高版本在windows 环境中缺少 Hive的执行文件和运行程序。配置文件目录(%HIVE_HOME%\conf)有4个默认的配置文件模板拷贝成新的文件名。可以发现,自动连接MySQL去创建schema hive,并...
在cdh6.3.2已经做好hbase和hive相关配置,这里不阐述。要创建上述的表结构,你需要先在HBase中创建相应的表,然后在Hive中创建一个EXTERNAL TABLE来映射到这个HBase表。
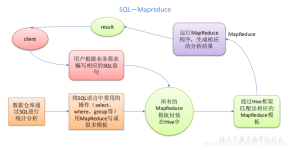
Hive 提供了一个让大家可以使用sql去查询数据的途径。让大家可以在hadoop上写sql语句。但是最好不要拿Hive进行实时的查询。因为Hive的实现原理是把sql语句转化为多个Map Reduce任务所以Hive非常慢,官方文档说Hive ...
Hive:启动Hive
问题遇到的现象和发生背景 在window启动hive 问题相关代码,请勿粘贴截图 启动hive 运行结果及报错内容 D:\ideaworks\apache-hive-2.3.0-bin\bin>hive SLF4J: Class path contains multiple SLF4J bindings....
Hadoop 框架是用于计算机集群大数据处理的框架,所以它必须是一个可以部署在多台计算机上的软件。部署了 Hadoop 软件的主机之间通过套接字 (网络) 进行通讯。Hadoop 主要包含 HDFS 和 MapReduce 两大组件,HDFS 负责...
指定hiveserver2连接的host。指定hiveserver2连接的端口号。
jdbc连接hive数据库的jar包.整理可用合集.
技术连载系列,前面内容请参考前面连载9内容:Hive底层数据存储在HDFS中,HQL执行默认会转换成MR执行在Yarn中,当HDFS配置了Kerberos安全认证时,只对HDFS进行认证是不够的,因为Hive作为数据仓库基础...
推荐文章
- cocos creator 实现截屏截图切割转成 base64分享--facebook小游戏截图base64分享,微信小游戏截图分享【白玉无冰】每天进步一点点_cocos上传base64-程序员宅基地
- Docker_error running 'docker: compose deployment': server-程序员宅基地
- ChannelSftp下载目录下所有或指定文件、ChannelSftp获取某目录下所有文件名称、InputStream转File_channelsftp.lsentry获取文件全路径-程序员宅基地
- Hbase ERROR: Can‘t get master address from ZooKeeper; znode data == null 解决方案_error: can't get master address from zookeeper; zn-程序员宅基地
- KMP的最小循环节_kmp求最小循环节-程序员宅基地
- 详解ROI-Pooling与ROI-Align_roi pooling和roi align-程序员宅基地
- Imx6ull开发板Linux常用查看系统信息指令_armv7 processor rev 2 (v7l)-程序员宅基地
- java SSH面试资料-程序员宅基地
- ant design vue table 高度自适应_对比1万2千个Vue.js开源项目发现最实用的 TOP45!火速拿来用!...-程序员宅基地
- 程序员需要知道的缩写和专业名词-程序员宅基地