生产环境实战spark (7)分布式集群 5台设备 Hadoop集群安装1,Hadoop 下载。下载地址:http://hadoop.apache.org/releases.html下载版本:hadoop 2.6.5 版本 hadoop 2.6.x版本比较稳定2,使用winscp工具上传到...
”生产实战spark“ 的搜索结果
#以下是spark的调优参数 #自动广播 spark.sql.autoBroadcastJoinThreshold="10485760" #spark sql shuffle并行度设置 spark.sql.shuffle.partitions="200" #自动广播超时时间 #spark.sql.broad...
今天到现在为止实战课程的访问量 从今天到现在为止从搜索引擎引流过来的实战课程访问量 互联网访问日志概述 为什么要记录用户访问日志 1)网站页面的访问量 2)网站的黏性 3)推荐 用户行为日志内容 用户...
近几年,随着互联网、物联网等新兴大数据的出现,人们对大数据的采集、处理、存储等相关技术面临着巨大的...而 Spark Streaming 为 Spark 提供了流式数据处理的功能,让开发者能够更加灵活地进行实时的大数据分析工作。
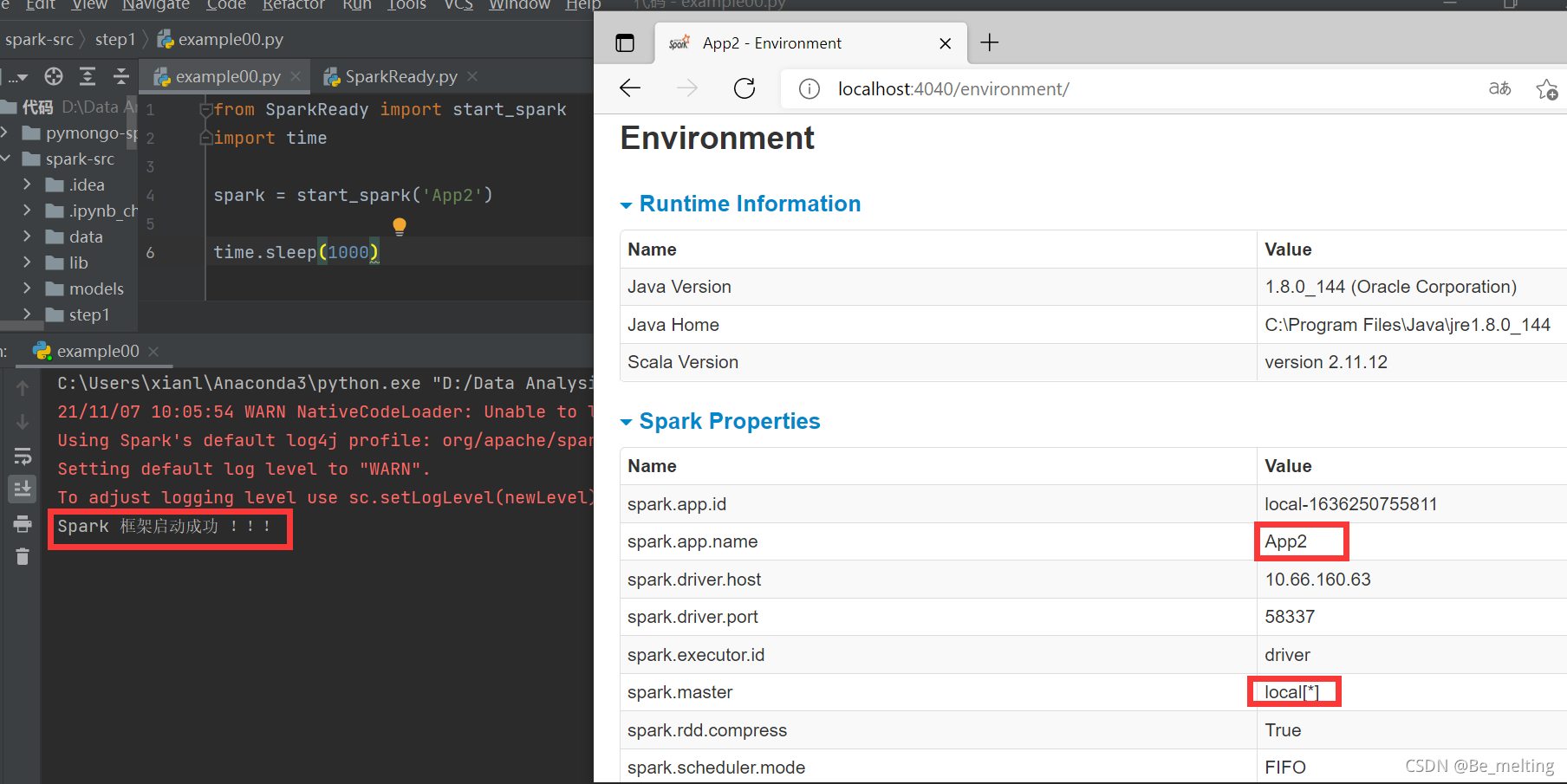
Standalone模式提交Spark应用的机器,Application(自己的Spark程序),spark-submit(shell)提交Application。Driver(启动一个进程),spark-submit使用Standalone模式提交Application的时候,其实会通过反射的...
在Spark中,DataFrame是一种以RDD为基础的分布式数据据集,类似于传统数据库听二维表格,DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。在Spark-1.3新加的最重要的新特性之...
你好,很高兴我们在《即学即用的 Spark 实战 44 讲》这个课程中相遇,我是范东来,Spark Contributor 和 Superset Contributor,同样也是《Spark 海量数据处理》与《Hadoop 海量数据处理》两本书的作者。 谈起...
基于spark的数据清洗与统计,以及Zeppelin的配置与使用
如何处理结构化数据:DataFrame 、Dataet和Spark SQL 本课时我们来学习如何处理结构化数据:DataFrame、Dataset 和 Spark SQL。由于本课时是专栏的第 3 模块:Spark 高级编程的第 1 课,在开始今天的课程之前,首先...
源于企业级电商网站的大数据统计分析平台,该平台以 Spark 框架为核心,对电商网站的日志进行离线和实时分析。 该大数据分析平台对电商网站的各种用户行为(访问行为、购物行为、广告点击行为等)进行分析,根据...

生产环境实战spark (2)Linux CentOS-7.0-1406-x86_64系统安装云平台不能开通公网测试,乌班图系统默认不带ssh,公网连不上,无法安装,后续也无法进行。不得己,更换操作系统,换了系统!更改为Linux的社区版本...
前言由于我司的系统已存在稳定的Hive on Hadoop集群以及Spark集群,随着业务发展,需要打通这两者,并能方便大家在其上进行开放,于是有了本文。本文实际是关于"Hive with Spark" 的,因为本文着重点在于阐述Hive与...

一、ZooKeeper集群搭建 (一)、集群部署的基本流程 下载安装包、解压安装包、修改配置文件、分发安装包、启动集群 (二)、ZooKeeper集群搭建 1、下载安装包 去官网下载zookeeper压缩包 ...
本文分为四个部分,基本涵盖了所有Spark优化的点,面试和实际工作中必备。《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优篇》《Spa...
参考文章:Spark Streaming 进阶实战五个例子 一、带状态的算子:UpdateStateByKey 实现 计算 过去一段时间到当前时间 单词 出现的 频次 object StatefulWordCount { def main(args: Array[String]): Unit = { ...
Spark技术内幕
标签: Spark 技术 内幕
Spark是不断壮大的大数据分析解决方案家族中备受关注的新增成员。它不仅为分布式数据集的处理提供一个有效框架,而且以高效的方式...本文最后以项目实战的方式,系统讲解生产环境下Spark应用的开发、部署和性能调优。
一、pom.xml文件中的依赖 <groupId>groupId</groupId> <artifactId>day142.0</artifactId> <version>1.0-SNAPSHOT</version> <properties> <.../...
Spark实战项目1-模拟网站流量分析与展示1、概述2、流程2.1、数据生成2.2、启动环境与创建Hbase表2.3、创建kafka的topic2.4、启动Flume2.5、创建Spark Streaming 项目2.6、创建S 1、概述 这是在学习spark过程中写的一...


阿里云/数据湖 Spark 引擎负责人周克勇(一锤)在 Streaming Lakehouse Meetup 的分享。
首先新建一个由maven管理的scala的项目 在pom文件中添加以下依赖 <properties> <scala.version>2.11.8</scala.version> <hadoop.version>2.7.4</hadoop.version>...spark.versio...
场景:通过Spark Streaming 拉取Kafka中的数据进行消费 (1)数据灌入kafka (生产者:代码如下) maven pom.xml配置如下 <?xml version="1.0" encoding="UTF-8"?> <project xmlns=...


Receiver整合 1.启动ZK cd /home/hadoop/app/zookeeper-3.4.5-cdh5.7.0/bin/ ./zkServer.sh start 2.启动kafka cd /home/hadoop/app/kafka_2.11-0.10.0.1/bin ./kafka-server-start.sh -daemon /home/...
电光石火间体验Spark 3.0开发实战 目录Spark新书介绍课程内容课程介绍课程链接 Spark新书介绍 添加链接描述 ...本书以数据智能为灵魂,以Spark 2.4.X版本为载体,以Spark+ AI商业案例实战和生产环境下几
推荐文章
- 记录nvm use node.js版本失败,出现报错: exit status 1: ��û���㹻��Ȩ��ִ�д˲�����_nvm use失败-程序员宅基地
- lua面向对象编程之点号与冒号的差异详细比较-程序员宅基地
- 百度云虚假下载_虚假新闻:关于公共云的5种常见误解-程序员宅基地
- Tesseract图像识别OCR的学习1_tesseract doocr-程序员宅基地
- 不同层级的Android开发者的不同行为,我们该如何进阶和规划?-程序员宅基地
- Pelee: A real-time object detection system on mobile devices-程序员宅基地
- Hadoop环境搭建(保姆级教学)_hadoop平台搭建步骤-程序员宅基地
- ZooKeeper实战之ZkClient客户端实现负载均衡_zookeeper实现负载均衡案例-程序员宅基地
- Android 枚举 VS 枚举注解_android 枚举注解-程序员宅基地
- HDU1715--第i个斐波那契数 大菲波数_返回第i个斐波那契数-程序员宅基地