源于企业级电商网站的大数据统计分析平台,该平台以 Spark 框架为核心,对电商网站的日志进行离线和实时分析。 该大数据分析平台对电商网站的各种用户行为(访问行为、购物行为、广告点击行为等)进行分析,根据...
”生产实战spark“ 的搜索结果
PySpark实战 大数据认知
一、Hive配置 (一)、简介 一般的公司都会有自己的数据仓库,而大多数都选择的Hive...极其耗时,因此使用spark来计算可以提高效率,但是之前有很多数据都是通过hive来操作,好在spark可以无缝集成hive,使用h...
【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送–Spark入门实战系列》获取 1、GraphX介绍 1.1 GraphX应用背景 Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图...
/todo:利用sparkStreaming对接kafka实现单词计数----采用receiver(高级API)//1、创建sparkConf.set(“spark.streaming.receiver.writeAheadLog.enable”,“true”) //开启wal预写日志,保存数据源的可靠性//2、创建...
本优化是生产环境下用Spark处理百亿规模数据的一些优化实战,并成功将程序的速度提升一倍(涉及到敏感信息本文在2018-07-04号将其删除,阅读上可能显得不完整)下面介绍一些基本的优化手段 本文于2017-07-16号书写 ...
使用Spark Streaming实时的分析处理用户对广告点击的行为数据1. 准备数据1.1 数据生成方式1.2 数据格式1.3 模拟数据生成及从Kafka中读取数据2. 需求一:每天每地区热门广告Top32.1 需求分析2.2 代码实现3. 需求二:...
Spark开发详细过程
将结合前述知识进行综合实战,以达到所学即所用。在推荐系统项目中,讲解了推荐系统基本原理以及实现推荐系统的架构思路,有其他相关研发经验基础的同学可以结合以往的经验,实现自己的推荐系统。 1 推荐系统简介 ...

Spark Strucutured Streaming提供了针对同一个数据源流进行不同逻辑计算并对结果进行不同的sink的方式。 这就是在Spark Strucutured Streaming的writestream中提供的foreach和foreachBatch接口。 Foreach
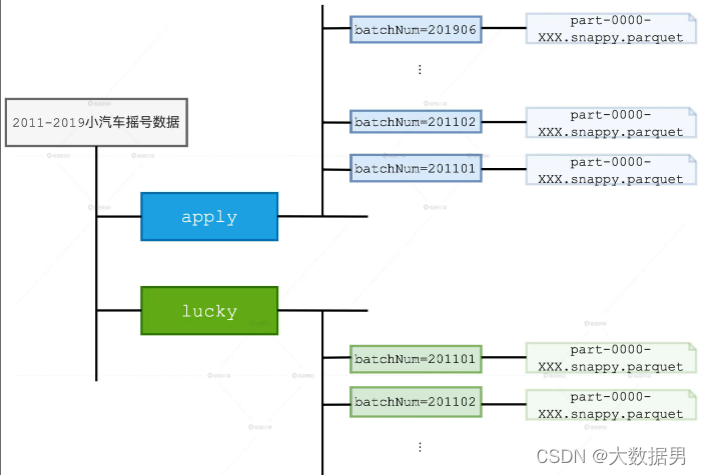

Spark实战— 电商指标统计 一、引言 在实战项目中,根据不同的需求进行编程,由于需求不同,核心的计算逻辑会不同,但是其他的一些代码,如获取环境变量、读取文件等等操作是固定。本次我们采用编写框架的模式来...
Spark是不断壮大的大数据分析解决方案家族中备受关注的新增成员。它不仅为分布式数据集的处理提供一个有效框架,而且以高效的方式...本文最后以项目实战的方式,系统讲解生产环境下Spark应用的开发、部署和性能调优。

物以类聚:Kmean 聚类算法 在开始之前,先来看看上个课时的思考题。在配置分类器时,我们需要设置的参数主要有: 树的个数; 树的最大深度;...在特征子集的选取策略中可以配置信息增益、信息增益率以及基尼系数。...
由于SparkStreaming一般是7*24不间断运行,所以强大的容错性保障是必不可少的。并且在保证容错的基础上,保证精准一次的数据处理同样是我们想要的。 checkpoint SparkStreaming自带的容错机制主要是通过...
写在前面2016年天猫双十一当天,零点的倒计时话音未落,52...天猫这个大屏后面的技术应该是使用流计算,阿里使用Java将Storm重写了,叫JStrom(https://github.com/alibaba/jstorm),最近学习SparkStream和Kafka,可以简
引用\[2\]:本书以数据智能为灵魂,以Spark 2.4.X版本为载体,以Spark+ AI商业案例实战和生产环境下几乎所有类型的性能调优为核心,对企业生产环境下的Spark+AI商业案例与性能调优抽丝剥茧地进行剖析。全书共分4篇,...
0.1 讲义文件源-json数据任务。按照讲义中json数据的生成及分析,复现实验,并适当分析。0.2 讲义kafka源,2字母单词分析任务按照讲义要求,复现kafka源实验。0.3 讲义socket源,结构化流实现词频统计。...

l 11.2 Spark与Alluxio整合原理与实战 11.2.1Spark与Alluxio整合原理 Alluxio,以前称为Tachyon,是世界上第一个内存速度虚拟分布式存储系统。它统一数据访问和桥接计算框架和底层存储系统。应用程序只需要连接...
文章目录一、前言二、KafkaUtils.createDstream三、KafkaUtils.createDirectStream 一、前言 首先,我们先来简单的了解下 Kafka:是一种高吞吐量的分布式发布订阅消息系统。依赖Zookeeper,因此搭建Kafka的时候需要...
kafka作为一个实时的分布式消息队列,实时的生产和消费消息,这里我们可以利用SparkStreaming实时计算框架实时地读取kafka中的数据然后进行计算。在spark1.3版本后,kafkaUtils里面提供了两个创建dstream的方法,一...
从零起步,分阶段无任何障碍逐步掌握大数据统一计算平台Spark,从Spark框架编写和开发语言Scala开始,到Spark企业级开发,再到Spark框架源码解析、Spark与Hadoop的融合、商业案例和企业面试,一次性彻底掌握Spark,...

Spark+Kudu的广告业务项目实战 1.简介 本项目需要实现:将广告数据的json文件放置在HDFS上,并利用spark进行ETL操作、分析操作,之后存储在kudu上,最后设定每天凌晨三点自动执行广告数据的分析存储操作。 2.项目...

推荐文章
- Pytorch Dataloader 模块源码分析(二):Sampler / Fetcher 组件及 Dataloader 核心代码-程序员宅基地
- Asp类型判断及数组打印-程序员宅基地
- Adroid Studio 2022.3.1 版本配置greendao提示无法找到_plugin with id 'org.greenrobot.greendao' not found-程序员宅基地
- esxi查看许可过期_解决Vsphere Client 60天过期问题-程序员宅基地
- CMake_cmake_module_path-程序员宅基地
- 生产者消费者模型-程序员宅基地
- Adaptive AUTOSAR 解决方案 INTEWORK-EAS-AP_autosar的eas-程序员宅基地
- 穿山甲SDK错误码40025_穿山甲sdk错误码4025-程序员宅基地
- css firefox下的兼容问题_css 只用于firefox-程序员宅基地
- 【Python】对大数质因数分解的算法问题_python分解多个质因数代码-程序员宅基地